저자: 한동훈(traxacun)
이 글은 리눅스 커널을 처음 공부하는 분들에게만 적합하며, 이미 잘 알고 계시는 분들에게는 적합하지 않을 수도 있습니다. 본 기사에서는 다음 주제들을 다룰 것입니다.
1. Memory Model
2. i386 CPU에서의 메모리 관리
3. 리눅서 커널에서의 메모리 관리
4. 커널에서의 코드
메모리 모델
예를 들어서, 1M 메모리를 가진 시스템이 있습니다. 이 시스템에서 메모리를 300k 사용하는 프로그램 A가 있고, 500k를 사용하는 프로그램 B가 있습니다. 그런데, 프로그램 A는 데이터가 많아질수록 더 많은 메모리를 사용하게 되어 있어서 600k의 메모리를 사용하게 되었습니다. 이런 경우에는 메모리가 프로그램 A와 B가 서로 충돌하게 되어 더 이상 프로그램을 실행할 수 없게 될 것입니다. 프로그램을 작성하면서 계산기 프로그램이 내 프로그램의 메모리 영역을 침범하면 안되는데라고 고민하면서 프로그램을 작성하지는 않을 것입니다. 이와 같이 다양한 프로그램들이 메모리를 사용할 수 있게 하기 위해 OS는 메모리를 관리합니다.
http://network.hanbitbook.co.kr/view.php?bi_id=1113
메모리 모델의 종류
메모리를 관리하는 방법은 세그먼트(Segment) 기법과 페이징(Paging) 기법이 있습니다. 우리가 흔히 보는 책은 페이지를 매기는 방법이 두 가지가 있습니다. 예를 들어, 1,000 페이지짜리 책이 있을 때 페이지를 1번부터 1,000번까지 모두 매겨놓은 책이 있는가하면, 책을 챕터별로 나누어서 각 챕터에서 몇번째 페이지라고 표기하는 방법이 있습니다. 선형적으로 일괄되게 페이지를 매기는 방법을 페이징이라 하고, 각 챕터별로 책을 나누고, 챕터에서 몇번째 페이지(Offset)라고 나누어 관리하는 방법을 세그먼트라고 합니다.
현대 운영체제는 정확하게 세그먼트와 페이징으로 나누어 관리하기 보다는 이 두가지를 적절하게 혼합된 형태를 사용합니다.
여기까지는 메모리를 관리하는 방법을 이론적으로 나눈 것이고, CPU에서 메모리를 관리하는 것은 다릅니다. 즉, OS에서 메모리를 관리하는 방법은 OS를 제작하는 사람이 마음대로 정할 수 있는 것이지만 실제로 CPU와 데이터를 주고 받을 때는 CPU에 맞춰서 데이터를 주고 받아야 합니다. 우리가 사용하는 x86 CPU는 리얼 모드(Real Mode)와 보호 모드(Protected Mode)를 사용합니다. 리얼 모드는 예전에 도스(DOS)를 사용하던 시절에 사용하던 모드로 1M 까지의 메모리를 사용할 수 있습니다. 보호 모드에서는 메모리를 0-4G까지 사용할 수 있습니다. 요즘에는 모두들 512M 이상의 램을 장착해서 사용하는 것이 보편적이니 리얼 모드는 몰라도 되지 않아라고 생각할 겁니다. 그러나, 시스템이 처음 전원이 들어가고, 부팅이 될 때는 리얼 모드로 실행되고, 그 이후에 보호 모드로 넘어가게 됩니다. 그렇게 때문에 커널을 학습하는 사람들은 CPU에서 메모리를 관리하는 방법이 리얼 모드일때와 보호 모드일 때 다르다는 것을 알아야 합니다. 이에 대해서는 뒤에서 보다 자세히 설명하도록 하겠습니다.
커널의 메모리 모델
리눅스 커널이 생각하는 메모리 모델은 크게 두 가지 뿐입니다. 하나는 물리 메모리(Physical Memory)이고, 다른 하나는 가상 메모리(Virtual Memory)입니다.
많은 분들이 들어보았을 이야기는 프로세스 하나당 4GB까지의 메모리 공간을 가진다는 것입니다. 즉, 스타크래프트도 4GB의 메모리 공간을 사용한다고 생각하고, 인터넷 익스플로러도 4GB의 메모리 공간을 사용한다고 생각합니다. 잠깐만요! 저는 PC에 램이 512M 밖에 없는데요? 라고 생각할 수 있습니다.
잠시 생각하면 알 수 있는 것처럼 모든 프로그램은 4G라는 메모리를 모두 사용하는 것이 아닙니다. 실제로는 매우 작은 일부만 사용할 뿐입니다. 그러니 사용하지 않는 부분은 무시하고, 사용하는 부분만 메모리에 갖고 있으면 됩니다.
프로세스는 4G의 공간이 전부 자기것이라고 생각하고, OS는 프로세스가 실제로 사용하는 부분만 실제 메모리에 올려놓으면 됩니다. 즉, 가상 공간과 실제 메모리 공간을 연결할 수 있는 변환 테이블이 하나 있으면 되겠네요!

그림1. 프로세스 A의 가상 공간과 실제 메모리
그림에서 볼 수 있는 것처럼 프로세스 A는 페이지 1, 4, 7번을 사용하고 있습니다. 그리고 이들 각각은 실제 메모리 프레임 5, 3, 1에 저장되어 있습니다. 이와 같은 방법을 사용하기 때문에 각 프로세스는 각자가 4G의 공간을 사용하고 있다고 생각하고, 다른 프로그램이 사용하는 메모리 공간에 대해 염려하지 않고 프로그램을 작성할 수 있는 것입니다.
x86 아키텍처의 메모리 모델
CPU는 연산을 위해 메모리와 데이터를 주고 받습니다. 즉, CPU가 메모리를 어떻게 이용하는지 알고 있어야합니다. CPU마다 메모리를 이용하는 방법은 각기 다르지만, 여기서는 가장 흔하게 사용되는 x86 CPU에 대해서 살펴볼 것입니다.

그림2. x86 CPU의 메모리 모델
x86 CPU는 32bit 환경이라고 얘기합니다. 즉, 메모리도 32bit에 해당하는 2의 32승 = 4G까지 사용할 수 있습니다. 각 페이지를 4096 바이트로 나누어서 관리하고 있습니다. 즉, 2^12 = 4096입니다. 따라서, 12 비트는 각 페이지의 위치를 가리키기 위해서 사용됩니다.
4G의 공간을 4096 페이지 크기로 나누면 1,048,576이고, 이 숫자의 의미는 4G의 메모리 공간을 4k 크기의 페이지로 나누어 관리하기 위해서는 페이지 테이블이 1,048,576개나 필요하다는 의미가 됩니다. 즉, 2^20 = 1,048,576이고, 1개의 PTE는 4 바이트이기 때문에 페이지 테이블이 차지하는 메모리의 크기는 1,048,576 * 4 = 4M가 됩니다. 즉, 하나의 프로세스가 4G의 메모리 공간을 관리하는 페이지 테이블을 유지하기 위해서는 4M가 필요하다는 것입니다. 프로세스 1개 생성에 4M를 무조건 사용한다는 것은 꽤나 큰 낭비입니다.
20 bit table인 경우: 2^20 = 1,048,576 = 1M
1M * 2^12(4096) = 4G
PTE = 4 bytes, 1M * 4 = 4M each process
그렇다면, 20비트를 한꺼번에 이용하는 대신에 10비트씩 나누어서 사용하면 어떨까요?
2의 10승은 1024개이고, 한 항목은 4 바이트를 차지하므로 1024 * 4 = 4096 = 4k를 사용하게 되고, 4k는 메모리에서 1 프레임만 차지합니다.
그래서 그림2와 같이 페이지 디렉토리에 10비트, 페이지 테이블에 10비트를 사용합니다.
Page Directory = 1024개 * 4 bytes = 4k = 1 page
Page Table = 1024개 * 4 bytes = 4k = 1 page
간단하게 C언어의 정의대로 적어보면 다음과 같습니다.
unsinged int table[1024*1024];
unsigned int directory[1024], table[1024];
첫번째는 20비트를 사용했을 때의 배열 선언이고, 두번째는 10비트씩 나누어서 디렉토리, 테이블로 사용할 때의 선언입니다. 물론, 리눅스 커널의 선언이 이렇게 되어 있다는 것은 아닙니다.
첫번째 배열 선언이 차지하는 크기를 생각해보면 4M이고, 두번째 배열 선언이 차지하는 크기는 8k입니다.
0xC1234567이라는 논리 주소가 주어졌을 때 실제로 CPU에서 어떻게 실제 메모리를 찾아가는지 살펴보겠습니다.

그림3. 논리 주소
0xC1234567이라는 16 진수를 2진수로 풀어서 쓰면 11000001001000110100010101100111이며, 이를 각각 10, 10, 12 비트씩 끊으면 위 그림과 같다.
그림2에 나온 것처럼 CPU에는 CR3 레지스터가 있으며, 이 레지스터는 메모리 관리를 위한 페이지의 출발지 정보를 갖고 있다. 따라서 CR3 레지스터의 값을 읽어서 페이지 디렉토리가 시작하는 위치를 알아내고, 상위 10비트
2256위치에서 읽어들인 값이 0x40000이고, 오프셋의 값이 1383이면 실제 메모리 주소의 위치는 0x41383이 된다.
리눅스 커널의 메모리 모델
리눅스 커널은 64비트 선형 주소를 사용한다. 커널에서 64비트 주소를 사용하는 이유는 Alpha CPU와 같이 64비트 주소를 사용하는 시스템을 지원하기 위해서이다.

그림4. 리눅스 커널의 메모리 모델
리눅서 커널도 x86 CPU와 마찬가지로 메모리 관리의 효율성을 위해 페이지 디렉토리를 글로벌 디렉토리와 미들 디렉토리로 나누어서 관리한다. 즉, x86 CPU에서 2단계 페이징을 사용한다면 커널에서는 3단계 페이징을 사용하는 것이 차이점이다.
글로벌 디렉토리는 pgd_t, 미들 디렉토리는 pmd_t, 페이지 테이블은 pte_t로 나타내며, 오프셋은 상대위치이기 때문에 따로 나타낼 필요는 없다.
x86에서는 2단계를 사용하고, 리눅스 커널에서는 3단계를 사용한다면 커널은 x86 환경에서는 어떻게 해야할까? x86 CPU를 지원하기 위해 별도로 2단계 페이징을 만들어야 할까? 라고 생각할 수 있는데 실제로 커널은 위 구조를 그대로 유지하면서 2단계 페이징을 지원하는 방법을 택했다. 즉, 미들 디렉터리를 1개만 사용하는 것이다. 이렇게 하면 커널의 코드를 크게 변경하지 않으면서 64비트 환경과 32비트 환경을 쉽게 지원할 수 있다.
각 시스템마다 메모리 관리를 위해 사용하는 비트수는 다르기 때문에 위 그림에서 몇 비트씩 사용하는지 명시하지 않았다. 물론, 특정 플랫폼마다의 비트수를 적는다면 적을 수 있지만 여기서는 그렇게 하지 않았다.
x86 CPU와 커널에서 메모리를 찾는 방법을 보면 먼저 CR3 레지스터에서 글로벌 디렉터리의 시작 주소를 알아내고, 글로벌 디렉토리에서 몇번째 위치인지 알아낸다고 했다. 여기에 쓰이는 함수가 pgd_offset()이다. 마찬가지로 미들 디렉토리에서의 위치를 알아내는 것은 pmd_offset, 페이지 테이블에서의 위치를 알아내는 것은 pte_offset이다. pgd_offset, pmd_offset, pte_offset은 모두 2개의 인자를 갖는다.
pgd_offset(mm, address)인데 mm은 메모리 관리를 위한 구조로 각 프로세스마다 1개씩 갖고 있다. 즉, 페이지 글로벌 디렉토리의 시작 위치가 되며, address는 페이지 글로벌 디렉터리에서 몇 번째 위치라는 것을 나타낸다. 마찬가지로 pmd_offset의 첫번째 인자는 페이지 미들 디렉토리의 시작위치를, 두번째 인자는 페이지 미들디렉토리의 몇번째 페이지를 인자로 받는다. pte_offset도 동일하다. Redhat 9에 포함된 커널 2.4.20-8 버전에서는 pte_offset 대신에 pte_offset_kernel을 사용하면 된다. 상위 버전의 커널에서는 pte_offset으로 이용할 수 있다.
이들 함수(정확히는 매크로)를 이용하면 프로세스가 실제로 이용하고 있는 물리 메모리를 알아낼 수 있다. 이들 매크로는 arch/asm-i386/pgtable.h, pgtable-3level.h에서 찾아볼 수 있다. 참고로 실제로 존재하지 않는 페이지 글로벌 디렉토리, 미들 디렉토리 등을 액세스하려하면 중대한 커널 오류가 발생할 수 있다. 따라서, 페이지를 액세스하기 전에 각각 pgd_present, pmd_present, pte_present를 사용해서 실제 페이지가 있는지 확인하고 사용해야 한다.
프로세스에서 바라본 메모리
프로세스마다 4G의 가상 공간을 사용한다고 얘기했다. 그리고, 프로세스마다 메모리 관리를 하기 위해 페이지 글로벌 디렉토리, 페이지 테이블과 같은 구조를 갖고 있다고 했다. 프로세스를 나타내는 구조체는 task_struct이며, 여기에는 메모리 구조를 나타내는 mm_struct mm이 있다. mm은 메모리 관리를 위한 구조체이며, pgd_t* pgd는 페이지 글로벌 디렉토리의 시작 위치를 가리킨다. 즉, pgd가 가리키는 값과 CR3 레지스터가 가리키는 값이 같다. 그 이후부터는 앞에서 설명한 것처럼 각 페이지별로 주소를 찾아서 실제 메모리상의 프레임을 찾아간다.

그림5. 프로세스에서 바라본 메모리
이를 자세하게 표현하면 그림6과 같습니다. 각각의 프로세스는 task_struct 구조체로 표현되며, 이를 간단히 PCB(Process Context Block, 컨텍스트 문맥)이라고 이야기한다. 커널에는 프로세스 ID로 해당 PCB를 찾아내는 함수가 있는데 이 함수가 find_task_by_pid(pid)이다. 이 함수는 프로세스 ID, PID를 인자로 넘겨 받으면 task_struct에 대한 것을 반환해준다.
