'Network'에 해당되는 글 204건
- 2009.01.18 TCP Header 와 TCP 서비스의 특징 / UDP Header 와 UDP 서비스의 특징
- 2009.01.18 Congestion 이란 ? 그리고 언제 발생하나 ?
- 2009.01.18 Flow-Control 이란 ?
- 2009.01.18 Congestion-Control 이란 ?
- 2009.01.18 Loss-based Congestion-control & Delay-based Congestion-control
- 2009.01.18 Congestion Avoidance Only (Slow-start, Congestion-avoidance)
- 2009.01.18 TCP Tahoe (Fast-Retransmit, 1988 Van Jacobson - ACM SIGCOMM Congestion control and Avoidance)
- 2009.01.18 TCP Reno (Fast-Recovery, 1990)
- 2009.01.18 TCP greedy closed loop 성질과 credits
- 2009.01.18 QoS Protocol & Architectures 1

TCP 서비스의 특징
Connection-oriented : 실제 데이터를 전송 전에 syn packet (synchronizing) 을 통해서 연결되어야만 송수신이 가능하다.
Streaming : 데이터의 전송단위는 바이트이며, byte-oriented streaming 송수신이다.
Full-duplex : 송신과 수신을 동시에 할 수 있다
Reliable : 송신한 데이터에 대한 ACK (acknowledgement)를 통해 확인이 가능하다
End-to-end semantic : 중간 라우터나 네트워크를 고려하지 않고, 말단 노드간의 전송을 지향한다. (using congestion/flow control)
UDP Header 와 UDP 서비스의 특징

UDP 서비스의 특징
Connection-less
Datagram-oriented
Unreliable
Applications
Multiasting
Network management
Routing Table Update
Real-time multimedia
'Network > Netowrk_transport' 카테고리의 다른 글
| Retransmission Mechanism (0) | 2009.01.18 |
|---|---|
| TCP 와 UDP 의 차이점 (0) | 2009.01.18 |
| Congestion 이란 ? 그리고 언제 발생하나 ? (0) | 2009.01.18 |
| Flow-Control 이란 ? (0) | 2009.01.18 |
| Congestion-Control 이란 ? (0) | 2009.01.18 |
이러한 Congestion 상태는 두 가지의 경우에 발생할 수 있는데
굵은 PIPE에서 가는 PIPE로 이동하는 경우 ( LAN 환경에서 WAN 환경으로 옮겨가는 부근)
네트워크 상의 물리적인 전송량이 늘어서 허브나 라우터에서 허용한 용량이 초과한 경우
이 와 같이 단순히 end-to-end 간의 flow-control 만으로는 해결하기 힘든 문제를 TCP 서비스 상에서는 고려하고 있다. 이에 비해서 UDP를 보면 정말 무식한 놈 ... 이라는 생각이 드는 것이 당연할 지도 모르겠다.
'Network > Netowrk_transport' 카테고리의 다른 글
| TCP 와 UDP 의 차이점 (0) | 2009.01.18 |
|---|---|
| TCP Header 와 TCP 서비스의 특징 / UDP Header 와 UDP 서비스의 특징 (0) | 2009.01.18 |
| Flow-Control 이란 ? (0) | 2009.01.18 |
| Congestion-Control 이란 ? (0) | 2009.01.18 |
| Loss-based Congestion-control & Delay-based Congestion-control (0) | 2009.01.18 |
방법 : TCP sender 의 전송 rate 를 조절함
기법 : Sliding Window
적용 : Advertised Window 즉 (ACK로 수신된 TCP Header의 Receiver Window Size)
'Network > Netowrk_transport' 카테고리의 다른 글
| TCP Header 와 TCP 서비스의 특징 / UDP Header 와 UDP 서비스의 특징 (0) | 2009.01.18 |
|---|---|
| Congestion 이란 ? 그리고 언제 발생하나 ? (0) | 2009.01.18 |
| Congestion-Control 이란 ? (0) | 2009.01.18 |
| Loss-based Congestion-control & Delay-based Congestion-control (0) | 2009.01.18 |
| Congestion Avoidance Only (Slow-start, Congestion-avoidance) (0) | 2009.01.18 |
방법 : TCP sender의 전송 rate를 조절함
기법 : Slow-Start / Congestion Avoidance / Additive Increase Multiplicative Decrease (AIMD)
적용 : 송신시에 알리는 MSS (Maximu Segment Size) 및 기타 커널에서 관리하는 cwnd 값
'Network > Netowrk_transport' 카테고리의 다른 글
| Congestion 이란 ? 그리고 언제 발생하나 ? (0) | 2009.01.18 |
|---|---|
| Flow-Control 이란 ? (0) | 2009.01.18 |
| Loss-based Congestion-control & Delay-based Congestion-control (0) | 2009.01.18 |
| Congestion Avoidance Only (Slow-start, Congestion-avoidance) (0) | 2009.01.18 |
| TCP Tahoe (Fast-Retransmit, 1988 Van Jacobson - ACM SIGCOMM Congestion control and Avoidance) (0) | 2009.01.18 |
Loss-based Congestion-control & Delay-based Congestion-control
| Network/Netowrk_transport 2009. 1. 18. 18:10그와는 다르게 대기 시간을 기준으로 판단하는 TCP Vegas와 같은 방식을 delay-based cc라고 한다.
'Network > Netowrk_transport' 카테고리의 다른 글
| Flow-Control 이란 ? (0) | 2009.01.18 |
|---|---|
| Congestion-Control 이란 ? (0) | 2009.01.18 |
| Congestion Avoidance Only (Slow-start, Congestion-avoidance) (0) | 2009.01.18 |
| TCP Tahoe (Fast-Retransmit, 1988 Van Jacobson - ACM SIGCOMM Congestion control and Avoidance) (0) | 2009.01.18 |
| TCP Reno (Fast-Recovery, 1990) (0) | 2009.01.18 |
Congestion Avoidance Only (Slow-start, Congestion-avoidance)
| Network/Netowrk_transport 2009. 1. 18. 18:09또한 이렇게 현재의 Window Size * 2 만큼 증가하므로 ssthresh 값을 그의 절반인 값으로 설정하는 것도 어느정도 이해가 간다.