물론, 현재 프로세스는 current로 접근할 수 있지만, 다른 프로세스에 대한 task_struct를 얻어오려면 find_task_by_pid를 사용해야 한다. task_struct에는 mm이 있고, 이 mm이 mm_sturct 자료구조를 가리킨다.
그림1을 생각해보면 프로세스는 연속적인 가상 메모리를 할당 받는 것도 아니라 여러 개의 가상 메모리 블록을 할당받는다. 즉, 연속적으로 할당 받을 수도 있고, 따로따로 할당 받을 수도 있다는 얘기다. 이를 위해서 mm_struct에 보면 각각의 가상 메모리 블록을 관리하는 vm_area_struct 구조체가 있다. 그리고 vm_area_struct에는 각각 vm_start와 vm_end가 있는데 이는 가상 메모리 공간에서의 시작 위치와 마지막 위치를 가리킨다. 또한 vm_area_sturct* vm_next는 자신과 같은 형태의 구조체를 다시 가리키고 있는데, 이는 다른 가상 메모리 블록을 가리킨다. 즉, 단일 연결 리스트(Singly Linked List)로 연결되어 있다. vm_next를 따라 프로세스가 사용하는 전체 가상 메모리 공간을 알아낼 수 있다. 만약, vm_next가 NULL인지 아닌지를 알아내면 가상 메모리 블록의 끝을 알아낼 수 있다.

그림6. 프로세스에서 바라본 메모리 관리
마지막으로 task_struct에는 mm_struct로 선언된 변수가 두 가지가 있다. 하나는 mm이고, 다른 하나는 active_mm이다. mm은 프로세스가 사용하는 메모리 공간을 나타내고, active_mm은 CPU에 의해 현재 제어중인 주소공간을 가리킨다. 프로세스 A에게 있어서 mm과 active_mm은 같다. 즉, A->mm == A->active_mm이다. 그러나, 커널 스레드에서는 mm은 NULL이며, 커널 스레드가 사용중인 메모리는 active_mm으로 표현된다.
Linux 커널의 아버지인 Linus는 메모리 공간을 실주소공간(Real Address Spaces)과 익명주소공간(Anonymous Address Spaces)로 나눈다. 사용자 프로세스가 사용하는 주소 공간을 실주소공간아리하고, 커널 스레드가 사용하는 공간을 익명주소공간이라 하는 것이다.
모든 커널 스레드는 익명주소공간을 사용하며, 사용자 프로세스가 사용하는 실주소공간에 대해서는 관여하지 않는다.
foo라는 프로세스 A를 실행한다고 하자. 이 경우 A->mm == A->active_mm = foo일 것이다. 이때 커널 스레드 B에 의해 선점당한 경우 B->mm = NULL이지만, A->active_mm = foo를 여전히 가리키게 된다. 즉, 커널 스레드는 실주소공간을 신경쓰지 않지만, 작업 A가 다시 로드되었을 때 mm을 다시 로드하지 않기 위해 active_mm을 사용하는 것이다.
스왑
실제 메모리 사용량보다 더 큰 메모리가 필요한 프로그램을 실행할 수 있는 것은 가상 메모리 덕분이다. 앞에서는 가상 메모리에 대해서 살펴보았는데, 사용중이지 않은 부분은 스왑으로 저장해서 메모리에 여유공간을 확보하는 것이 스왑의 역할이다.
앞의 그림5에서 살펴본 것처럼 스왑을 한다는 것은 실제 메모리의 프레임을 디스크로 저장하는 것을 의미한다. 실제 메모리 프레임을 찾기 위해서는 페이지 테이블의 위치를 알아야하고, 페이지 테이블의 위치를 알기 위해서는 페이지 미들 디렉토리의 위치를 알아야한다. 마찬가지로, 페이지 미들 디렉토리의 위치를 알기 위해서는 페이지 글로벌 디렉토리의 위치를 알아야 한다. 이들 프로세스는 가상 메모리로 관리되고 있으니 가상 메모리 구조를 찾아봐야하고, 다시 실제 메모리 공간도 찾아봐야 한다. 즉, swap_out 함수는 이러한 순서들을 찾아가며 실제 메모리 프레임을 찾아가는 역할을 하고, 메모리 프레임을 디스크에 저장하는 것은 try_to_swap_out 함수의 역할이다.

그림7. 스왑의 흐름
kswapd 함수는 daemonize 함수를 호출해서 자신을 데몬으로 등록시키고, 무한 루프를 돌면서 kwapd_can_sleep 함수를 호출한다. 이 함수는 지금 스왑 작업을 해도 되는지 아닌지를 판별하며, 이를 판별하기 위해서는 다시 kswapd_can_sleep_pgdat를 호출해서 페이지 글로벌 디렉토리에서 스왑이 필요한 페이지가 있는지 없는지를 판별한다. 스왑이 필요한 페이지가 하나라도 있으면 kswapd_balance를 호출한다. kwapd_balance는 메모리의 균형을 맞춰준다. 마찬가지로 이 함수도 kswapd_balance_pgdat를 호출하여 페이지 글로벌 디렉토리를 확인한다. try_to_free_pages 함수에서 try_to_free_pages_zone을 호출해서 사용할 수 있는 페이지 영역을 찾아보고, 사용할 수 있는 페이지가 부족한 경우에는 필요한 페이지를 확보하기 위해 shrink_caches를 호출한다. shrink_caches는 캐시들을 돌아다니며 비울 수 있는 캐시인지 판별하기 위해 shrink_cache 함수를 사용한다.
전체적인 흐름은 이렇게 되어 있으며, 각 프로세스에서 사용중인 스왑 공간은 task_struct의 swap_address로 알 수 있다.
스왑 정책
커널의 스왑 정책에서 사용할 수 있는 방법은 여러가지가 있지만, 리눅스 커널에서는 LRU(Least Recently Used) 정책을 사용한다고 알려져 있다. LRU는 가장 적게 사용된 페이지를 스왑으로 대체시키는 것이다.
메모리 페이지를 LRU 정책에 따라 스왑시키려면 해당 메모리 페이지가 액세스 된 적이 있는지 알아낼 수 있는 방법이 있어야 한다. 각 페이지가 액세스 된 시간을 기록해서, ‘아, 이 페이지는 1시간 전에 액세스했고, 이 페이지는 5분전에 액세스했네’라는 사실을 이용할 수도 있을 것이다. 단, 이렇게 한다면 액세스 될 때마다 시간을 기록하고, 각 페이지의 시간을 기록하고 유지하는 것만으로도 굉장히 높은 작업부하가 걸릴 것이라고 예상할 수 있을 것이다. 이런 스왑 정책은 OS가 단독으로 하기엔 어려운 부분이다. CPU에서는 이를 위해 액세스 비트(Access Bit)를 제공한다. 이 비트는 이 페이지가 접근된 적이 없으면 0, 있으면 1로 설정된다. 그림8에서 A가 액세스 비트를 나타낸다. 액세스 비트는 페이지에 접근할 때 CPU에서 자동으로 1로 설정하지만, CPU가 이를 다시 0으로 설정할 수는 없다. 0으로 설정할 수 있는 것은 오직 커널 뿐이다.

그림8. 페이지 엔트리
U/S는 사용자 프로세스가 접근할 수 있으면 1이고, 커널만 접근할 수 있으면 0으로 설정된다. R/W는 0이면 읽기만 가능하고, 1이면 읽기/쓰기가 모두 가능하다. P는 Present Bit라는 것으로 페이지가 메모리상에 존재하는지를 나타낸다. 즉, 페이지가 디스크로 스왑 되었으면 0이 된다. 프로세스가 이 페이지를 접근하려하면 P 비트가 0이기 때문에 페이지 폴트 인터럽트 #14가 발생하고, 디스크에서 다시 메모리로 이 페이지를 읽어들이고, P 비트를 1로 설정하게 된다.
메모리 관리와 관련된 부분은 OS가 독단으로 결정할 수 있는 것이 아니며, CPU와 OS가 서로 조화를 이루어가며 관리하는 부분이다.
코드로 보는 리눅스
8086 시스템은 과거에 20개의 어드레스 핀을 가진 16비트 시스템이었다. 즉, 2^20 = 1M까지 사용할 수 있는 시스템이었다. 이 의미는 1M 이상의 메모리를 사용할 수 없다는 것이다. 1M + 1번째를 접근하려 하면 1번째로 접근하게 된다. 이는 마치 프로그래밍 언어에서 만나는 정수 오버플로우와 같다. 1M + 1 = 1로 만들려면 어떻게 하면 될까? 2^20은 16진수로 0x100000이고, 2진수로는 100000000000000000000이다. 1M를 넘어가는 비트가 공교롭게도 가장 맨 앞의 비트이다. 즉, 맨 앞의 1을 0으로 만들어 주기만 하면 된다. 11111111111111111111 + 1을 하면 100000000000000000000이 되어야 하는데 20번째 비트를 0으로 만들면 결과 값은 0이 된다. +2를 하면 결과값은 1이 될 것이다.
이를 위해 8086 시스템에서는 20번째 핀을 키보드 인터럽트 핸들러인 8042와 AND 게이트로 연결해 놓았다. 20번째 핀이 켜지지 않으면 사용자는 항상 저 주소를 이용할 수 없다.
펜티엄 4에서 DOS용 응용 프로그램을 실행할 수 있다는 의미는 하위 호환성이 좋다는 의미이기도 하지만, 위와 같은 단점도 고스란히 물려받았다는 의미가 된다.
요즘과 같이 512M 램을 사용하는데, 저걸 알아서 뭐해요? 라고 되물을수도 있다. 그러나 A20을 켜주지 않으면 20번째 비트가 항상 0이 되기 때문에 1M = 0이 되고, 3M = 0이 된다. 즉, 1M에 해당하는 메모리 주소를 CPU가 액세스하려하면 0번째를 가리키게 된다. 사용자는 1, 3, 5, 7…과 같이 홀수번째 메모리를 전혀 사용할 수 없게 된다. 그렇게 때문에 부팅 과정에서 CPU가 리얼 모드에서 보호 모드로 넘어가기전에 반드시 A20 게이트를 켜야한다.

리눅스 커널의 소스 코드를 보면 그런 부분이 있다. movb $0xDF, %al이 있고, 옆에는 주석으로 A20 게이트를 켠다고 되어 있다. 이 부분의 값은 몰라도 된다. 저것은 CPU 매뉴얼에 있는 특정한 명령어인 것이다.

여기서는 lgdt gdt_48을 볼 수 있다. lgdt 명령어는 전체 커널 소스에서 단 한번만 사용된다. CPU는 리얼 모드에서 보호 모드로 넘어가기전에 글로벌 디스크립터(Global Descriptor)를 작성해야 한다. 즉, 4G에 해당하는 메모리를 어떻게 사용하겠는가를 설계하는 명세서와 같은 역할을 한다. 코드 세그먼트 디스크립터, 데이터 세그먼트 디스크립터, 비디오 세그먼트 디스크립터등을 지정할 수 있다. gdt_48은 명령어가 아니라 이러한 디스크립터를 적어놓은 곳으로 C언어의 struct와 같은 것이다.
리얼 모드에서 보호 모드로 넘어가는 순서는 1. 디스크립터를 정의한다. 2. lgdt 명령어로 디스크립터를 로드하고 보호모드로 전환한다. 이다.
CPU에는 명령어를 실행하는 부분이 3가지로 나누어져 있다. 첫번째는 명령어를 읽어들이는 부분, 두번째는 명령어를 해석하는 부분, 세번째는 명령어를 실행하는 부분이다.
즉, lgdt 명령어를 실행하게 되는 순간에 읽기 유닛, 해석 유닛에 이미 2개의 명령어가 들어가 있다. 보호모드로 전환된 다음에 리얼 모드에서 들어가 있던 명령어가 실행되면 안되니까 최소한 읽기, 해석 유닛의 명령을 무시하기 위해 두 스텝을 쉬어줄 필요가 있다. 따라서, lgdt 명령어를 실행한 다음에 어셈블리로 nop(No Operation: 아무일도 하지마!)를 2번 실행해주는 것이 관례다. 그런데, 커널 소스에선 nop 대신에 call delay를 사용하는 것 같다고 나름대로 추측할 수 있었다. nop 명령어를 커널에선 사용하지 않는다.
다음으로 첫번째 줄을 보면 lidt 명령이 있다. 이것은 인터럽트 디스크립터를 로드한다. 즉, Devide By Zero(인터럽터 0번)이라든가, 페이지 폴트(인터럽터 14번) 같은 인터럽트가 발생했을 때 이를 처리할 루틴의 위치를 지정하는 부분이 idt_48이고, lidt는 이를 메모리에 로드해주는 것이다.
굳이 이렇게 GDT를 꺼내든 이유는 <<리눅스 커널의 이해>>의 2장 메모리 관리 부분의 처음 1/2 정도가 전부 이 GDT 구조를 설명하는데 할애되어 있다고 느꼈기 때문이다. 책만 펼치면 잠이 쏟아질 만큼 졸린데, 이는 어셈블리와 CPU 구조에 대한 이해조차 없이는 책을 이해하기 어렵기 때문이라 생각했다. 즉, 내공이 부족한 내가 보기엔 어려운 책이다.
이들 어셈블리 코드는 arch/i386/boot에 있으며, 비디오 디스크립터는 video.S에 정의되어 있다.

위 코드처럼 0xC0000000가 3G 영역을 가리킨다. 커널이 3G위의 영역을 사용한다는데 실제로 그 값이 있는지 확인해 본 부분이다.

여기서는 앞에 CR4 레지스터가 보인다. CPU에는 CR0-CR4까지의 레지스터가 있다. 이중에서 CR3는 페이지 글로벌 디렉토리의 위치를 가리키며, CR4 레지스터는 PAE 확장을 사용할 것인가를 설정한다. 펜티엄 프로 이후에는 어드레스 핀이 4개가 더 추가되어서 4G가 아니라 64G까지 사용할 수 있게 해준다. 따라서, 이 값이 설정된 경우에 CR4 비트를 1로 설정해서 PAE 확장을 사용하게 설정해 주는 부분이다.

movl %eax, %cr3에서 페이지 테이블이 시작하는 위치를 CR3 레지스터에 저장하고 있다.(GAS, GNU Assembler는 AT&T 스타일을 따르고 있어서 어셈블리 명령어 인자 위치가 서로 반대다. mov a, b는 B의 값을 A에 넣는다이지만 AT&T 스타일에서는 A의 값을 B에 넣는다가 된다)
마치며
아직은 커널을 잘 알지 못하고 커널을 공부하는 입장에서 준비된 글입니다. 국내에 나와있는 다양한 커널 책들을 많이 참고했습니다. 아직 다루지 못한 부분들이 많습니다. 커널 소스에 대한 세세한 설명보다는 커널의 전체적인 흐름을 다루는 것이 세미나에는 더 적합하다고 판단해서 전체적인 흐름을 다루는데 중점을 두었습니다. kmalloc과 vmalloc의 차이점을 다루는 것 보다는 전체적인 흐름이 더 중요하다고 생각했습니다. 흐름에 대한 이해를 바탕으로 소스 코드를 살펴보는 것이 이해에 더 도움이 된다고 생각합니다.
레퍼런스
각각의 책마다 같은 부분을 보아도 설명이나 보여주는 부분이 다릅니다. 결국, 저자가 커널을 바라보는 방식에 대해 생각해보는 기회도 되고, 책을 가이드삼아 커널을 직접 찾아보며 전체를 바라볼 수 있는 안목을 기르는 것은 자신의 몫이라 생각됩니다. 주로 리눅스 커널 프로그래밍을 많이 참고했으며, 리눅스 커널 심층 분석은 커널 API 이해에 많은 도움이 되었습니다. Operating System Concepts는 운영체제가 시스템을 관리하는 다양한 방법과 알고리즘에 대한 해설이 중심이고 이를 토대로 리눅스 커널이 채택한 방법을 살펴보는 데 좋은 참고가 됩니다. 리눅스 커널의 어셈블리 코드 부분은 만들면서 배우는 OS 커널의 구조와 원리에서 많은 부분을 참조했습니다.
• 리눅스 커널의 이해, 2판, 한빛미디어
• 만들면서 배우는 OS 커널의 구조와 원리, 한빛미디어
• 리눅스 커널 프로그래밍, 교학사
• 리눅스 매니아를 위한 커널 프로그래밍, 교학사
• 리눅스 커널 심층 분석, 에이콘
• 리눅스 커널 분석 2.4, 가메
• Operating System Cencepts, 6판, 홍릉
[출처] 초보자를 위한 리눅스 커널의 메모리 관리 |작성자 jabusunin
'Computer_language > Linux' 카테고리의 다른 글
| Ubuntu 8.04 LTS sources.list (0) | 2009.01.16 |
|---|---|
| 리눅스 커널 스터디 참고자료 (0) | 2009.01.12 |
| GNU Make: 재컴파일을 지휘하는 프로그램(A Program for Directing Recompilation) (0) | 2009.01.12 |
| MAKE를 이용한 프로젝트 관리 (Managing Projects with make) (0) | 2009.01.12 |
| 우분투 사용 총집합서 (0) | 2009.01.12 |
GNU Make: 재컴파일을 지휘하는 프로그램(A Program for Directing Recompilation)
| Computer_language/Linux 2009. 1. 12. 01:09GNU make Version 3.77.
May 1998
번역시작: March 2000
최종 갱신: May 9th, 2000
Richard M. Stallman 그리고 Roland McGrath
역자: 선정필
make 개관(Overview of make)
make 유틸리티는 커다란 프로그램의 어떤 조각들이 재컴파일되야 하는지를 자동으로 결정하고 그것들을 재컴파일하는 명령들을 발행한다. 이 매뉴얼은 GNU make를 설명한다. GNU make는 리차드 스톨만(Richard Stallman)과 롤랜드 맥그래스(Roland McGrath)에 의해서 개발되었다. GNU make는 IEEE Standard 1003.2-1992 (POSIX.2). 의 section 6.2와 호환된다.
우리의 예제들은 C 프로그램들을 보여줄 것이다. 이것이 가장 일반적이기 때문이지만 여러분은 어떤 프로그램 언어라도 그것의 컴파일러가 쉘 명령으로 실행될 수 있다면 make를 사용할 수 있다.
make를 사용하기 위해서 준비하려면 여러분은 여러분의 프로그램 안에 있는 파일들 간의 관계를 설명하고, 각 파일을 업데이트하는 명령들을 제공하는 makefile이라고 불리는 파일을 반드시 작성해야 한다. 전형적으로 프로그램 안에서 실행 파일은, 소스 파일들을 컴파일해서 만들어지는 오브젝트 파일들로부터 업데이트된다.
일단 적당한 makefile이 존재하면 여러분이 어떤 소스 파일들을 변경할 때마다 다음과 같은 쉘 명령이 모든 필요한 재컴파일들을 수행하는 데 충분하다:
make
make 프로그램은 makefile 데이터베이스와 파일들의 마지막-변경 시간들을 사용해서 어떤 파일들이 업데이트되어야 하는지를 결정한다. 이런 파일들 각각에 대해서 데이터베이스에 기록된 명령들을 수행한다.
어떤 파일들이 재컴파일되어야 하는지 또는 어떻게 재컴파일되어야 하는지를 제어하기 위해서, 여러분은 make에 대한 명령 라인 매개변수들을 제공할 수 있다. See section make 실행 방법(How to Run make).
이 매뉴얼을 읽는 방법(How to Read This Manual)
여러분이 make의 초심자이거나 일반적인 설명을 찾고 있는 사람이라면 각 장의 나중 섹션들은 건너 뛰고 첫번째 몇 섹션들을 읽어라. 각 장에서 첫번째 몇가지 섹션들은 개론적인 또는 일반적인 정보들을 담고 있고 나중의 섹션들은 특수한 또는 기술적인 정보들을 담고 있다. 2장은 예외인 데, section Makefile 소개(An Introduction to Makefiles), 모든 것들이 개론적이다.
다른 make 프로그램들에 친숙하다면, GNU make가 갖고 있는 개선점들을 설명한 section GNU make의 기능과, 다른 것들이 가지고 있지만 GNU make는 갖고 있지 않는 몇가지 것들에 대한 설명을 한 section 비호환성과 빠진 기능들(Incompatibilities and Missing Features)을 보기 바란다.
빠른 요약을 위해서는 section 옵션들의 요약(Summary of Options), section 빠른 레퍼런스(Quick Reference), 그리고 section 특수 내장 타겟 이름(Special Built-in Target Names)을 보기 바란다.
문제점과 버그(Problems and Bugs)
GNU make에 문제를 발견하였거나 버그를 발견했다면 그것을 개발자들에게 알려 주기 바란다; 우리는 우리가 그것을 고치기를 원한다는 것외에는 아무것도 약속할 수 있는 것이 없다.
버그를 리포트하기 전에 실제 버그를 실제로 발견했는지 확인하기 바란다. 조심스럽게 문서들을 다시 읽고 그리고 그것이 여러분이 하고자 하는 것을 할 수 있다고 실제로 말하는지 보기 바란다. 여러분이 어떤 것을 할 수 있는지 없는지 잘 모르겠다면 그것도 같이 보고해주기 바란다; 그것은 문서의 버그인 것이다!
버그를 리포트하기 전에 그리고, 그것을 여러분 스스로 고치도록 노력하기 전에, 그것을 그 문제를 다시 만드는 가능한 한 가장 작은 makefile로 분리해도록 해보라. 그리고 나서 그 makefile과 make가 여러분에게 만들어 내는 정확한 결과들을 우리에게 보내기 바란다. 또한 여러분이 일어날 것이라고 기대하는 것을 말해주기 바란다; 이것은 우리가 그 문제가 실제로 문서에 있는 것인지를 결정할 수 있도록 도울 것이다.
일단 여러분이 정확한 문제를 얻었다면 다음 주소로 이메일로 보내주기 바란다:
여러분이 사용하는 make의 버전번호를 포함시켜 주기 바란다. 여러분은 이 정보를 `make --version'이라는 명령으로 얻을 수 있다. 또한 여러분이 사용중인 머쉰과 운영체제의 종류를 포함시켜 주기 바란다. 가능하다면 configuration 과정 중에 생성된 `config.h'라는 파일의 내용도 포함시켜 주기 바란다.
Makefile 소개(An Introduction to Makefiles)
여러분은 makefile이라고 불리는, make에게 무엇을 할 것인가를 말하는, 파일이 필요하다. 대개 makefile은 make에게 어떤 프로그램을 컴파일하고 링크하는 방법을 설명한다.
이 장에서 우리는 8개의 C 소스 파일들과 3개의 헤더 파일들로 이루어진 텍스트 에디터를 컴파일하고 링크하는 방법을 기술하는, 단순한 makefile에 대해서 얘기할 것이다. makefile은 또한 make에게, 명시적으로 요구되었을 때 다양한 명령들을 실행하는 방법을 말할 수 있다(예를 들어서 어떤 파일들을 청소 작업으로써 제거하기). makefile의 좀 더 복잡한 예제를 보려면 section 복잡한 makefile 예제(Complex Makefile Example)을 참조하기 바란다.
make가 에디터를 재컴파일할 때 각 변경된 C 소스 파일들은 반드시 재컴파일되어야 한다. 헤더 파일이 변경되면, 해당 헤더 파일을 include하는 각 C 소스파일도 반드시 재컴파일되어야 한다. 각 컴파일은 소스 파일에 대응하는 오브젝트 파일을 생성한다. 마지막으로 어떤 소스 파일이 재컴파일되었다면, 모든 오브젝트 파일들은 그들이 새로 만들어진 것이든 아니든 반드시 같이 링크되어서 새로운 편집기 실행 파일을 만들어야 한다.
규칙의 모습(What a Rule Looks Like)
단순한 makefile은 다음과 같은 모양의 "규칙들"로 이루어진다:
target ... : dependencies ...
command
...
...
target은 일반적으로 프로그램에 의해서 생성되는 파일의 이름이다; 실행 파일이나 오브젝트 파일 등이 target 파일의 예이다. target은 또한, `clean' (see section 가짜 목적물(Phony Targets))와 같은, 실행할 액션의 이름이 될 수도 있다.
dependency는 target을 만들기 위한 입력으로 사용되는 파일이다. target은 종종 여러개의 파일에 의존한다.
command는 make가 실행하는 액션이다. 규칙은 하나 이상의 command를 가질수도 있는 데, 각각은 자신의 라인 위에 있다. Please note: 여러분은 모든 command 라인의 처음에 하나의 탭 문자를 가져야 한다! 이것은 조심성 없음을 잡는 방해물이다.
일반적으로 command는 dependencies와 함께 한 규칙 안에 존재하고 dependencies들 중의 어떤 것이라도 변했다면 target 파일을 생성하는 일을 한다. 그러나, target을 위한 command들을 지정하는 규칙이 반드시 dependencies를 가질 필요는 없다. 예를 들어서 `clean'이라는 target과 연관된 삭제 command를 담고 있는 규칙은 dependencies를 가지지 않는다.
그렇다면 rule은 특정한 규칙의 target인 어떤 파일들을 언제 어떻게 리메이크할 것인가를 설명하는 것이 될 것이다. make는 target을 생성하거나 업데이트하기 위해서 dependencies에 command를 수행한다. 규칙은 또한 어떤 액션을 언제 어떻게 수행할 것인가를 설명할 수 있다.See section 규칙 작성(Writing Rules).
makefile은 규칙들 외에 다른 텍스트들을 담고 있을 수 있지만 단순한 makefile은 단지 규칙들을 담고 있을 뿐이다. 규칙들은 이런 템플리트에서 보여지는 것보다 어쩌면 좀 더 복잡해 보일 수 있지만, 모두가 이 패턴에 큰 오차없이 맞아 떨어진다.
단순한 Makefile(A Simple Makefile)
여기에 edit 라고 불리는 실행 파일 하나가, 8개의 C 소스와 3개의 헤더 파일들에 의존하는, 8개의 오브젝트 파일들에 의존하는 모습을 설명한 직설적인 makefile 예제가 있다.
이 예제에서 모든 C 파일들은 `defs.h'을 include하지만 편집 명령들을 정의한 것들만이 `command.h'를 include하고 편집기 버퍼를 변경하는 낮은 레벨의 파일들만이 `buffer.h'를 include한다.
edit : main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
cc -o edit main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
main.o : main.c defs.h
cc -c main.c
kbd.o : kbd.c defs.h command.h
cc -c kbd.c
command.o : command.c defs.h command.h
cc -c command.c
display.o : display.c defs.h buffer.h
cc -c display.c
insert.o : insert.c defs.h buffer.h
cc -c insert.c
search.o : search.c defs.h buffer.h
cc -c search.c
files.o : files.c defs.h buffer.h command.h
cc -c files.c
utils.o : utils.c defs.h
cc -c utils.c
clean :
rm edit main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
우리는 기다란 라인을 백슬래시-개행을 사용해서 두 라인으로 분할했다; 이것은 하나의 긴 라인을 쓰는 것과 동일하지만 읽기에 더 쉬운 것이다.
이 `edit'라고 불리는 실행 파일을 만들도록 makefile을 쓰기 위해서는 다음과 같이 입력한다:
make
이 makefile을 사용해서 실행 파일과 모든 오브젝트 파일들을 삭제하려면 다음과 같이 입력한다:
make clean
이 예제 makefile에서 target들은 `edit'라는 실행 파일과 `main.o'와 `kbd.o'라는 오브젝트 파일들을 포함한다. dependencies는 `main.c'와 `defs.h'와 같은 파일들이다. 실제로 각 `.o' 파일은 target이면서 동시에 dependency이다. command는 `cc -c main.c'와 `cc -c kbd.c'를 포함한다/
target이 파일일 때, 어떤 dependencies 들중 하나가 변경되었을 때 재컴파일되거나 재링크되어야 한다. 게다가 스스로 자동적으로 생성된 어떤 dependencies는 맨먼저 업데이트되어야 한다. 이 예제에서 `edit'는 8개의 오브젝트 파일들에 의존한다; `main.o'는 소스 파일 `main.c'와 헤더 파일 `defs.h'에 의존한다.
target과 dependencies을 담고 있는 각 라인 뒤에 쉘 명령이 따른다. 이런 쉘 명령들은 target 파일을 업데이트 하는 방법을 말하는 것이다. 탭 문자 하나가 각 명령 라인의 맨 앞에, makefile의 다른 라인들과 명령 라인들 간의 구분이 되도록, 반드시 와야 한다. (make는 command가 어떻게 작옹하는지에 대해서 아무것도 모른다는 것을 기억하기 바란다. target 파일을 적절하게 업데이트할 명령들을 제공하는 것은 여러분들에게 달려 있다. target 파일이 업데이트되어야 할 때 여러분이 지정한 규칙들에 있는 command들을 실행하는 것이 `make'가 하는 모든 것이다.)