자료를 확인한 결과 유실되기 이전의 마지막 cwnd 값을 ssthresh 값으로 저장하게 되므로, 다음 cwnd 값이 2배로 증가하게 되어있었으므로 마치 1/2으로 줄어드는 것으로 생각할 수 있다.
Congestion-Avoidance : 현재 cwnd 크기가 ssthresh값에 도달하게 되면 cwnd 값을 지수승으로 증가시키지 않고 Linear 하게 1개씩 증가시킨다.
'Network > Netowrk_transport' 카테고리의 다른 글
| Congestion-Control 이란 ? (0) | 2009.01.18 |
|---|---|
| Loss-based Congestion-control & Delay-based Congestion-control (0) | 2009.01.18 |
| TCP Tahoe (Fast-Retransmit, 1988 Van Jacobson - ACM SIGCOMM Congestion control and Avoidance) (0) | 2009.01.18 |
| TCP Reno (Fast-Recovery, 1990) (0) | 2009.01.18 |
| TCP greedy closed loop 성질과 credits (0) | 2009.01.18 |
TCP Tahoe (Fast-Retransmit, 1988 Van Jacobson - ACM SIGCOMM Congestion control and Avoidance)
| Network/Netowrk_transport 2009. 1. 18. 18:09RTO (Retransmission Time Out)
3 Dupacks
Slow Start Phase ( 1개의 패킷 유실 )
Sender 가 1~8까지 전송을 완료한 다음 (어차피 모두 송수신 버퍼를 거치므로 단계별로 체크는 힘들다) , 1 번이 loss라고 가정함.
[ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] [ 7 ] [ 8 ]
Duplicate ACK을 버퍼에서 하나씩 체크하면서 2~4번 Dup-ACK 체크 시점에서 Fast-Retransmit [ 1 ]을 한다.
window size = 8, ssthresh = 4, cwnd = 1 (default)
현재 정상 ACK은 하나도 없고 cwnd는 1이므로 더 이상 전송이 불가능하다.
마 침 [ 1 ]에 대한 ACK을 수신하였다면 SS 단계이므로 2 개를 더 전송할 수 있게 된다. 여기서 8개를 전송하고 Dup-ACK 7개를 받았으므로 다른 패킷은 정상전송이라고 Cumulative-ACK을 적용할 수가 있으며 [ 9 ] [ 10 ] 을 전송할 수 있다.
windowSize (8), ssthresh (4), cwnd (1+1)
[ 9 ] [ 10 ]
해당 [ 9] [ 10 ] 번의 ACK을 정상 수신하면서 4개를 더 전송할 수 있게 된다.
windowSize (8), ssthresh (4), cwnd (2 + 2)
[ 11 ] [ 12 ] [ 13 ] [ 14 ]
Congestion Avoidance Phase ( 1개의 패킷 유실 )
전송 후에 ACK을 하나라도 받게되면 이제는 ssthresh 값을 cwnd 값이 초과하므로 CA단계로 옮겨지면서 cwnd 값도 1개씩 증가한다.
windowSize (8), ssthreash (4), cwnd (4 + 1)
[ 15 ] [ 16 ] [ 17 ] [ 18 ] [ 19 ]
Tips
가 장 오해하기 쉬운 부분이 SS 단계에서 windowSize가 8인데 더 보낼 수 있지 않냐고 생각할 수 있는데, 이는 잘못 생각하고 있는 것이며, flow-control 만을 고려할 것이 아니라 congestion-control 즉, 네트웍 상의 트래픽을 고려해야 하므로 windowSize 와 ssthresh 값 중에서 작은 것을 선택하여 전송하는 것이 맞다.
Slow Start Phase ( 2개의 패킷 유실 )
Sender 가 1~8까지 전송을 완료한 다음 (어차피 모두 송수신 버퍼를 거치므로 단계별로 체크는 힘들다) , [ 1 ] [ 3 ] 번이 loss라고 가정함.
[ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] [ 7 ] [ 8 ]
Duplicate ACK을 버퍼에서 하나씩 체크하면서 2, 4, 5번에 대한 Dup-ACK 체크 시점에서 Fast-Retransmit [ 1 ]을 한다.
window size = 8, ssthresh = 4, cwnd = 1 (default)
[ 1 ]번에 대한 ACK을 받게되었으나, 8개 보내고 총 6개의 Duplicate ACK을 받았으므로 전송측에서는 어디서 loss가 발생하였는지 정확히 판단할 수는 없다.
ssthresh (4), cwnd (1+1)
내 생각으로는 [ 2 ]~ [ 8 ] 어느 것이 유실되었는지 모르므로, 어떤 패킷을 재전송 해야하는지도 모른다. 결국 RTO가 발생할 때까지 기다리는 방법밖에는 없을 것이다. 그렇다면 ssthresh 값은 절반으로 줄게되고, cwnd 값은 1로 떨어진다. 단, 여기서 RTO의 의미는 congestion 이 발생했다고 받아들이면 될 것 같다.ssthresh (4/2), cwnd (1)
[ 3 ]
다시 처음부터 SS 단계로 접근하여 진행하면 된다..
Question
다른 자료에서도 TCP Tahoe에서는 Multiple-packet-loss에 대해서는 언급하지않는다고 되어있고 [ 4 ]번 단계에서 RTO를 발생시키는 것이 맞는지 정확하게 판단이 서지 않는다.
'Network > Netowrk_transport' 카테고리의 다른 글
| Loss-based Congestion-control & Delay-based Congestion-control (0) | 2009.01.18 |
|---|---|
| Congestion Avoidance Only (Slow-start, Congestion-avoidance) (0) | 2009.01.18 |
| TCP Reno (Fast-Recovery, 1990) (0) | 2009.01.18 |
| TCP greedy closed loop 성질과 credits (0) | 2009.01.18 |
| QoS Protocol & Architectures 1 (0) | 2009.01.18 |
RTO (Retransmission Time Out)
3 Dupacks
Stopping flow of moving packet and acks
지 속적으로 acks 계속 받는 다는 것은 한개 정도의 loss가 발생하여도 congestion은 아닐 것이라는 것을 가정한 것 같다 그래서 Fast-Recovery 단계에서 cwnd 의 크기를 조절할 때에 ssthresh + Dupacks 값으로 설정하여 빨리 복구하는 접근을 한다. 단, Partial-Ack를 사용하지 못하므로 Multiple-packet-loss 에서는 TCP Tahoe와 큰 차이가 없다는 점은 유의해야만 한다.