`clean'이라는 target은 파일이 아니고 단지 액션의 이름이다. 이 규칙안에 있는 액션이 일반적인 경우에 실행되는 것을 바라지 않을 것이기 때문에 이 규칙은 자신 스스로가 dependency가 아닐뿐더러 어떤 dependencies도 가지지 않는다. 그래서 이 규칙의 단 하나의 목적은 특정 명령들을 실행하는 것이다. 파일이 아닌 단지 액션을 지칭하는 target은 phony targets이라고 불린다. 이런 종류의 target에 대한 정보를 보려면 See section 가짜 목적물(Phony Targets)을 참조하기 바란다. make가 rm이나 다른 명령으로부터 에러를 무시하도록 하는 방법에 대해서는 See section 명령에서 에러(Errors in Commands)를 참조하기 바란다.
make가 Makefile를 처리하는 방법(How make Processes a Makefile)
디폴트로 make는 첫번째 target(그것의 이름이 `.'으로 시작하지 않는 target)으로 시작한다. 이것은 default goal이라고 불리는 것이다.(Goals는 make가 궁극적으로 업데이트하려고 하는 target이다 See section goal을 지정하는 매개변수(Arguments to Specify the Goals).)
이전 섹션에 있는 단순 예제에서 default goal은 실행 프로그램 `edit'를 업데이트하는 것이다; 그래서 우리는 그 규칙을 맨 처음에 놓았던 것이다.
그래서 다음과 같이 명령을 주면 make는 현재 디렉토리에서 makefile을 읽고 첫번째 규칙을 처리하기 시작한다:
make
예제에서 이 규칙은 `edit'를 리링킹하는 것이다; 그러나 make가 이 규칙을 완전히 처리할 수 있기 전에, `edit'가 의존하고 있는 파일들에 대한 규칙들을 반드시 처리해야 한다. 이것은 이경우 오브젝트 파일들이다. 이런 파일들 각각은 그 자신의 규칙에 따라서 처리된다. 이런 규칙들은 각 `.o'파일을 그의 소스 파일을 컴파일해서 업데이트하라고 말한다. 소스 파일이 또는 dependencies에 있는 헤더파일들 중 어떤 것이라도 오브젝트 파일보다 더 최근의 것이라면 또는 오브젝트 파일이 존재하지 않는다면 재컴파일이 반드시 일어나야 한다.
다른 규칙들은, 그들의 target들이 goal의 dependencies로 나타나기 때문에, 처리된다. 어떤 다른 규칙이 goal이 의존하는 것이 아니라면(또는 그것이 의존하는 어떤 것도 없다면), make에게 그렇게 하라고 말하지(make clean과 같은 명령으로) 않는 한, 그 규칙은 처리되지 않는다.
오브젝트 파일을 재컴파일하기 전에, make는 그것의 dependencies, 소스 파일과 헤더 파일들을 업데이트하는 것을 고민한다. 이 makefile은 그것들을 위해서 행해진 어떤 것도 지정하지 않은 것이다-- `.c'와 `.h'파일들은 어떤 규칙들의 target도 아니다-- 그래서 make는 이런 파일들에 대해서 아무것도 하지 않는다. 그러나 make는 Bison이나 Yacc에 의해서 만들어진 것들과 같은, C 프로그램들을, 이 순간 그들의 규칙에 의해서 자동으로 생성한다.
오브젝트 파일들이 필요로 하는 것이면 무엇이든 재컴파일한 후, make는 `edit'를 리링크할 것인가를 결정한다. 이것은, `edit'파일이 맛聆舊?않거나 오브젝트 파일들 중 어떤 것이라도 그것보다 더 최근의 것이라면, 반드시 수행되어야 한다. 어떤 오브젝트 파일이 단지 재컴파일되었다면 그것은 이제 `edit'보다 더 새로운 것이고 그래서 `edit'는 재링크된다.
그래서, 우리가 `insert.c' 를 변경하고 make를 실행하면, make는 `insert.o'를 갱신하기 위해서 그 파일을 컴파일할 것이고 `edit'를 링크할 것이다. 우리가 `command.h' 를 변경하고 make를 실행하면 make는 `kbd.o', `command.o' 그리고 `files.o'들을 재컴파일할 것이고 그리고 나서 `edit'를 링크할 것이다.
Makefile을 좀 더 쉽게 만드는 변수들(Variables Make Makefiles Simpler)
우리의 예제에서 `edit'를 위한 규칙에서 우리는 모든 오브젝트 파일들을 두번씩 기술했다 (여기에 반복되어 있다):
edit : main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
cc -o edit main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
이렇게 반복하는 것은 에러를 발생시킬 수 있는 여지가 있다; 새로운 오브젝트 파일이 시스템에 추가되면 우리는 그것을 한 리스트에는 추가하지만 다른 것에는 잊어 버리고 추가하지 않을 수 있다. 우리는 어떤 변수를 사용하여 이런 리스크를 없애고 makefile을 단순하게 만들 수 있다. Variables는 한번 정의되고 나중에 여러곳에서 대입되는 텍스트 문자열을 허락한다(see section 변수 사용 방법(How to Use Variables)).
모든 makefile이, 모든 오브젝트 파일 이름들의 리스트에 대해서 objects, OBJECTS, objs, OBJS, obj, 또는 OBJ 라는 이름의 변수를 쓰는 것은 표준 관례(standard practice)이다. 우리는 다음과 같은 makefile에서 처럼 그런 변수 objects를 하나의 라인으로 정의할 것이다:
objects = main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
그리고 나서 우리가 오브젝트 파일 이름들의 리스트를 놓고자 하는 곳마다 그 변수의 값을, `$(objects)'라고 써서 대입할 수 있다(see section 변수 사용 방법(How to Use Variables)).
오브젝트 파일들에 대한 변수를 사용할 때 단순한 makefile이 어떻게 보이는지에 대한 예시가 있다:
objects = main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
edit : $(objects)
cc -o edit $(objects)
main.o : main.c defs.h
cc -c main.c
kbd.o : kbd.c defs.h command.h
cc -c kbd.c
command.o : command.c defs.h command.h
cc -c command.c
display.o : display.c defs.h buffer.h
cc -c display.c
insert.o : insert.c defs.h buffer.h
cc -c insert.c
search.o : search.c defs.h buffer.h
cc -c search.c
files.o : files.c defs.h buffer.h command.h
cc -c files.c
utils.o : utils.c defs.h
cc -c utils.c
clean :
rm edit $(objects)
`make'가 명령을 추론하도록 하기(Letting make Deduce the Commands)
개별 C 소스 파일들을 컴파일하기 위한 명령들을 전부 나열하는 것은 불필요하다. 왜냐면 make는 그것을 추측해낼 수 있기 때문이다: 그것은 `cc -c'명령을 사용해서 대응되는 `.c'파일로부터 `.o'파일을 갱신하기 위한 implicit rule을 가지고 있다. 예를 들어서, `main.c'를 `main.o'로 컴파일하기 위해서 `cc -c main.c -o main.o'라는 명령을 사용할 것이다. 그러므로 우리는 그 오브젝트 파일들에 대한 규칙들로부터 그 명령들을 생략할 수 있다. See section 묵시적 규칙(Using Implicit Rules).
`.c'파일이 이런 식으로 자동으로 사용될 때, 그것은 또한 dependencies 리스트에 자동으로 추가된다. 그러므로 우리는, 우리가 그 명령들을 생략했다면, dependencies로부터 `.c'파일들을 생략할 수 있다.
이런 변화들과 위에서 제시된 것과 같은 변수 objects 를 모두 예시한 다음 예제를 보자:
objects = main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
edit : $(objects)
cc -o edit $(objects)
main.o : defs.h
kbd.o : defs.h command.h
command.o : defs.h command.h
display.o : defs.h buffer.h
insert.o : defs.h buffer.h
search.o : defs.h buffer.h
files.o : defs.h buffer.h command.h
utils.o : defs.h
.PHONY : clean
clean :
-rm edit $(objects)
이것은 우리가 실제 상황에서 makefile을 작성하는 방법이다. (`clean'과 연관된 복잡함은 다른 곳에 기술되었다. section 가짜 목적물(Phony Targets), and section 명령에서 에러(Errors in Commands), 참조.)
묵시적 규칙은 아주 편리하기 때문에 중요하다. 여러분은 자주 사용되는 그것들을 볼 것이다.
Makefile의 다른 스타일(Another Style of Makefile)
makefile의 오브젝트들이 단지 묵시적 규칙에 의해서만 생성된다면 makefile의 다른 대체 스타일이 가능해진다. 이런 makefile 스타일에서 여러분은 그들의 target들에 의해서가 아니라 그들의 dependencies에 의해서 엔트리들을 그룹 짓는다. 여기에 비슷하게 보이는 예제가 있다:
objects = main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
edit : $(objects)
cc -o edit $(objects)
$(objects) : defs.h
kbd.o command.o files.o : command.h
display.o insert.o search.o files.o : buffer.h
여기서 `defs.h'는 모든 오브젝트 파일들의 dependency로 주어졌다; `command.h'와 `buffer.h'는 그것들을 위해서 리스트된 특정 오브젝트 파일들의 dependencies이다.
이것이 더 나은가 아닌가는 취향의 문제이다: 이것이 좀 더 컴팩트하지만 어떤 사람들은 이것을, 그들이 한자리에 각 target에 대한 정보 모두를 넣는 것이 좀 더 분명하다고 생각하기 때문에, 싫어 한다.
디렉토리를 청소하는 규칙(Rules for Cleaning the Directory)
어떤 프로그램을 컴파일하는 것이 여러분이 규칙을 쓰고자 하는 유일한 목적은 아니다. makefile들은 프로그램 하나를 컴파일하는 것 외에 몇 가지 다른 일들을 하는 방법을 보통 얘기한다: 예를 들어서 디렉토리가 `clean'되도록 모든 오브젝트 파일들과 실행 파일들을 지우는 방법.
여기에 우리의 예제 editor를 청소하는 make 규칙을 어떻게 쓸 수 있는가에 대한 예제가 있다:
clean:
rm edit $(objects)
실제로 우리는 예견하지 못한 상황들을 처리하기 위해서 어쩌면 좀 더 복잡한 방법으로 규칙을 쓰려고 할련지도 모른다. 우리는 이것을 할 것이다:
.PHONY : clean
clean :
-rm edit $(objects)
이것은 make가 `clean'이라고 불리는 실제 파일에 의해서 혼동되어지는 것을 막고 rm으로부터의 에러들에도 불구하고 그것이 계속되도록 한다. (section 가짜 목적물(Phony Targets), section 명령에서 에러(Errors in Commands), 참조)
이것과 같은 규칙은 makefile의 맨처음에 위치하면 안된다. 왜냐면 우리는 그것이 디폴트로 실행되기를 원하지 않기 때문이다! 그래서, makefile 예제에서 우리는, 그 에디터를 재컴파일하는, edit에 대한 규칙이 default goal로 남아있기를 원한다.
clean이 edit의 dependency가 아니기 때문에, 이 규칙은 우리가 `make'명령에게 매개변수를 주지 않는다면, 전혀 실행되지 않을 것이다. 이 규칙이 실행되도록 하기 위해서는 `make clean'이라고 입력해야 한다. See section make 실행 방법(How to Run make).
Makefiles 작성(Writing Makefiles)
make에게 makefile이라고 불리는 데이터베이스를 읽어서 그것으로부터 시스템을 재컴파일 하는 방법을 가르켜 주는 정보.
Makefile이 담고 있는 것(What Makefiles Contain)
makefile들은 다섯 가지 종류의 것들을 담고 있다: explicit rules, implicit rules, variable definitions, directives, 그리고 comments. 규칙, 변수, 그리고 지시자 등은 이 후 장들에서 설명될 것이다.
● explicit rule은 이 규칙의 목적물(target)이라고 불리는, 하나 이상의 파일들을 언제 어떻게 리메이크해야 하는지를 말하는 것이다. 이것은 목적물이 depend on 다른 파일들 목록을 갖고 있으며 그 목적물들을 갱신하거나 생성하기 위해서 사용되는 명령들을 갖고 있을 수도 있다. See section 규칙 작성(Writing Rules).
● implicit rule은 그들의 이름에 기초한 어떤 파일들의 클래스를 언제 어떻게 리메이크할 것인가를 말하는 것이다. 이것은, 목적물이 이 목적물과 비슷한 이름을 갖는 파일에 의존할 수 있는 방법을 설명하고 그런 목적물을 갱신하고 생성하기 위한 명령들을 준다. See section 묵시적 규칙(Using Implicit Rules).
● variable definition는, 나중에 텍스트로 대입될 수 있는 변수에 텍스트 문자열을 지정하는 라인이다. 단순 makefile 예제는 모든 오브젝트 파일들의 리스트로써 objects라는 변수 정의를 보여준다 (see section Makefile을 좀 더 쉽게 만드는 변수들(Variables Make Makefiles Simpler)).
● directive는 make가 makefile을 읽으면서 특별한 어떤 것을 하도록 하는 명령이다. 이들은 다음과 같은 것들을 포함한다:
○ 다른 makefile을 읽는다 (see section 다른 makefile 삽입(Including Other Makefiles)).
○ makefile의 일부를 사용할 것인가 아니면 무시할 것인가를 결정한다 (see section Makefile의 조건 부분(Conditional Parts of Makefiles)).