Slow Start Phase ( 1개의 패킷 유실 )
Sender 가 1~8까지 전송을 완료한 다음 (어차피 모두 송수신 버퍼를 거치므로 단계별로 체크는 힘들다) , 1 번이 loss라고 가정함.
[ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] [ 7 ] [ 8 ]
Duplicate ACK을 버퍼에서 하나씩 체크하면서 2~4번 Dup-ACK 체크 시점에서 Fast-Retransmit [ 1 ]을 하고, Fast-Recovery 단계로 이동한다
window size = 8, ssthresh = 4, cwnd = 1 (default)
Fast Recovery Phase ( ssthresh = cwnd / 2, cwnd = ssthresh +3Dupacks )
Recovi[ 2 ] [ 3 ] [ 4 ] Dupacks를 받은 시점에서도 받았다는 것 자체가 네트워크 상태가 그리 나쁘지 않다는 의미이므로, 해당 Dupacks를 의미있게 받아들여서 FastRecovery를 시도한다. 그리고 초기의 Fast-Retransmission에 대한 ACKs를 다 받게 되면 Fast-Recovery-Phase 가 종료되므로 CA로 이동
ssthresh (4), cwnd (4+3)
[ 9 ] [ 10 ] [ 11 ]
Congestion Avoidance Phase ( cwnd = ssthresh )
여기서는 다시 cwnd값을 ssthresh와 일치시키므로 [ 9 ] ~ [ 11 ]에 대한 ACK을 받기 전이므로 [ 12 ]만 보낼 수 있다.
ssthresh (4), cwnd (4)
[ 12 ]
Tips
다 시 생각해보니 이 부분도 좀 이상하다고 생각되며, TCP Reno의 장점은 Dup-ACK이 3개 발생되는 시점부터 Congestion Avoidance 단계로 이동하는 과정을 눈에 띄이게 향상시켰다는 점이 장점인 것 같다. 특히 패킷이 하나만 유실되었을 경우에만 그 차이를 확실히 알 수 있었다.
결국 Fast Recovery Phase 로 갈 수 있게되는 근거는 버퍼에서 해당 Dup-ACK 갯수를 파악하여 Single-Packet Loss임을 알기 때문에 FR이지 Multiple-packet-loss의 경우에는 TCP Tahoe와 별반 다를 바가 없다.
Slow Start Phase ( 2개의 패킷 유실 )
Sender 가 1~8까지 전송을 완료한 다음 (어차피 모두 송수신 버퍼를 거치므로 단계별로 체크는 힘들다) , [ 1 ] [ 3 ] 번이 loss라고 가정함.
[ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] [ 7 ] [ 8 ]
Duplicate ACK을 버퍼에서 하나씩 체크하면서 2, 4, 5번에 대한 Dup-ACK 체크 시점에서 Fast-Retransmit [ 1 ]을 하고, 수신된 Dup-ACK가 6개이므로 FR단계로 이동하지 못하고 SS 단계가 유지된다. TCP Tahoe와 동일하다.
window size = 8, ssthresh = 4, cwnd = 1 (default)
Duplicate ACK을 버퍼에서 하나씩 체크하면서 2, 4, 5번에 대한 Dup-ACK 체크 시점에서 Fast-Retransmit [ 1 ]을 한다.
window size = 8, ssthresh = 4, cwnd = 1 (default)
[ 1 ]번에 대한 ACK을 받게되었으나, 8개 보내고 총 6개의 Duplicate ACK을 받았으므로 전송측에서는 어디서 loss가 발생하였는지 정확히 판단할 수는 없다.
ssthresh (4), cwnd (1+1)
내 생각으로는 [ 2 ] 이 유실되었을 수도 있으므로 여기서는 [ 2 ] [ 3 ] 을 재 전송할 것이며, 해당 ACK을 기다릴 것 같다. 즉 이전의 Dup-ACK은 의미가 없을 수 있다 [ 2 ] ~ [ 8 ] 번 사이에서 어떤 패킷이 유실되었는지 알 수 없으므로 전부 재전송 하는 방법 외에는 없을 것으로 생각된다.
ssthresh (4), cwnd (2)
해당 [ 2 ] [ 3 ]에 대한 ACK이 도착하게되면 다시 Slow-Start와 동일한 상황이 발생하고
ssthresh (4), cwnd (2+2)
Congestion Avoidance Phase ( 2개의 패킷 유실 )
[ 4 ] [ 5 ] [ 6 ] [ 7 ] 을 재 전송하게되고 ACK을 받는데, ssthresh를 초과하여 CA단계로 넘어간다.
ssthresh (4), cwnd (4+1)
[ 8 ] [ 9 ] [ 10 ] [ 11 ] [ 12 ] 를 전송하게 되고 계속 진행된다
'Network > Netowrk_transport' 카테고리의 다른 글
| Congestion Avoidance Only (Slow-start, Congestion-avoidance) (0) | 2009.01.18 |
|---|---|
| TCP Tahoe (Fast-Retransmit, 1988 Van Jacobson - ACM SIGCOMM Congestion control and Avoidance) (0) | 2009.01.18 |
| TCP greedy closed loop 성질과 credits (0) | 2009.01.18 |
| QoS Protocol & Architectures 1 (0) | 2009.01.18 |
| IntServ DiffServ (0) | 2009.01.18 |
1. <!--[endif]-->when the MAC layer of the AP receives the marked packet, it updates the credits counter for increasing its access weight; and when enough credits are accumulated, its cw is multiplicatively decreased.
수업이 몇학점 짜리냐고 물어볼때 쓰는말이 credits이라고 한다.