○ 여러 라인들을 포함하는 verbatim 문자열로부터 하나의 변수를 정의(see section 축어 변수 정의(Defining Variables Verbatim)).
● `#'는 comment을 시작한다. 그것과 해당 라인의 나머지 부분은 무시된다. 다른 backslash에 의해서 escape되지 않는 꼬리 backslash는 주석을 여러 라인들에 걸쳐 계속되게 할 것이다. makefile에서 주석은 라인의 어느 곳에서나 나타날 수 있지만, define지시어나 그리고 아마도 명령들 안에서는 예외이다(쉘이 주석이라고 판단하는 곳). 주석만을 갖고 있는(아마 그 앞에 공백들 몇개 있는) 라인은 블랭크이고 무시된다.
여러분의 Makefile에 줄 이름(What Name to Give Your Makefile)
make가 makefile을 찾을 때, 이것은 디폴트로 다음과 같은 이름들을 순서대로 찾으려고 한다: `GNUmakefile', `makefile' 그리고 `Makefile'.
일반적으로 여러분은 여러분의 makefile을 `makefile'이나 `Makefile'로 불러야 할 것이다. (우리는 `Makefile'을 권한다. 왜냐면 그것이 디렉토리 리스팅의 처음 근처에, 다른 `README'와 같은 중요한 파일들 바로 근처에, 우뚝 솟아 보이기 때문이다.) 맨처음 검사되는 파일 `GNUmakefile'은 대부분의 makefile들에 대해서 추천되지 않는 것이다. 여러분은 이 이름을 GNU make에 종속적인 makefile에 대해서만 사용하기 바란다. 그리고 이 이름은 다른 make에 의해서 이해되지 않을 것이다. 다른 make 프로그램들은 `makefile'과 `Makefile' 을 찾지만 `GNUmakefile'은 찾지 않는다.
make가 이런 이름들 중에 어떤 것도 찾지 못하면 어떤 makefile도 사용하지 않는다. 이런 경우 여러분은 명령 매개변수로 어떤 goal을 반드시 지정해야 하고 그러면 make는 그것을 단지 내장된 묵지적 규칙들만을 사용하여서 리메이크하는 방법을 찾아낼 것이다. See section 묵시적 규칙(Using Implicit Rules).
여러분이 makefile에 대해서 비표준 이름을 사용하고자 한다면 makefile 이름을 `-f' 나 `--file'옵션을 사용해서 지정할 수 있다. 매개 변수들 `-f name'나 `--file=name' 은 make에게 makefile로써 name이라는 파일을 읽도록 한다. 하나 이상의 `-f name'나 `--file=name'옵션을 사용하면 여러가지 makefile들을 지정할 수 있다. 모든 makefile들이 지정된 순서대로 연결된다. 디폴트 makefile 이름들, `GNUmakefile',`makefile' 그리고 `Makefile'는 여러분이 `-f name'나 `--file=name'을 지정하면 자동으로 체크되지 않는다.
다른 makefile 삽입(Including Other Makefiles)
include 지시어는 make가 현재 makefile을 읽는 것을 잠시 중단하고 계속하기 전에 하나 이상의 다른 makefile들을 읽도록 한다. 이 지시어는 다음과 같이 보이는 makefile의 한 라인이다:
include filenames...
filenames can contain shell file name patterns.
그 라인의 여분의 공백들은 허용되고 무시되지만, 탭은 허용되지 않는다. (탭으로 그 라인이 시작하면 이것은 명령 라인으로 생각될 것이다.) include와 파일 이름들 사이에 그리고 파일 각각의 이름들 사이에 공백이 필요하다. `#'로 시작하는 주석이 라인의 마지막에 쓰여도 된다. 파일 이름들이 변수나 함수 레퍼런스를 담고 있다면 그들은 확장된다. See section 변수 사용 방법(How to Use Variables).
예를 들어서 여러분이 세 개의 `.mk' 파일들, `a.mk', `b.mk', 그리고 `c.mk'를 가지고 있고, $(bar)가 bish bash로 확장된다면 다음 표현은
include foo *.mk $(bar)
다음의 것과 동일하다.
include foo a.mk b.mk c.mk bish bash
make가 include 지시어를 처리하고 있을 때, 그것은 makefile을 담고 있는 것을 읽는 것을 잠시 중지하고 리스트된 파일들을 순서대로 읽는다. 이것이 끝나면 make는 지시어가 있었던 makefile을 다시 읽는다.
여러가지 디렉토리들에 있는 개개의 makefile들에 의해서 처리되는 다수의 프로그램들이 변수 정의들(see section 변수 설정(Setting Variables))이나 패턴 규칙들(see section 패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules))의 공통 집합을 필요로 할 때가, include 지시어들을 사용하는 한가지 경우이다.
소스 파일들로부터 dependencies를 자동으로 생성하고자 할 때가 다른 그러한 경우이다; dependencies는 주(主) makefile에 의해서 삽입되는 파일에 놓여질 수 있다. 다른 버전의 make와 같이 전통적으로 행해진 것처럼 주 makefile의 마지막에다 dependencies를 추가하는 것보다, 저렇게 하는 것이 훨씬 더 분명하다. See section 종속물들을 자동으로 생성하기(Generating Dependencies Automatically).
지정된 이름이 slash로 시작하지 않고 그 파일이 현재 디렉토리에 없으면 다른 여러 디렉토리들이 검색된다. 먼저, `-I' 또는 `--include-dir' 옵션으로 지정한 임의의 디렉토리들이 검색된다(see section 옵션들의 요약(Summary of Options)). 그리고 나서 다음과 같은 디렉토리들이 이 순서로 (존재한다면) 검색된다: `prefix/include' (일반적으로 `/usr/local/include' (1)) `/usr/gnu/include', `/usr/local/include', `/usr/include'.
삽입된 makefile이 이런 디렉토리들중의 어느 곳에도 찾아질 수 없다면 경고 메시지가 나타나지만 이것은 즉각 치명적인 에러가 아니다; include를 포함하는 makefile의 처리가 계속된다. 일단 makefile들을 읽는 것이 끝나면 `make'는 갱신되어야 하는 것이나 존재하지 않는 것을 리메이크하려고 노력 할 것이다. See section Makefiles가 다시 만들어지는 과정(How Makefiles Are Remade). makefile을 리메이크하는 방법을 찾으려고 노력한 후에 그것이 실패한 경우에만 make는 makefile이 없는 것이 치명적인 에러라고 진단할 것이다.
make가 존재하지 않고 다시 만들어질 수 없는 makefile을 에러 메시지 없이 무시하도록 하고자 한다면 -include 지시어를 다음과 같이 include대신 사용하라:
-include filenames...
이것은 filenames에 있는 어떤 것이 존재하지 않더라도 에러가 없다는 것(경고조차도 없다)을 제외하고는 모든 면에서 include와 동일하게 작동한다. 다른 어떤 make 구현물들과 호환성을 위해서 -include'에 대한 다른 이름 sinclude이 제공된다.
MAKEFILES 변수(The Variable MAKEFILES)
MAKEFILES 환경변수 이 정의되어 있다면,는 그것의 값을, 다른 것들 이전에 읽어야 하는 추가의 makefile 이름들(공백 문자로 분리된) 리스트로써 생각한다. 이것은 include와 아주 비슷하게 작동한다: 여러 디렉토리들이 그런 파일들에 대해서 검색된다(see section 다른 makefile 삽입(Including Other Makefiles)). 나아가 디폴트 목표는 이런 makefile들 중의 하나로부터 절대 얻어지지 않으며 MAKEFILES에 리스트된 파일들이 없어도 에러가 아니다. If the environment variable MAKEFILES is defined, make
MAKEFILES은 `make'의 재귀적인 호출 사이의 통신에서 주로 사용된다(see section make의 재귀적 사용(Recursive Use of make)). make의 톱-레벨 호출 이전에 이 환경변수를 설정하는 것은 일반적으로 권장되지 않는 것이다. 왜냐면 바깥으로부터 makefile을 혼합하지 않는 것이 일반적으로 더 좋기 때문이다. 그러나 make를 특정 makefile 없이 실행할 때, MAKEFILES에 있는 makefile은 검색 패스를 정의하는 것과 같은(see section 종속물을 위한 디렉토리 검색(Searching Directories for Dependencies))좀 더 잘 작동하는 내장 암시 규칙들을 돕는 유용한 일을 할 수 있다.
어떤 사용자들은 로그인할 때 자동으로 환경변수 안에다 MAKEFILES를 설정하여 프로그램 makefile들이 이렇게 되는 것을 기대하도록 하는 유혹을 받는다. 이것은 아주 나쁜 생각이다. 왜냐면 그런 makefile들은 다른 사람에 의해서 실행된다면 실패할 것이기 때문이다. 명시적인 include 디렉티브를 makefile 안에다 쓰는 것이 훨씬 더 좋다. See section 다른 makefile 삽입(Including Other Makefiles).
Makefiles가 다시 만들어지는 과정(How Makefiles Are Remade)
어떤 경우 makefile은 RCS나 SCCS 파일들과 같은 다른 파일들에 의해서 다시 만들어질수 있다. makefile은 다른 파일로부터 다시 만들어질 수 있다면 여러분은 아마도 make가, 읽고 있는 makefile의 최근 버전을 획득하기를 원할 것이다.
이 때문에 모든 makefile들을 읽은 후에 make는 각각의 것을 목표 타겟으로 생각할 것이고 그것을 업데이트하려고 시도할 것이다. makefile이 그것(바로 그 makefile 안에서 아니면 다른 것에서 찾아지는)을 업데이트하는 방법을 말하는 규칙을 가지고 있거나 또는 묵시 규칙이 그것에 적용되는 것이라면(see section 묵시적 규칙(Using Implicit Rules)), (필요하다면) 업데이트될 것이다. 모든 makefile들이 체크된 후에 임의의 것이 실제로 변경되었다면 make는 깨끗한 상태에서 다시 시작해서 모든 makefile들을 다시 읽는다. (그들 각각을 다시 업데이트하려고 시도하겠지만 일반적으로 이것은 그들을 다시 변경하지 않을 것이다. 왜냐면 그들이 이미 업데이트되었기 때문이다.)
makefile들이 명령들은 있지만 종속물들이 없는, 파일을 리메이크할 더블-콜론 규칙을 지정하였다면 그 파일은 항상 다시 만들어질 것이다(see section 더블-콜론 규칙(Double-Colon Rules)). makefile의 이런 경우 명령들은 있지만 종속물들이 없는 더블-콜론을 가진 makefile은 make가 실행할 때마다 다시 만들어질 것이다. 그리고 make가 시작하고 makefile을 다시 읽은 후 반복할 것이다. 이것은 그래서 무한 루프를 발생한다: make는 항상 makefile을 다시 만들것이고 다른 것은 전혀 하지 않을 것이다. 그래서 이것을 피하기 위해서 make는 종속물이 없는 더블-콜론 타켓들로 지정된 makefile들을 다시 만들려고 하지 않을 것이다.
`-f'나 `--file'옵션들을 사용해서 읽을 makefile을 지정하지 않았다면 make는 디폴트 makefile 이름들을 시도할 것이다; see section 여러분의 Makefile에 줄 이름(What Name to Give Your Makefile). `-f'나 `--file'옵션들로 명시적으로 요구된 makefile들과는 달리 make는 이런 makefile들이 존재하는지 모른다. 그러나 디폴트 makefile이 존재하지 않지만 make 규칙들을 실행함으로써 생성될 수 있다면 여러분은 아마도 그 makefile이 사용될 수 있도록 실행될 규칙들을 원할 것이다.
그러므로 디폴트 makefile들 중 어떤 것도 존재하지 않는다면 make는 하나를 만들 때까지 또는 시도할 이름이 없을 때까지 그들이 검색되는 동일한 순서로 그들 중 하나를 만들려고 노력할 것이다(see section 여러분의 Makefile에 줄 이름(What Name to Give Your Makefile)) make가 makefile을 찾을 수 없거나 만들 수 없다는 것은 에러가 아님을 주목하자; makefile은 언제나 필요한 것은 아니다.
`-t'나 `--touch'옵션을 사용할 때 (see section 명령 실행 대신에...(Instead of Executing the Commands)),여러분은 어떤 타켓을 touch할 것인가를 결정하기 위해서 날짜가 지난 makefile을 사용하기를 원치 않을 것이다. 그래서 `-t' 옵션은 makefile들을 업데이트하는 효과가 없다; 그들은 실제로 `-t'가 지정되었다 하더라도 업데이트된다. 비슷하게, `-q' (또는 `--question')과 `-n' (또는 `--just-print') 옵션들은 makefile들의 업데이트를 금지하지 못한다. 왜냐면 out-of-date인 makefile은 다른 타겟들에 대해서 잘못된 결과를 낼 것이기 때문이다. 그래서 `make -f mfile -n foo'라고 하면 `mfile'을 업데이트하고 그것을 읽은 후 실행없이, `foo'와 그것의 종속물들을 업데이트하는 명령들을 디스플레이할 것이다. `foo'에 대해서 디스플레이된 명령들은 `mfile'의 업데이트된 내용안에서 지정된 것들이다.
그러나 때때로 여러분은 실제 makefile들의 갱신을 금지하고자 할런지도 모른다. 여러분은 이것을, makefile들을 명령라인에서 goal로 지정하고 동시에 그들을 makefile들로 지정해서, 할 수 있다. makefile 이름이 명시적으로 goal로써 지정될 때 `-t'과 기타 등등이 그것들에 적용된다.
그래서 `make -f mfile -n mfile foo'는 makefile인 `mfile'를 읽고서 실제로 명령들을 실행하지 않고 이것을 업데이트할 명령들을 디스플레이할 것이다. 그리고 나서 `foo'을 업데이트하는 데 필요한 명령들을 실제로는 실행하지 않고 디스플레이할 것이다. `foo'를 위한 명령들은 `mfile'의 현존하는 내용물에 의해서 지정된 것이 될 것이다.