한국말로 굳이 적용하자면.. 마일리지??? ㅎㅎㅎ
TCP의 greedy closed loop 성질은
burst 성질과 같은 것으로, ACK를 받아야 전송하는 closed loop의 성질에 입각해,
보낼 수 있는 양을 나눠서 적당하게 조절해서 보내는 것이 아니라, 보낼 수 있는 최대 양대로
전송하는 성질을 말하며
ACK를 받아야 전송하는 TCP의 성질을 셀프 클러킹 혹은 ACK 클러킹이라 한다.'Network > Netowrk_transport' 카테고리의 다른 글
| TCP Tahoe (Fast-Retransmit, 1988 Van Jacobson - ACM SIGCOMM Congestion control and Avoidance) (0) | 2009.01.18 |
|---|---|
| TCP Reno (Fast-Recovery, 1990) (0) | 2009.01.18 |
| QoS Protocol & Architectures 1 (0) | 2009.01.18 |
| IntServ DiffServ (0) | 2009.01.18 |
| diffserv (0) | 2009.01.18 |
QoS 프로토콜은 각 종단(end to end)의 데이터 배급(delivery)의 결정성을 가능하게 하기 위하여 상호 보완적인 다양한 메커니즘을 사용한다.
Scope of this document
이 논문의 목적은 인터넷 프로토콜(IP)기반의 네트워크에서 현재 유용하거나(available), 개발중인 Quality of Service 프로토콜을 소개하고, 그 개요를 살펴보는데 있다.
이러한 주제에 대해 개략적으로 소개한 뒤에 우리는 각각의 QoS 프로토콜이 어떻게 동작하는가에 대한 고차원적인 기술(Description)을 제공하고자 한다. 우리는 IP응용의 트래픽에 대한 종단간(end-to-end)의 QOS를 제공하기 위하여 정책적 관리(Policy Management)없이 상호간에 동작하는 많은 프로토콜들의 구조(architecture)에 대하여 고려하고, 마지막으로 IP multicast를 지원하고 외부적인 정책(explicit policy)을 지원하는 QoS의 상태에 대하여 간략히 기술하고자 한다.
Introduction
표준적인 인터넷 프로토콜(IP)을 지원하는 네트워크는 “best effort”한 데이터 배급(data delivery)를 기본적으로 제공한다. Best-effort IP는 복잡성(complexity)을 종단의 호스트(end-hosts)들에게 머물게 함으로써, 네트워크를 상대적으로 간단(simple)하게 유지한다. 이러한 스케일은 인터넷 그 자신이 놀랄 만큼 성장하는 능력으로써 증명되어 질 수 있다. 더 많은 호스트들이 연결되었을 때, 네트워크 서비스는 종종 용량을 초과하는 서비스 요구를 받게 되지만 그 서비스는 거절되지 않는다. 대신 서서히 성능이 저하 될 (degrade gracefully) 뿐이다.
변화 심한 delivery 지연(delivery delay – Jitter)과, 패킷의 손실에도 불구하고 전통적인 인터넷 응용 – e-mail, file transfer, 그리고 웹 응용 등 은 영향을 받지 않으나, 다른 응용에서는 일관된 서비스 수준에 적합하지 않다. Delivery 지연으로 인해 발생되는 문제는 실시간 요구(real time requirement)를 가지는 어플리케이션, 예로 멀티미디어를 deliver하거나, 최근의 요구 중 Telephony 와 같은 양방향 어플리케이션에서 발생된다.
대역폭(Bandwidth)을 증가 시키는 것이 이러한 실시간 어플리케이션에 적합하도록 하는 첫번째 단계가 되겠지만, 트래픽이 과중한(traffic bursts)동안의 jitter 문제를 회피하기에는 충분하지 않다. 설령, 상대적으로 부하가 덜 과중한 IP네트워크라 하더라도, delivery 지연은 이러한 실시간 어플리케이션을 지속하기에는 불리할 만큼의 변화를 가지고 있다. 알맞은 서비스 - 적정수준의 양적(quantitative)이며, 질적(qualitative)인 결정론(determinism) – 를 제공하기 위하여 IP서비스는 반드시 보완(보충)되어야 한다. 이러한 필요성 외에 jitter와 loss같은 지연(delay)으로부터 감내할 수 있는 엄격한 타이밍 요구를 분리하기 위해 추가적으로 망에 어떠한 ‘지능:smart/ intelligence’의 추가가 필요하다. QoS는 대역폭(Bandwidth)를 만들어내지는 않는다. 그러나, 그것을 관리하여 더 넓은 대역 [광대역(wide range)] 또는 어플리케이션의 요구사항을 만족 할 수 있도록 더욱 효과적으로 사용하는 것이다. QoS의 목표는 현재의 IP의 “Best-effort” 서비스 상황에서 적정 수준의 예측성(predictability)과 제어(control)를 제공하는 것이다.
어플리케이션 수요(Needs)의 다양성을 만족시키기 위하여 다수의 QoS 프로토콜들이 만들어져 왔다. 우리는 이 프로토콜들을 각각 설명할 것이며, 그런 다음 그것들이 어떻게 end-to-end principle 의 다양한 아키텍쳐 내에서 서로 적합할 것인가를 기술하고자 한다. 이러한 IP QoS 기술에 대한 도전은 개별적인 흐름(individual flow) 또는 프로세스 내에서 망을 분할 하지 않는 집단화(aggregate without breaking the Net) 에 대하여 Differentiated Delivery Service를 제공하게 되었다. 망에 ‘smarts’를 추가하고, “best effort”서비스를 향상시키는 것은 근본적인 변화를 표현하게 되었으며, 그것은 인터넷을 성공하게 만들었다. 이러한 잠재적으로 과감한 변화는 많은 인터넷의 구조(Internet’s architect)를 매우 nervous(신경과민의, 古간결한, 굳센)하게 만들었다.
이러한 잠재적인 문제점을 회피하기위한 QoS 프로토콜과 같은 것은 망에 적용되며, end-to-end 원칙은 아직까지도 QoS구조의 가장 주된 초점이다. 그 결과로 근본적인 원칙 “Leave complexity at the ‘edges’ and keep the network ‘core’ simple” 은 QoS 아키텍쳐 설계의 중심 개념이 되었다. 이것은 개별적인 QoS프로토콜 의 초점일 뿐만 아니라, end-to-end QoS사이에서 어떻게 함께 이용되어 질 수 있는가에 대한 것이기도 하다. 우리는 이러한 아키텍쳐들을 이 논문의 다음에서 찾아보고, 그 후에 QoS프로토콜들의 각각의 핵심을 간략히 소개하고자 한다.
The QoS Protocols
Quality Of Service는 한가지 이상의 방법으로 특징지어 질 수 있다. 일반적으로 QoS는 일관된 네트워크 data delivery 를 적정(어떤) 수준의 보증을 제공하는 네트워크 구성요소(e.g. an application, a host or a router)의 능력을 말한다. 어떤 어플리케이션들은 그들의 QoS에 대한 요구가 다른 것들에 비해 더욱 엄중하다. 이러한 이유로 우리는 QoS에 대하여 두 개의 기본형태를 가진다.
● Resource Reservation (integrated services): 네트워크 자원들이 어플리케이션의 QoS요청에 따라 배분되며, 대역폭 관리정책(Bandwidth management policy)이 중심이 된다
● Prioritization(differentiated service): 네트워크 트래픽들을 분류(classify)하며, 네트워크 자원들은 대역폭관리정책의 고려사항에 따라 분배된다. QoS를 가능케 하기 위하여, 네트워크 구성 요소들은 더 많은 요구를 받아들이기 위하여 이미 규정된 분류(classification)에 의하여 우선권이 주어진다.
이러한 형태의 QoS는 개별적인 어플리케이션 ‘flow’나 플로우의 집합에 제공되며, 따라서 QoS의 형태를 특징 짓는 또 다른 두 방법이 있게 된다.
● Per Flow: 하나의 ‘Flow’는 개별적인(individual), 단 방향의(uni-directional), 두 어플리케이션간의 데이터 스트림(sender 또는 receiver), 5-Tuple(transport protocol, source address, source port number, destination address, and destination port number) 에 의해 단일하게 규정되어지는 것으로 정의 된다.
● Per Aggregate: 하나의 aggregate는 간단히 두 개이상의 Flow를 말한다. 전통적으로 flow는 어떤 공통점을 가지게 된다. (e.g. 하나 이상의 어떤 5-tuple의 파라미터, 레이블이나 프라이오리티 번호, 또는 아마도 어떤 인증정보 등)
어플리케이션들, 네트워크 위상(topology)과 정책(policy)은 어떤 형태의 QoS가 각각의 개별적인 FLOW나 aggregate에 대하여 가장 적당한 것인지를 말하고 있다. 이러한 서로 다른 형태의 QoS에 대한 요구사항을 만족시키기 위하여, 많은 서로 다른 프로토콜과 알고리즘이 있다.
● ReSerVation Protocol (RSVP): 네트워크 자원을 예약하도록 하는 시그널링을 제공한다( 달리 Integrated Service로 알려져 있다). 전통적으로 per-flow 기반으로 사용되었지만, RSVP는 또한 aggregates에 대한 자원예약에도 사용된다.
● Differential Services(DiffServ): 네트워크 트래픽(flow) aggregates들에 대해 범위를 분류하며, 우선순위를 매기는 [조잡(coarse)하며]간단(simple)한 방법을 제공한다
● Multi Protocol Labeling Switching (MPLS): 패킷 헤더의 레이블(capsule)에 따른 네트워크 라우팅 제어(control) 를 통해aggregates에 대한 대역폭 관리(bandwidth management) 기능을 제공한다.
● Subnet Bandwidth Management(SBM): shared 또는 switched 된 IEEE 802 네트워크들에서 Layer 2(data link layer on OSI model)에 대한 범위분류(categorization)와 우선순위화(prioritization) 기능을 제공한다.

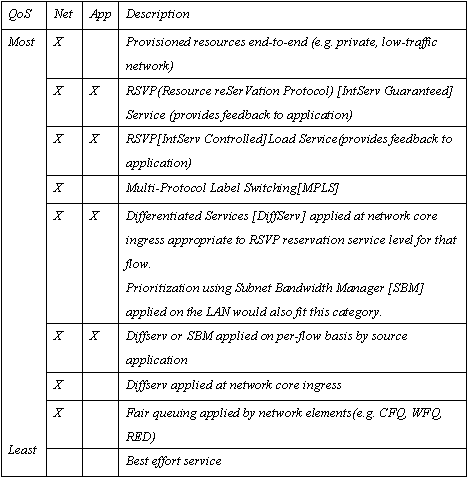
Table 1. Shows the different bandwidth management algorithm and protocols, their relative QoS levels, and whether they are activated by network elements (Net) or applications (App), or both.
표 1은 어플리케이션 (App) 또는 네트워크에서 QoS레벨과 그것들이 제공하는 구현된 서비스들에 대하여 QoS 프로토콜을 비교한 것이다. 이 표는 또한 Fair Queuing(FQ), Random Early Drop(RED)와 같은 라우터의 큐 경영 알고리즘(Queue management Algorithm)을 참조하고 있는 사실에 주목하여야 한다. 큐의 경영(queue management) – 큐의 개수와 그들의 depth 뿐만 아니라 그것들을 관리하는 알고리즘 까지를 모두 포함은 QoS 구현(implementation)에 있어 매우 중요한 것이다. 우리는 여기서 단지 그것들을 QoS 의 기능(능력)에 대한 전체적인 스펙트럼을 묘사할 뿐이다, 그러나 그것들은 어플리케이션에 대하여 매우 투명한 것이며 QoS 알고리즘에 명시적이지는 않으므로 우리는 그것들을 다시 다루지는 않을 것이다. 더 이상의 정보는 [Queuing]을 보라.
이 논문에서 우리가 초점을 두는 QoS 프로토콜은 매우 다양한 것이지만 그것들은 서로 상호 배타적인 것은 아니다. 다른 말로 하면 서로 훌륭히 상호 보완적이다. 이러한 프로토콜들이 상호 복수개의 서비스 제공자들을 통해 end-to-end QoS를 제공하기위해 다양한 아키텍쳐를 가진다. 우리는 이제 이러한 각각의 프로토콜들을 좀더 자세히 설명하고자 하며. – 그것들의 본질적인 구성과 기능들 - 뒤이어 그것들이 서로 end-to-end QoS를 제공하기 위해 사용되는 다양한 아키텍쳐에 대해 설명하고자 한다.