다른 Makefile의 일부를 오버라이딩(Overriding Part of Another Makefile)
때때로 다른 makefile과 거의 대부분 동일한 makefile을 가지는 것이 유용하다. 여러분은 종종 `include' 지시어를 사용해서 다른 makefile 안에다 makefile 하나를 포함시킬 수 있으며 그래서 더 많은 타겟이나 변수 정의를 포함할 수 있다. 그러나 두 makefile들이 동일한 타겟에 대해서 다른 명령들을 제공한다면 make는 여러분이 이것을 실행하도록 하지 않을 것이다. 그러나 다른 방법이 있다.
담고 있는 makefile(다른 것을 포함하고자 하는 것)안에서 여러분은 담고 있는 makefile에 있는 정보로부터 임의의 타겟을 다시 만들기 위해서 make는 반드시 다른 makefile을 보아야 한다는 것을 말하는 match-anything 패턴 규칙을 사용할 수 있다. 패턴 규칙에 대한 좀 더 많은 정보를 원한다면 See section 패턴 규칙을 정의하고 재정의하기(Defining and Redefining Pattern Rules)를 참조.
예를 들어서 타겟 `foo'(그리고 다른 타겟들)을 만드는 방법을 말하는 `Makefile'라고 불리는 makefile을 가지고 있다면 여러분은 다음과 같은 것을 담고 있는 `GNUmakefile'라는 이름의 makefile을 작성할 수 있다:
foo:
frobnicate > foo
%: force
@$(MAKE) -f Makefile $@
force: ;
`make foo'라고 하면, make는 `GNUmakefile'을 찾아서 그것을 읽고, `foo'를 만들기 위해서는 `frobnicate > foo'라는 명령을 실행해야 한다는 것을 알게 될 것이다. `make bar'라고 하면 make는 `GNUmakefile'에서 `bar'를 만드는 방법을 찾을 수 없을 것이다. 그래서 패턴 규칙으로부터 찾은 명령들을 사용할 것이다: `make -f Makefile bar'. `Makefile'이 `bar'를 업데이트하는 규칙을 제공한다면 make는 그 규칙을 적용할 것이다. 그리고 비슷하게 `GNUmakefile'가 어떻게 만들것인가를 말하지 않는 다른 타겟들도 이런 것이 적용된다.
이것이 작동하는 방법은 패턴 규칙이 `%'와 같은 패턴을 가지고 있어서 임의의 타겟 어떤 것이든 매치된다는 것이다. 이 규칙은 `force'라는 종속물을 가지고 있도록 지정하고 있으며 이것은 타겟 파일이 이미 존재하더라도 명령들이 실행되도록 보장하기 위한 것이다. 우리는 make가 `force' 타겟을 빌드하기 위한 묵시적 규칙을 찾지 못하도록 금지하는, 빈 명령들을 주었다---그렇게 하지 않으면 `force' 자신에다 동일한 match-anything 규칙을 적용해서 종속물 루프를 만들것이다.
규칙 작성(Writing Rules)
rule은 makefile에 나타나고 언제 그리고 어떻게 규칙의 targets(대개 하나의 규칙에 하나만 존재)이라고 불리는 어떤 파일들을 리메이크하는지를 지정한다. 이것은 목적물의 dependencies인 다른 파일들 리스트와 그 목적물을 생성하거나 갱신하는 데 사용될 "명령"을 담고 있다.
규칙들의 순서는, 디폴트 목표(default goal)을 결정하는 것을 제외하고는, 중요한 것이 아니다: 여기서 디폴트 목표(default goal이란 make가, 여러분이 아무것도 지정하지 않는 경우, 생각하는 타겟. 디폴트 목표는 첫번째 makefile의 첫번째 규칙의 타겟이다. 첫번째 규칙이 다수의 타겟들을 가지고 있으면 첫번째 타겟만이 디폴트로 취급된다. 그러나 두가지 예외들이 있다: 점으로 시작하는 타겟은 그것이 하나 이상의 슬래쉬, `/'를 담고 있지 않으면 디폴트가 아니다; 패턴 규칙을 정의하는 타겟은 디폴트 목표에 영향을 미치지 않는다. (See section 패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules).)
그러므로 우리는 보통 첫번째 규칙이, 전체 프로그램 또는 makefile에 의해서 기술된 모든 프로그램들을 컴파일하는 것이 되도록, makefile을 작성한다(종종 `all'라는 이름의 타겟으로). See section goal을 지정하는 매개변수(Arguments to Specify the Goals).
규칙 문법(Rule Syntax)
일반적으로 규칙은 다음과 같이 생겼다:
targets : dependencies
command
...
또는 다음과 같이 생겼다:
targets : dependencies ; command
command
...
targets은 공백으로 분리된 파일 이름들이다. 와일드카드 문자들이 사용될 수도 있으며(see section 파일 이름에 와일드카드 사용(Using Wildcard Characters in File Names)) `a(m)' 형태의 이름은 archive 파일a(see section 타겟으로써 아카이브 멤버(Archive Members as Targets)안에 있는 멤버 m을 표현한다. 일반적으로 규칙 하나당 하나의 타겟이 존재하지만 종종 좀 더 많은 타겟들을 가질 수도 있다(see section 하나의 규칙안의 다수의 타겟들(Multiple Targets in a Rule)).
command 라인들은 탭 문자로 시작한다. 첫번째 명령은 종속물 다음 라인에 탭 문자를 가진 라인으로 나타날 수도 있고 아니면 세미콜론을 가진 동일한 라인에 나타날 수 있다. 양쪽다 그 효과는 동일하다. See section 규칙내 명령 작성(Writing the Commands in Rules).
달러 기호들은 변수 참조를 시작하는 데 사용되기 때문에 여러분이 실제로 규칙에서 하나의 달러 기호를 쓰고자 한다면 달러 두개 `$$'를 반드시 써야 한다(see section 변수 사용 방법(How to Use Variables)). 여러분은 기다란 라인을 백슬레시 더하기 개행 문자를 넣어서 분할할 수 있지만 이것은 반드시 필요한 것이 아니다. 왜냐면 make가 makefile의 각 라인의 최대 길이를 제한하지 않기 때문이다.
규칙은 make에게 두가지 것을 말한다: 타겟들이 언제 out of date인가와 그것들을 필요할 때 어떻게 업데이트할 것인가를 말한다.
out of date인지 아닌지를 판단하는 기준은 DEPENDENCIES 라는 용어로 지정된다. 이것은 공백으로 분리되는 파일 이름들로 구성된다. (와일드카드들과 아카이브 멤버들(see section 아카이브 파일을 갱신하기 위해서 make 사용하기(Using make to Update Archive Files))도 여기서 역시 허용된다.) 타겟은 그것이 존재하지 않거나 종속물들중의 어떤것이라도 이것보다 더 오래된 것이라면 out of date이다(최종-변경 시간을 비교해서). 타겟 파일의 내용물은 종속물들의 정보에 기반을 두고 계산된다는 생각때문에 종속물들 중의 하나라도 변경되면 존재하는 타겟의 내용물은 더이상 유효한 것이 아니다.
업데이트하는 방법은 commands에 의해서 지정된다. 이들은 쉘에 의해서 실행될 라인들이다(일반적으로 `sh'). 그러나 어떤 예외 기능들을 가진다 (see section 규칙내 명령 작성(Writing the Commands in Rules)).
파일 이름에 와일드카드 사용(Using Wildcard Characters in File Names)
하나의 파일 이름은 wildcard characters을 사용해서 많은 파일들을 지정할 수 있다. make에서 와일드카드 문자들은 본 쉘(Bourne shell)과 동일하게 `*', `?' 그리고 `[...]'이다. 예를 들어서, `*.c'는 그것의 이름이 `.c'로 끝나는 모든 파일들(현재 작업 디렉토리 안에서)의 리스트를 지정한다.
파일 이름의 맨 처음에 있는 문자 `~'는 특수한 중요성을 가진다. 혼자 존재하거나 뒤에 slash가 따라오면, 그것은 여러분의 홈 디렉토리를 가르킨다. 예를 들어서 `~/bin'은 `/home/you/bin'으로 확장된다. `~' 다음에 단어 하나가 붙으면 이 문자열은 그 단어로 지정된 사용자의 홈 디렉토리를 표현한다. 예를 들어서 `~john/bin'은 `/home/john/bin'로 확장된다. 각 유저에 대한 홈 디렉토리르 갖지 못하는 시스템들(MS-DOS나 MS-Windows와 같이)에서 이 기능은 환경 변수 HOME를 설정함으로써 비슷하게 작동될 수 있다.
와일드카드 확장은 타겟, 종속물, 그리고 명령(여기서는 쉘이 확장을 한다)에서 자동으로 일어난다. 다른 위치에서 와일드카드 확장은 여러분이 확장이 일어나도록 wildcard함수로 명시했을 때에만 일어난다.
와일드카드 문자의 특별한 용도는 그 앞에다 역슬래시 붙임으로써 꺼질 수 있다. 그래서 `foo\*bar'는 그것의 이름이 `foo', 별표, 그리고 `bar'으로 이루어진 이름의 특정 파일을 참조하는 것이 될 것이다.
와일드카드 예제(Wildcard Examples)
와일드카드들은 규칙의 명령에서 사용될 수 있다. 이곳에서 그들은 쉘에 의해서 확장된다. 예를 들어서 모든 오브젝트 파일들을 삭제하는 규칙을 보자:
clean:
rm -f *.o
와일드카드들은 규칙의 종속물에서도 유용하다. makefile의 다음 규칙에서 `make print' 는 여러분이 그것들을 인쇄한 마지막 시간 이후로 변경된 모든 `.c' 파일들을 인쇄할 것이다:
print: *.c
lpr -p $?
touch print
이 규칙은 `print'를 빈 타겟 파일로 사용한다; section 이벤트를 기록하기 위한 빈 타겟 파일(Empty Target Files to Record Events), 참조. (자동 변수 `$?'는 변경된 파일들만 인쇄하는 데 사용된다; section 자동 변수들(Automatic Variables), 참조.)
여러분이 변수를 정의할 때는 와일드카드 확장이 일어나지 않는다. 그래서 다음과 같이 작성하면:
objects = *.o
objects라는 변수의 값은 `*.o'라는 실제적인 문자열이 된다. 그러나 objects의 값을 타겟에서 사용한다면 종속물이나 명령, 와일드카드 확장은 그 때 일어난다. objects를 확장되게 설정하려면 대신 다음과 같이 써야 한다:
objects := $(wildcard *.o)
See section wildcard 함수(The Function wildcard).
와일드카드를 사용할 때 결점(Pitfalls of Using Wildcards)
다음은 의도한 바대로 작동하지 않는 와일드 카드 확장을 사용하는 간단한 예제이다. 실행 파일 'foo'가 모든 오브젝트 파일들로 부터 만들어지도록 하기 위해 다음과 같이 작성했다고 가정하자:
objects = *.o
foo : $(objects)
cc -o foo $(CFLAGS) $(objects)
objects의 값은 실제 문자열 '*.o'이다. 와일드 카드 확장은 'foo'를 위한 규칙에서 일어난다. 그래서 각 현존하는 '.o' 파일은 'foo'의 필요 항목이 되고 필요하면 재컴파일 될 것이다. 그런데 모든 '.o' 파일이 지워져 버렸다면 어떻게 될 것인가. 와일드 카드가 어떤 파일과도 매치되지 않으면 이것은 있는 그대로 남게 된다. 그래서 'foo'는 이상한 이름의 파일 '*.o'에 의존하게 될 것이다. 이런 파일은 존재하지 않을 것이기 때문에 make는 '*.o'를 만드는 방법을 알 수가 없다는 에러를 낼 것이다. 이것은 의도하는 바가 아니다.
실제로 와일드카드 확장의 원하는 결과를 얻는 것이 가능하지만, wildcard 함수와 문자열 치환(substitution)을 포함하여, 좀 더 복잡한 기술들이 필요한다. 이것들은 다음 섹션에서 설명된다.
마이크로소프트 운영체제(MS-DOS와 MS-Windows)는 역슬래쉬를 다음과 같이 경로명에서 디렉토리들을 구분하는 것으로 사용한다:
c:\foo\bar\baz.c
이것은 유닉스-스타일 `c:/foo/bar/baz.c' (`c:' 부분은 소위 드라이브 문자이다)와 동일하다. make가 이런 시스템들 위에서 작동할 때 경로명에서 유닉스-스타일 슬래쉬와 함께 역슬래쉬들을 지원한다. 그러나 이런 지원은 역슬래쉬가 인용부호인, 와일드카드 확장을 포함하지 않는다. 그러므로 여러분은 반드시 이런 경우에 유닉스-스타일 슬래쉬들을 사용해야 한다.
wildcard 함수(The Function wildcard)
와일드 카드는 규칙 안에서 자동으로 확장된다. 그러나 와일드 카드 확장은 일반적으로 변수를 정의할 때, 또는 함수의 매개변수 안에서는, 일반적으로 일어나지 않는다. 그런 장소에서 와일드카드 확장을 하려고 한다면 다음과 같이 wildcard 함수를 사용해야 한다.
$(wildcard pattern...)
이 문자열은 makefile 안의 어떤 곳에서도 사용된다. 주어진 파일 이름 패턴들 중의 하나와 매치되는 현존하는 파일 이름들을 공백으로 분리된 리스트로 만들어 대체한다. 어떤 파일 이름도 패턴과 매치되는 것이 없으면 그 패턴은 wildcard 함수의 결과로부터 제거된다. 이것은 규칙안에서 매치되지 않은 와일드카드가 행동하는 방식과 다르다는 점에 주의하자. 여기서 그들은 무시된다기보다는 있는 그대로 사용된다(see section 와일드카드를 사용할 때 결점(Pitfalls of Using Wildcards)).
wildcard 함수의 한가지 사용법은 한 디렉토리에 있는 모든 C 소스 파일들의 리스트를 획득하는 것이다. 다음과 같이:
$(wildcard *.c)
우리는 C 소스 파일들의 리스트를 `.c' 접미사를 `.o'로 변경해서 오브젝트 파일들의 리스트로 변경할 수 있다. 다음과 같이:
$(patsubst %.c,%.o,$(wildcard *.c))
(여기서 우리는 다른 함수 patsubst를 사용했다. See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).)