RSVP – Resource reservation
RSVP 프로토콜은 (자원)예약을 셋업하고 Integrated Service(IntServ)를 가능하게 제어하는 시그널링 프로토콜(signaling protocol)이다. 그것은 IP 네트워크 상에서 서킷-에뮬레이션 기능을 제공할 수 있도록 고려된 것 이다. RSVP는 모든 QoS기술들 중 가장 복잡한 것이며, 어플리케이션들 (hosts), 네트워크 구성요소(network element : routers and switches)들에 적용된다.
그러한 결과로 “best-effort” IP 서비스에 있어 가장 큰 부분으로 표현되며, 서비스를 개런티함에 있어 가장 높은 레벨의 QoS를 제공하여 주고, 자원의 할당을 세분화 시켜주고(granuallity) 어플리케이션과 유저에게 상세화 된 QoS 프로토콜을 제공하여 준다.
여기 어떻게 프로토콜이 작동되는 지에 대한 간략화 된 개략설명을 제공한다. 이것은 그림 1에 나타나 있다.

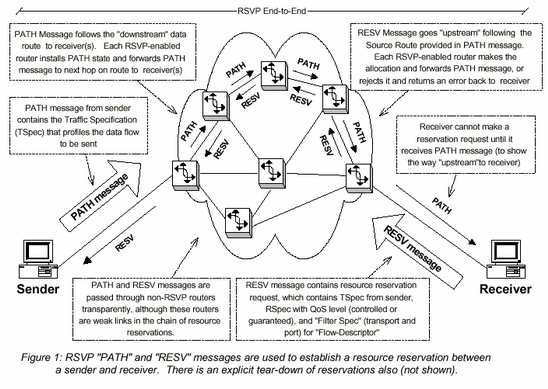
● 자원의 예약을 만들어 내기 위하여, 수신자(receiver)는 RESV(reservation request)메시지 “upstream”을 전송한다. TSpec에 추가적으로 RESV 메시지에는 Integrated Service – 또는 조정(제어 :controlled)/ 보증(Guranteed) 된 부하(load) - 에 필요한 형태를 지시하는 요구사양(request specification : Rspec)이 포함 되어 지거나, 예약이 만들어지는(e.g. 전송 프로토콜(transport protocol) 과 포트번호) 패킷들의 특성을 규정한 filter specification (filter spec)을 포함한다. 이들 RSpec과 filter Spec 은 라우터에서 각각의 예약들을 규정하기 위해 사용되는 flow-descriptor 에 의해 표현되어진다. (a.k.a., a “flow” or a “session”)
● 각각의 RSVP라우터가 upstream 경로에 따라 RESV메시지를 수신하였을 때, 그것은 요청된 그리고 할당될 필요한 자원에 대한 인증을 위하여 진입제어 처리(admission control process) 에 이용된다. 만일 그 요청이 만족스럽지 못하다면(cannot be satisfied : 자원이 부족하거나 인증에 실패하는 경우) 라우터는 수신자에게 오류(error)을 회신하게 된다. 만일 받아들여 졌다면, 라우터는 RESV upstream을 다음 라우터에 전송한다.
● 마지막 라우터가 RESV 메시지를 수신하고 요청을 받아들인다면 확인 메시지(conformation message)을 수신측에 회신한다(note: 마지막 라우터란 송신측의 cloest 이거나 멀티캐스트-플로우에 있어 예약 병합점(reservation merge point)을 뜻함)
● 전송측과 수신측이 RSVP세션을 종료하게 될 때, 예약(reservation)에 대한 한 가지의 명시적(explict)인 tear-down(분해/해체) 처리가 있다.
RSVP는 통합된 서비스(Integrated Service)를 가능하게 하며, 근본적으로 다른 두 가지 형태가 있다.
● Guaranteed : 이것은 마치 폐쇄된 전용의(dedicated) 가상 망(virtual circuit)을 에뮬레이션(emulation)할 수 있도록 한다. 이것은 경로(path)안의 다양한 네트워크 구성요소들로부터 파라미터를 조합하여 end-to-end 큐-잉 지연(queuing delay)의 확고한 범위를 제공(수학적으로 증명할 수 있다)한다. 더 나아가서 Tspec 파라미터[IntServ Guaranteed] 에 따라 대역폭(bandwidth)의 가용성(availability)을 보증할 수 있다.
● Controlled Load : 이 것은 “Best effort service under unloaded service : 부하가 없는 서비스하에서 Best effort 서비스”와 같다. 따라서 “better than best-effort service: best-effort 서비스보다 낫다”이지만, 보증된 서비스 약속에 대한 엄격히 제한된 서비스를 제공하지는 못한다.
Integrated Services들은 그들의 입/출력 큐잉-알고리즘을 특징화(규정화: characterize)하기 위하여 Token-Bucket 모델을 사용한다. 하나의 토큰-버킷(token-bucket)은 큐잉-되는 트래픽의 흐름을 유연하게 하기 위해 설계 되었으나 Leaky-Bucket 모델(이것은 또한 Out-flow 를 유연하게 한다)과는 유사하지 않다. 토큰-버킷 모델은 데이터-버스트(data-burst)를 허용한다 – 짧은 기간동안 높은 전송률을 가짐
하나의 RSVP세션에 대한 데이터-플로우 는 전송측의 PATH 메시지에 포함된 TSpec(Traffic Specification)에 의해 규정 지어지며, RSPEC(reservation specification)에 복사되어져 (mirrored) 수신측의 RESV 메시지에 의해 보내어 진다. 토큰-버킷 파라미터들 – bucket-rate, bucket depth, and peak rate – 들은 TSpec과 RSpec의 일부가 된다. 여기서 완전한 파리미터에 대해 설명한다.[RSVP IntServ, InterServ parameters, IntServ Controlled]
Guaranteed 와 Controlled Load Service 모두는 non-conforming Traffic (out-of-spec)으로서 best-effort 트래픽의 non-QoS와 같이 간주된다.