그래서 한 디렉토리에 있는 모든 C 파일들을 컴파일하고 이들을 모두 모아서 링크하려고 하는 makefile은 다음과 같이 작성될 수 있다:
objects := $(patsubst %.c,%.o,$(wildcard *.c))
foo : $(objects)
cc -o foo $(objects)
(이것은 C 프로그램들에 대한 묵시적 규칙을 활용하고 있다. 그래서 파일들을 컴파일하는 명시적 규칙들을 작성할 필요가 없다. `='의 변종인 `:='에 대한 설명을 보려면 See section 변수의 두 취향(The Two Flavors of Variables).)
종속물을 위한 디렉토리 검색(Searching Directories for Dependencies)
커다란 시스템들의 경우 바이너리들과 다른 디렉토리에 소스들을 넣는 것이 종종 바람직하다. make의 directory search 기능은 종속물(dependency)을 찾기 위해서 여러 디렉토리들을 자동으로 검색함으로써 이것을 지원한다. 여러분이 디렉토리들 사이로 파일들을 재배포할 때 여러분은 개별 규칙들을 변경할 필요가 없고 검색 패스들만 변경하면 된다.
VPATH: 모든 종속물에 대한 검색 패스(Search Path for All Dependencies)
make의 변수 VPATH의 값은 make가 검색할 디렉토리들의 리스트를 지정한다. 대개의 경우 이 디렉토리들은 현재 디렉토리에는 없는 종속 파일들을 담고 있을 것이다; 그러나 VPATH는 규칙들의 타겟들인 파일들을 포함해서 모든 파일들에 대해서 make가 적용하는 검색 리스트를 지정한다.
그래서 타겟이나 종속물로 리스트된 어떤 파일이 현재 디렉토리에 존재하지 않으면 make는 VPATH에 있는 디렉토리들을 검색한다. 이 디렉토리들 중 하나에서 어떤 파일이 있으면 그 파일은 종속물이 될 것이다 (아래를 참조) 규칙들은 그러면, 종속물 리스트안에 있는 파일들이 모두 현재 디렉토리에 있는 것처럼 이들을 지정할 것이다. See section 디렉토리 검색 쉘 명령 작성(Writing Shell Commands with Directory Search).
VPATH 변수안에 디렉토리 이름들은 콜론이나 공백들로 구분된다. 디렉토리들이 나열된 순서로 make가 검색한다. (MS-DOS와 MS-Windows에서는 세미-콜론들이 VPATH에서 디렉토리 이름들을 구분하는 데 사용된다. 왜냐면 콜론이 드라이브 명 뒤에서 경로명 자체에서 사용될 수 있기 때문이다.)
예를 들어서,
VPATH = src:../headers
이것은 make가 이 순서로 검색하는, 두 디렉토리들, `src'과 `../headers', 을 담고 있는 경로를 지정하고 있다.
VPATH의 이런 값으로 다음 규칙은
foo.o : foo.c
이것이 다음과 같이 쓰여진 것처럼 해석된다:
foo.o : src/foo.c
파일 `foo.c'이 현재 디렉토리에는 없지만 `src' 디렉토리에 있는 것으로 가정하면서 말이다.
vpath 지시어
VPATH 변수와 비슷하게, 좀 더 선택적이게, vpath라는 지시어(소문자를 주목하자)가 있다. 이것은 여러분이 특정한 클래스의 파일 이름들을 위한 검색 경로를 지정하도록 허락한다: 특정 패턴과 매치되는 것들. 그래서 여러분은 한 클래스의 파일 이름들을 위한 검색 디렉토리들을, 다른 파일 이름들에 대해서 다른 디렉토리들(또는 아무것도 지정하지 않을 수 있다)을 제공할 수 있다.
vpath 지시어는 다음과 같은 세가지 형태가 있다:
vpath pattern directories
이것은 pattern와 매치되는 파일 이름들에 대한 검색 경로 directories를 지정한다. directories라는 검색 경로는 검색될 디렉토리들의 리스트이며, VPATH 변수에서 사용된 검색 경로와 비슷하게, 콜론(MS-DOS와 MS-Windows에 대해서는 세미-콜론)과 공백들에 의해서 구분된다.
vpath pattern
이것은 pattern에 연결된 검색 경로를 청소하다.
vpath
이것은 vpath 지시어로 이전에 지정된바 있던 모든 검색 경로들을 삭제한다.
vpath 패턴은 `%' 문자를 담고 있는 문자열이다. 이 문자열은 검색대상인 종속물의 파일 이름과 반드시 매치되어야 하며 `%' 문자는 0개 또는 그이상의 문자들의 임의의 시퀀스와 매치되는 것이다(패턴 규칙에서와 비슷하다; see section 패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules)). 예를 들어서 %.h는 .h로 끝나는 파일들과 매치된다. (어떤 `%'도 없다면 패턴 규칙은 반드시 종속물과 정확하게 매치되어야 한다. 이런것은 유용한 것이 아니다.)
vpath 지시어의 패턴에 있는 `%' 문자는 앞에 역슬래쉬 (`\')로 인용될 수 있다. 다른 식으로 `%' 문자들을 인용할 수 있는 역슬래쉬들은 좀 더 많은 역슬래쉬들로 인용될 수 있다. `%' 문자들을 인용하는 역슬래쉬들이나 다른 역슬래쉬들은 패턴에서 이것이 파일 이름들과 비교되기 전에 제거된다. `%' 문자들을 인용하는 위험에 있지 않는 역슬래쉬들은 간섭받지 않는다.
종속물들이 현재 디렉토리에 존재하지 않을때, vpath 지시어 안의 pattern이 종속물 파일의 이름과 매치된다면, 그 지시어 안의 directories는 VPATH 변수안의 디렉토리와 동일하게(그리고 그 이전에) 검색된다.
예를 들어서
vpath %.h ../headers
이것은 make가 `.h'로 끝나는 이름의 종속물이 현재 디렉토리에 없으면 `../headers' 디렉토리에서 찾도록 말한다.
몇가지 vpath 패턴들이 종속물 파일의 이름과 매치된다면 make는 각 매치되는 vpath 지시어를 하나씩 처리하면서 각 지시어 내에서 언급된 모든 디렉토리들을 검색한다. make는 다수의 vpath 지시어들을 그들이 makefile에 나타난 순서대로 처리한다; 동일한 패턴을 갖는 다수의 지시어들은 각각 다른 것에 대해서 독립적이다.
그래서
vpath %.c foo
vpath % blish
vpath %.c bar
이것은 `foo'에서 `.c'로 끝나는 파일을 찾을 것이고 그 다음에는 `blish', 그 다음에는 `bar'를 찾을 것이다. 반면에 다음
vpath %.c foo:bar
vpath % blish
는 `foo'에서 `.c'로 끝나는 파일을 찾을 것이다. 그 다음은 `bar', 그리고 `blish'를 찾을 것이다.
디렉토리 검색이 수행되는 방법(How Directory Searches are Performed)
어떤 종속물이 디렉토리 검색에서 찾아질 때 타입(general 또는 selective)에 상관없이 찾아진 패스이름은 make가 실제로 종속물 리스트에서 제공한 것들 중의 하나가 아닐 수 있다. 간혹 디렉토리 검색을 통해서 찾아진 패스는 버려진다.
make가 디렉토리 검색을 통해서 찾은 패스를 간직하는가 아니면 버리는가를 결정하는 데 사용하는 알고리즘은 다음과 같다:
1. 타겟 파일이 makefile에서 지정한 패스에 존재하지 않으면 디렉토리 검색이 수행된다.
2. 디렉토리 검색이 성공적이면 그 패스는 간직되고 이 파일은 시험적으로 타겟으로 저장된다.
3. 이 타겟의 모든 종속물들은 이런 동일한 방법을 사용해서 시험된다.
4. 종속물들을 처리한 후, 타겟은 재빌드가 될 필요가 있거나 그렇지 않다:
1) 타겟이 재빌드될 필요가 없다면, 디렉토리 검색 동안 찾아진 파일에 대한 경로는, 이런 타겟을 포함하는 임의의 종속물 리스트에 사용된다. 간단히 말해서 make가 타겟을 재빌드할 필요가 없다면 여러분은 디렉토리 검색을 통해서 찾아진 패스를 사용한다.
2) 타겟이 재빌드될 필요가 있으면 (out-of-date이면), 디렉토리 검색동안 찾아진 경로명은 버려지고, 타겟은 makefile에서지정된 파일 이름을 사용하여 재빌드된다. 간단히 말하면 make가 반드시 재빌드해야 한다면 타겟은 로컬로 재빌드된 디렉토리 검색을 통해서 찾아진 디렉토리에서는 재빌드되지 않는다.
이 알고리즘은 복잡하게 보일수 있지만 실제로 이것은 여러분이 원하는 것과 완전히 똑같은 경우가 많다.
다른 make 버전들은 좀 더 단순한 알고리즘을 사용한다: 파일이 존재하지 않고 디렉토리 검색을 통해서 찾아지면 그 경로명은 항상, 타겟이 빌드되어야 하는가 또는 하지 않아도 되는가에 따라서 사용된다. 그래서 타겟이 재빌드되면 이것은 디렉토리 검색 동안 발견된 경로명에서 생성된다.
사실, 이것이 여러분이 어떤 또는 모든 디렉토리들에 대해서 원하는 행동이라면, 여러분은 GPATH 변수를 사용해서 이것을 maek에게 지정할 수 있다.
GPATH는 VPATH와 동일한 문법과 포멧을 가진다 (즉, 경로명들의 공백 또는 콜론으로 구분된 리스트). out-of-date 타겟이 디렉토리 검색을 통해서 GPATH에 있는 어떤 디렉토리에서 찾아진 것이라면 그 경로명은 버려지지 않는다. 타겟은 확장된 경로를 사용해서 재빌드된다.
디렉토리 검색 쉘 명령 작성(Writing Shell Commands with Directory Search)
종속물(dependency)이 디렉토리 검색을 통해서 다른 디렉토리에서 찾아질 때, 이것은 그 규칙의 명령들ㅇ르 변경할 수 없다; 그들은 작성된 대로 실행된다. 그러므로 여러분은 반드시 명령들이 make가 그것을 찾는 디렉토리에서 종속물들을 찾도록, 조심스럽게 작성해야 한다.
이것은 `$^'와 같은 자동 변수와 함께 이루어진다 (see section 자동 변수들(Automatic Variables)). 예를 들어서 `$^'의 값은 그 규칙의 모든 종속물들의 리스트이다. 이것은 그들이 찾아지는 디렉토리의 이름들을 포함하고 `$@'의 값은 타겟이다. 그래서:
foo.o : foo.c
cc -c $(CFLAGS) $^ -o $@
(변수 CFLAGS는 여러분이 C 컴파일에 대해서 묵시적 규칙으로 플래그 값들을 지정할 수 있도록 존재한다; 우리는 이것을 일관성 때문에 사용했고 그래서 이것은 모든 C 컴파일에 공통으로 영향을 미칠 것이다; see section 묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules).)
종종 종속물들은 헤더 파일들을 같이 포함한다. 이들은 명령안에서 언급하고 싶지 않은 것이다. 자동 변수 `$<'는 단지 첫번째 종속물을 가리킨다:
VPATH = src:../headers
foo.o : foo.c defs.h hack.h
cc -c $(CFLAGS) $< -o $@
디렉토리 검색과 묵시적 규칙들(Directory Search and Implicit Rules)
$code{VPATH}나 vpath로 지정된 디렉토리들에 대한 검색은 묵시적 규칙을 생각할 때에도 또한 일어난다 (see section 묵시적 규칙(Using Implicit Rules)).
예를 들어서 파일 `foo.o'가 어떤 명시적인 규칙도 가지지 않으면, `foo.c'가 존재하지 않으면 이것을 컴파일하는 내장 규칙과 같은, 묵시적 규칙들을 생각한다. 그런 파일이 현재 디렉토리에 없으면 적절한 디렉토리들이 검색된다. `foo.c'가 어떤 디렉토리들 중 하나에 존재하면 (또는 makefile에 언급되었다면), C 컴파일을 위한 묵시적 규칙이 적용된다.
묵시적 규칙들의 명령은 일반적으로 필요해서 자동 변수들을 사용한다; 결과적으로 그들은 어떤 여분의 노력없이도 디렉토리 검색에 의해서 찾아지는 파일 이름들을 사용할 것이다.
링크 라이브러리 디렉토리 검색(Directory Search for Link Libraries)
디렉토리 검색은 링커와 함께 사용되는 라이브러리들에 특별한 방식으로 적용된다. 이 특별한 기능은 여러분이 종속물의 이름이 `-lname'과 같은 형태를 지니도록 작성할 때 동작한다. (여러분은 이상한 어떤 것이 여기서 진행중이다라고 말할 수도 있다. 왜냐면 종속물은 일반적으로 파일의 이름이고 라이브러리의 파일 이름은 `-lname'가 아니라 `libname.a' 처럼 보이기 때문이다.)
어떤 종속물의 이름이 `-lname'의 형태를 가지면 make는 그것을 현재 디렉토리, vpath 검색 경로, VPATH 검색 경로와 매치되도록 지정된 디렉토리들 안에서, 그리고 나서 `/lib', `/usr/lib', 그리고 `prefix/lib' (일반적으로 `/usr/local/lib', 그러나 MS-DOS/MS-Windows 버전의 make는 prefix가 DJGPP 설치 트리의 루트로 정의된 것처럼 작동한다)에서 `libname.a' 파일을 검색함으로써, 특별하게 처리한다.
예를 들어서,
foo : foo.c -lcurses
cc $^ -o $@
는 `cc foo.c /usr/lib/libcurses.a -o foo'가, `foo'가 `foo.c'보다 또는 `/usr/lib/libcurses.a'보다 더 오래된 것이라면, 실행되도록 한다.
가짜 목적물(Phony Targets)
가짜 목적물은 실제로 파일의 이름이 아닌 것이다. 이것은 여러분이 명시적인 요구를 할 때 실행되는 어떤 명령들에 대한 이름이다. 가짜 목적물을 사용하는 데는 두 가지 이유가 있다: 동일한 이름을 가진 파일과 충돌을 피하기 위해서가 하나이고 퍼포먼스를 개선하기 위한 것이 하나이다.