● Token rate ( r ) : 한 플로우에 대한 연속적으로 제공되는 대역폭(bytes/second)에 대한 요구사항. 이 것은 bucket 에 들어가는 평균 데이터비율(average data rate)과 목적지(target)에서의 bucket 의 출력되는 데이터비율로 만들어진다
● Token-bucket depth ( b ) 짧은 시간의 기간동안 감당해 낼 수 있는 초과 될 수 있는 데이터 비율에 대한 크기/익스텐트(extent). 더 정확히 말해서 보내지는 데이터는 rT+b를 초과 할 수 없다(T는 어떤 Time period를 말함)
● Packet rate ( p ) : 알려져 있거나 제어가 된 경우(Known and controlled) 최대 전송률(maximum send rate : bytes/second)를 지정하며, 또는 알려지지 않은 경우 무한대의 양수(RFC 1832의 기술방법처럼 부동소수점 값으로 표현 : 255.000…0)를 가진다. 모든 Time period T에 대하여 전송되는 데이터는 M+pT를 초과할 수 없다
● Minimum Policed size ( m ) : 전송 어플리케이션에서 생성(generated)되는 가장 작은 패킷의 크기 (byte)를 말한다. 이것은 절대적인(고정되어 있는) 값은 아니다. 그러나 작은 패킷들의 퍼센테이지 값이 작다면, 이 값은 이 플로우의 평가(estimate : reservation acceptance에 영향을 끼치게 된다) 오버헤드를 삭감하기 위하여 증가되어져야 한다. 모든 패킷이 m 보다 작다면 m으로 간주되며 그것에 따라 조절되어진다
● Maximum Packet size ( M ) : 가장 큰 패킷의 크기(byte)이다. 이 숫자는 고정되어진(절대적인) 숫자로 고려되어지며 따라서 이보다 큰 크기를 가지는 어떤 패킷도 spec이외로 간주되며 결과적으로 QoS제어하에서는 수신되지 못한다
예약사양(Reservation specification)과 트래픽에 대한 우리의 설명 중 에서, 우리는 다른 RSVP과 Integrated Service 기능에 대한 상세한 설명을 생략 하였다. 그것들은
1) PATH 메시지의 ADSpec은 Downstream 경로에 있는 데이터 소스나 어떤 또는 모든 네크워크 노드에서 만들어지는 정보(service, delay, bandwidth estimates등)을 포함한다
2) 하나의 reservation 이 어떻게 다른 그것들과 대화(상호작용)하는지를 다루는 예약의 형태(reservation style)
3) 이질적인 수신자(recevers)들에 대한 계층적인 해석시그널에 사용되는 “sub-flow”에 대한 규정화(characterize)를 허용하는 Filter-spec에 대한 예시
4) 자원 예약 정책 결정에 사용되는 자세한 상태정보를 제공하는 Policy data
여기서 RSVP 프로토콜의 메커니즘들의 더욱 현저한 특징들에 대한 요약을 하자면:
● 각각의 라우터에 대한 예약(reservation)은 “soft”하며, 이것은 수신자(들)(receiver(s))에 의해 주기적으로 refresh 되어져야 한다는 것을 의미한다.
● RSVP는 전송계층(transport)이 아니다. 그렇지만 하나의 네트워크(control) 프로토콜이다. 예를 들어 그것은 데이터를 수송(carry)하지는 않지만 TCP나 UDP 데이터의 “flow”에 대하여 동시에 작용한다.
● 어플리케이션들은 플로우의 요구사항을 규정하기 위한 API들을 필요로 하며, 예약 요청(Reservation request)을 기동(initiate)하고, 최초의 요청(initial request)과 하나의 세션을 통하여 예약이 성공되었는지 실패하였는지에 대한 확인을 수신한다. 이를 유용하게 하기 위하여는 이러한 API들은 예약이 셋-업 되는 동안 또는 조건의 변화와 같은 예약의 유효기간(Life time) 동안의 실패(failure)를 설명하기 위하여 RSVP 오류 정보들이 또한 포함될 필요가 있다.
● 예약(reservation)은 수신측 기준(receiver-based)이다. 이것은 대량의 이질적인(heterogeneous, multicast) 수신자그룹에 적합하게 하기 위함이다.
● Multicast 예약(reservation)은 그것들의 upstream 경로에서 트래픽이 복제되는 시점에 있어서는 “merged”된 것이며, 이로 인해 예전에는 잘 이해되지 못했던 매우 복잡한 알고리즘[RSVP Killer]을 필요로 하게 된다. 우리는 Multicast 를 지원하는 QoS란 주제에 대하여 이 논문의 다음에서 더 자세히 논의 할 것이다.
● RSVP 트래픽이 non-RSVP라우터를 운행할 수 있다 하더라도 이것은 QoS체인에서 약한 연결”weak-link”을 만들어내게 되며 그 곳에서의 서비스는 “best effort”수준으로 떨어지게(fall-back) 된다. (i.e. 이러한 link 에서는 자원할당이 없게 된다).
● RSVP 프로토콜 에는 두 가지 형태가 있다. Native RSVP는 하나의 IP프로토콜 번호 46(한 IP헤더의 프로토콜 필드)를 가지며 RSVP헤더와 탑재내용(payload)은 (raw) IP헤더 그 자신이 된다. UDP-encapsulated RSVP는 헤더를 UDP 데이터그램에 포함한다. 802 “Subnet Bandwidth Manager”는 단지 Native RSVP를 지원하는 부분만 이 논문의 나중에서 설명할 것이다.
앞서 고려되었던 것처럼 RSVP는 높은 수준의 IP QoS를 가능하게끔 제공한다. 이것은 어플리케이션이 높은 수준의 granularity의 가지는 QoS를 요청할 수 있게 하며, 서비스 공급 (service delivery)에 대한 최상의 보증을 가능하게 한다. 이 말은 매우 멋진 것이며 우리가 어떤 것을 필요로 하는지 아닌지에 대한 우려를 가지지 않게 한다. 그 이유는 복잡도와 오버헤드에 대한 가치를 부여해 주며 따라서 많은 어플리케이션들과 네트워크의 어떤 부분에 있어 필요 이상의 것이 될 수 있기 때문이다. 더 간단히 말해서 더 소량의 fine-tuned methods가 필요하며 그것은 이제 설명 할 DiffServ 가 제공하는 것이 된다.
DiffServ – Prioritization
차별화된 서비스(Differentiated Service) 즉 [DiffServ]는 다양한 어플리케이션들의 서비스를 분류하는(classifying) 간단하고 조잡한(coarse) 방법이다. 다른 것들이 가능하다 하더라도 두 개의 서비스 수준(traffic class)을 효율적으로 표현하는 두 개의 표준 PHB(Per hop behaviors) 로 정의 된다.
● Expedited Forwarding (EF) : 단일한 codepoint(DiffServ 값)를 가진다. EF는 지연(delay)과 변화(Jitter)를 최소화 시키며 가장 높은 수준의 aggregate 서비스 품질을 제공한다. 로컬하게 규정된 트래픽 프로파일(traffic profile)을 초과하는 어떤 traffic 도 무시된다.
● Assured Forwarding (AF) : 4개의 class 를 가지며, 각 클래스 에는 3개의 드롭-우선순위(drop precedence)가 있다. 따라서 전부 12개의 codepoiont가 있다. AF 트래픽을 초과하는 것은 delivery 되지 않을 가능성이 높다. 이것은 등급이 떨어진다는 뜻이며 drop되어질 필요는 없는 것이다.
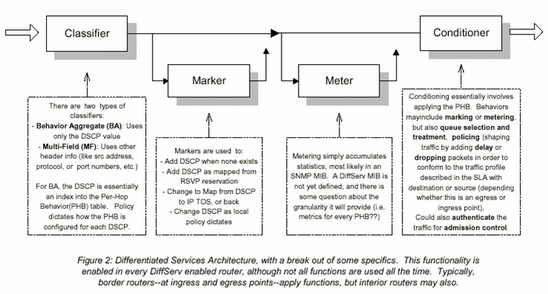
< 그림 2 >
그림 2에 묘사된 대로 PHBs들은 사전 정의된 정책 결정요소에 따라 트래픽의 소통을 위하여 네트워크 진입점(network ingress point : network board entry)에서 적용된다. 트래픽은 이 점에 서 마크 되어지며 그 마킹에 따라 라우트된다. 그런 다음 네트워크 출구(egress : noetwork board exit) 에서 Unmark 되어진다. 호스트로부터 시작되어지는 것 또한 DiffServ 마킹이 적용되어 질 수 있으며, 그렇게 함으로써 많은 장점을 취할 수 있게 된다.
DiffServ 는 하나의 보더를 공유하는 네트워크 사이에 SLA(Service Level Agreement)로 존재하는 것으로 가정한다. SLA는 정책결정요소를 수립하며 트래픽 프로파일(traffic profile)을 정의한다. 그것은 네트워크 진출점(egress point)에서 SLA에 따라 조절되어지고(Policed) 유연해 지기(smoothed)를 기대하는 것이며, 진입점(ingress)에서 “out of profile”한 어떤 트래픽(i.e. SLA에 정해진 대역폭의 상위 범위를 초과하는 트래픽 따위)들도 guarantee를 가지지 못하도록 하는 것이다. 사용되는 정책결정요소(Policy criteria)에는 time of day, 송신측, 수신측 주소, 트랜스포트, 그리고/또한 포트번호 등이 포함될 수 있다. 기본적으로 어떤 context나 traffic 의 내용(헤더나 데이터에 포함되어진)이 정책을 적용하는데 이용될 수 있다.
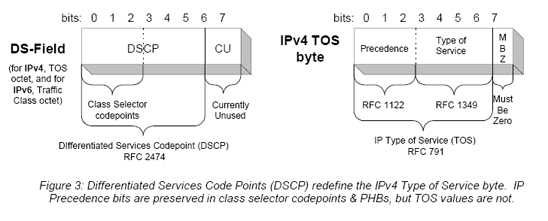
이것을 적용할 때 서비스에서 사용되는 프로토콜 메커니즘은 “DS-byte”에 있는 비트-패턴(bit pattern)이며, IPv4에서는 TOS(Type Of Service)옥텟이며 IPv6에서는 Traffic Class Octet이 된다.
그림 3에 묘사 된 대로 DS 필드가 , IPv4 TOS바이트를 사용한다 하더라도 RFC 791에 규정된 대로[IP], RFC1349[TOS]에서 정한 원래의 IPv4 TOS 비트 값을 보존하지 않는다. 그러나 IP 우선순위 비트(precedence bits : 0-2)들은 보존된다. 이러한 영역의codepoint에 어떠한 PHB를 assign 하는 것이 가능하다 할 지라도, 묵시적으로 필요한 PHB들은 RFC1812[RouterReqs]에서 기술된 것 처럼 IP Precedence service description 과 동등한 것이다.
트래픽을 순서화하는 DiffServ의 간결성(simplicity)은 그것의 유연성(flexibility)과 성능(power)에 있어 나타난다.
DiffServ가 RSVP의 파라미터를 사용하거나 CBR(Constant-Bit-Rate)을 규정하고 분류하기 위하여 특정한 어플리케이션의 형태를 사용하는 경우 고정된 대역폭 통로(fixed bandwidth pipe)로 보내기 위하여(direct) 잘-정의된 aggregate flow를 설정하는 것이 가능해 진다. 그 결과 자원을 효율적으로 공유할 수 있으며, 보증된 서비스를 지속적으로 제공할 수 있게 된다. 우리는 이러한 형태의 활용을 나중에 다룰 것이며, 가능한 형태의 다양한 QoS 아키텍쳐를 설명하고자 한다.
[출처] QoS Protocol & Architectures 1|작성자 레베로프
'Network > Netowrk_transport' 카테고리의 다른 글
| TCP Reno (Fast-Recovery, 1990) (0) | 2009.01.18 |
|---|---|
| TCP greedy closed loop 성질과 credits (0) | 2009.01.18 |
| IntServ DiffServ (0) | 2009.01.18 |
| diffserv (0) | 2009.01.18 |
| ACK (0) | 2009.01.18 |