그것의 명령들이 목적 파일을 생성하지 않을 규칙을 만든다면, 그 명령들은 목적물이 다시만들어야 하는 것으로 나타날 때마다 실행될 것이다. 다음은 하나의 예제이다:
clean:
rm *.o temp
rm 명령이 `clean'이라는 이름의 파일을 생성하지 않기 때문에, 아마도 그런 파일은 앞으로 절대 존재하지 않을 것이다. 그러므로, rm 명령은 여러분이 `make clean'이라고 말할 때마다 실행될 것이다.
가짜 목적물은 이 디렉토리에서 `clean'이라는 이름의 파일을 무엇인가가 생성한다면 작업을 멈출 것이다. 그것은 종속물을 갖지 않기 때문에 `clean'이라는 파일은 무조건 가장 최근 것으로 생각될 것이고 그것의 명령들은 절대 수행되지 않을 것이다. 이런 문제를 피하기 위해서 여러분은 명시적으로 가짜가 될 목적물을, 특수한 목적물 .PHONY(see section 특수 내장 타겟 이름(Special Built-in Target Names))를 써서 다음과 같이, 선언할 수 있다:
.PHONY : clean
일단 이렇게 설정하면 `make clean'은 `clean'이라는 이름의 파일의 존재를 신경쓰지 않고서 그 명령들을 실행할 것이다.
가짜 목적물들은 다른 파일들로부터 실제 리메이크될 수 있는 실제 파일을 지칭하는 것이 아니란 것을 알기 때문에, make은 가짜 목적들을 검색하는 묵시적인 규칙을 스킵한다(see section 묵시적 규칙(Using Implicit Rules)). 비록 실제 파일의 존재 여부를 신경쓰지 않더라도, 이것이 바로 가짜 목적물이 퍼포먼스에 좋다고 한 이유이다.
그래서 다음과 같이 여러분은 먼저 clean이 가짜 목적물이다라고 말하는 라인을 쓰고, 규칙을 써야 한다:
.PHONY: clean
clean:
rm *.o temp
포니 타겟은 실제 타겟 파일의 종속물이 되어서는 안된다; 만일 그렇다면, 그것의 명령들이, make가 그 파일을 업데이트할 때마다, 실행될 것이다. 포니 타겟이 실제 타겟의 종속물이 절대로 아닌 한, 포니 타겟 명령들은 포니 타겟이 특수한 goal일 때만 실행될 것이다 (see section goal을 지정하는 매개변수(Arguments to Specify the Goals)).
포니 타겟들은 종속물들을 가질 수 있다. 한 디렉토리가 다수의 프로그램들을 포함하고 있을 때, 이런 프로그램 모두를 하나의 makefile `./Makefile' 안서 기술하는 것이 가장 편하다. 디폴트로 만들어진 타겟이 makefile에서 첫번째가 될 것이기 때문에 이것이 `all'라는 이름의 포니 타겟이 되도록 하고 그것의 종속물로써 모든 개별 프로그램들로 설정하는 것이 일반적이다. 예를 들어서:
all : prog1 prog2 prog3
.PHONY : all
prog1 : prog1.o utils.o
cc -o prog1 prog1.o utils.o
prog2 : prog2.o
cc -o prog2 prog2.o
prog3 : prog3.o sort.o utils.o
cc -o prog3 prog3.o sort.o utils.o
이제 여러분은 `make'가 모든 세개의 프로그램들을 다시 만들도록 할 수 있거나 매개변수로써, 다시 만들 하나를 지정할 수 있다 (`make prog1 prog3'와 같이).
하나의 포니 타겟이 다른 것의 종속물이라면 이것은 다른 것의 서브루틴으로 작동된다. 예를 들어서 다음 `make cleanall' 는 오브젝트 파일들, 차이 파일들, 그리고 `program' 파일을 모두 지울 것이다:
.PHONY: cleanall cleanobj cleandiff
cleanall : cleanobj cleandiff
rm program
cleanobj :
rm *.o
cleandiff :
rm *.diff
명령과 종속물이 없는 규칙(Rules without Commands or Dependencies)
어떤 규칙이 종속물이나 명령이 없고 그 규칙의 타겟이 존재하지 않는 파일이라면 make는 이 타겟을 그것의 규칙이 실행될 때마다 업데이트되어야 할 것으로 생각한다. 그래서 결과적으로 이것에 종속적인 모든 타겟들의 명령은 항상 실행된다.
다음 예제는 이것을 예시한다:
clean: FORCE
rm $(objects)
FORCE:
여기서 타겟 `FORCE'는 특별한 조건을 만족하고 있기 때문에 이것에 종속적인 타겟 `clean'이 그것의 명령을 무조건 실행한다. `FORCE'이라는 이름 자체에는 특별한 것이 없지만 이런 스타일로 사용되는 이름으로 일반적으로 사용된다.
여러분이 볼 수 있는 것처럼 이런 식으로 `FORCE'를 사용하는 것은 `.PHONY: clean'를 사용하는 것과 동일한 결과를 낸다.
`.PHONY'를 사용하는 것은 좀 더 명시적이고 좀 더 효과적이다. 그러나 make의 다른 버전들은 `.PHONY'를 지원하지 않는다; 그래서 `FORCE'는 많은 makefile에서 나타난다. See section 가짜 목적물(Phony Targets).
이벤트를 기록하기 위한 빈 타겟 파일(Empty Target Files to Record Events)
empty target이란 포니 타겟의 변종이다; 이것은 여러분이 때때로 명시적으로 요구하는 액션에 대한 명령을 갖고 있는데 사용된다. 포니 타겟과는 다르게 이런 타겟 파일은 실재 존재할 수 있다; 그러나 그 파일의 내용은 상관이 없다. 그리고 보통 이것은 비어 있다.
빈 타겟의 목적은 이것의 마지막-변경 시간과 함께 그 규칙의 명령들이 마지막으로 수행된 시간을 기록하고자 하는 것이다. 이것은 명령들 중의 하나가 타겟 파일을 업데이트하는 touch 명령이기 때문에 그렇게 한다.
빈 타겟 파일은 반드시 어떤 종속물을 가져야 한다. 여러분이 빈 타겟을 만들라고 요구할 때 명령들은 그 종속물 중의 하나라도 타겟보다 더 최근의 것이어야만 실행된다; 다른말로 하면 종속물이 여러분이 타겟을 만든 이후 변경되었어야만 실행된다. 다음 예제를 보자:
print: foo.c bar.c
lpr -p $?
touch print
이 규칙을 가지고 `make print'하면 소스 파일이 마지막으로 `make print'한 후 변경되었다면, lpr 명령을 실행할 것이다. 자동 변수 `$?'는 변경된 파일들만 인쇄할 때 사용된다 (see section 자동 변수들(Automatic Variables)).
특수 내장 타겟 이름(Special Built-in Target Names)
어떤 이름들은 그들이 타겟으로 나타날 때 특수한 의미를 갖는다.
.PHONY
특수 타겟 .PHONY의 종속물들은 포니 타겟들로 생각된다. 그런 타겟을 생각할 때 make는 그 이름의 파일이 존재하는지 아니면 그것의 최종-변경 시간이 무엇인지 생각하지 않고서 그것의 명령들을 무조건 실행할 것이다.
.SUFFIXES
특수 타겟 .SUFFIXES의 종속물들은 확장자 규칙(suffix rule)을 검사하는 데 사용되는 확장자들의 리스트이다. See section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules).
.DEFAULT
.DEFAULT로 지정된 명령들이 어떤 규칙도 찾을 수 없는 임의의 타겟들에 대해서 사용된다(명시적 규칙이나 묵시적 규칙들). See section 최후의 디폴트 규칙 정의(Defining Last-Resort Default Rules). .DEFAULT 명령들이 지정되면 종속물로 업급된 모든 파일들, 그러나 어떤 규칙의 타겟이 아닌 파일들은 이런 명령들을 실행할 것이다. See section 묵시적 규칙 검색 알고리즘(Implicit Rule Search Algorithm).
.PRECIOUS
.PRECIOUS가 의존하는 타겟들은 다음과 같은 특별한 취급을 받는다: make가 명령 실행 중에 죽거나 인터럽트를 받으면, 그 타겟은 삭제되지 않는다. See section make를 인터럽트 또는 죽이기(Interrupting or Killing make). 또한, 그 타겟이 중간 파일이라면, 더이상 필요하지 않을 때, 일반적인 경우처럼, 삭제되지 않을 것이다. See section 묵시적 규칙의 연쇄(Chains of Implicit Rules). 여러분은 또한 묵시적 규칙의 타겟 패턴(`%.o'와 같은)을 특별한 타겟 .PRECIOUS의 종속 파일로 지정해서 그 파일의 이름과 매치하는 타겟 패턴 매치의 규칙ㅇ 의해서 생성된 중간 파일들을 보존할 수 있다.
.INTERMEDIATE
.INTERMEDIATE가 의존하는 타겟들은 중간 파일들로 취급된다. See section 묵시적 규칙의 연쇄(Chains of Implicit Rules). 종속물이 없는 .INTERMEDIATE는 makefile에서 언급된 모든 타겟들을 중간 파일들로 마킹한다.
.SECONDARY
.SECONDARY가 의존하는 타겟들은 중간 파일들로 취급된다. 단 그들은 자동으로 삭제되지 않는다. See section 묵시적 규칙의 연쇄(Chains of Implicit Rules). 종속물이 없는 .SECONDARY는 makefile에서 언급된 모든 타겟을 secondary로 마킹한다.
.IGNORE
.IGNORE에 대해서 종속물들을 지정하면 make는 그런 특수한 파일들에 대해서 실행한 명령들의 실행에서 발생한 에러들을 무시한다. .IGNORE에 대한 명령들은 의미가 없다. 종속물이 없이 타겟으로써 언급되면 .IGNORE는 모든 파일들에 대한 명령들의 실행에서 발생하는 에러들을 무시하라고 말하는 것이다. 이런 `.IGNORE'의 사용은 역사적인 호환성만을 위해서 지원된다. 이것이 makefile에 있는 모든 명령에 영향을 미치기 때문에 이것은 아주 유용한 것이 아니다; 우리는 여러분이 특정한 명령들에서 에러들을 무시하는 선택적인 방법을 좀 더 사용하기를 권한다. See section 명령에서 에러(Errors in Commands).
.SILENT
.SILENT에 대한 종속물들을 지정한다면 make는 이런 특정 파일들을 다시 만드는 명령들을 실행하기 전에 이들을 디스플레이하지 않을 것이다. .SILENT에 대한 명령들은 의미가 없다. 종속물이 없는 타겟으로써 언급된다면 .SILENT는 그것들을 실행하기 전에 모든 명령들을 디스플레이하지 않도록 말하는 것이다. 이런 `.SILENT'의 사용법은 역사적 호환성만을 위해서 지원되는 것이다. 특정 명령들이 침묵하게 하도록 하기 위해서 좀 더 선택적인 방법을 사용하기를 권장한다. See section 명령 에코(Command Echoing). make의 특정한 실행에 대해서 모든 명령들을 잠잠하게 하기를 원한다면 `-s'나 `--silent' 옵션을 사용하라 (see section 옵션들의 요약(Summary of Options)).
.EXPORT_ALL_VARIABLES
타겟으로써 언급됨으로써 이것은 make가 모든 변수들을, 디폴트로 차일드 프로세스들에게 익스포트하도록 한다. See section 서브-make에 대한 통신 변수(Communicating Variables to a Sub-make).
정의된 묵시적 규칙 접시사가 타겟으로써 나타난다면 이것도 또한 특수 타겟으로 여겨진다. 그래서 `.c.o'와 같은 두 접미사들도 마찬가지이다. 이런 타겟들은 접미사 규칙이다. 이것은 묵시적 규칙들을 정의하는 구식 방법이다(그러나 아직 여전히 널리 사용되고 있는 방법이다). 원칙적으로 어떤 타겟이름이라도 여러분이 이것을 두개로 쪼개서 그 두 부분을 접미사 리스트에다 추가하면, 이런 식으로 특수한 것이 될 수 있다. 실제로, 접미사들은 보통 `.'로 시작하기 때문에 이런 특수 타겟 이름들 또한 `.'로 시작한다. See section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules).
하나의 규칙안의 다수의 타겟들(Multiple Targets in a Rule)
다수 타겟을 가지는 규칙은 하나의 타겟을 가지는(그리고 나머진ㄴ 모두 동일한) 다수의 규칙들을 작성하는 것과 동일하다. 동일한 명령들이 모든 타겟들에 적용되지만 그들의 효과는, 여러분이 명령에다 `$@'를 사용하여 실제 타겟 이름을 대체할 수 있기 때문에, 다양할 수 있다. 규칙은 모든 타겟들에 대해서 동일한 종속물들을 적용한다.
이것은 다음 두가지 경우에 유용하다.
● 여러분은 명령이 없는 종속물들만 원할 수도 있다. 예를 들어서:
kbd.o command.o files.o: command.h
이것은 언급된 세개의 오브젝트 파일들 각각에 추가의 종속물들을 제공한다.
● 모든 타겟들에 대해서 비슷한 명령들이 작옹한다. 이때 명령들은 절대적으로 동일할 필요가 없다. 왜냐면 자동 변수 `$@'가 특정 타겟을 대체하여 명령들을 다시 만들어내는데 사용될 수 있기 때문이다 (see section 자동 변수들(Automatic Variables)). 예를 들어서:
bigoutput littleoutput : text.g
generate text.g -$(subst output,,$@) > $@
이것은 다음과 동일하다
bigoutput : text.g
generate text.g -big > bigoutput
littleoutput : text.g
generate text.g -little > littleoutput
여기서 우리는 (전제로써의) 프로그램인 generate가 두 타입의 결과를 만들것이라고 가정하였다. 하나는, `-big'가 주어진 경우, 다른 하나는 `-little'가 주어진 경우. subst 함수에 대한 설명은 See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
여러분이, 변수 `$@'가 여러분에게 명령들을 변하게 하는 것과 비슷하게, 타겟에 따라서 종속물들을 다르게 하고자 한다고 해보자. 여러분은 하나의 일반적인 규칙안에다 다수의 타겟들을 써서 이렇게 할 수 없다. 그러나 여러분은 이것을 static pattern rule를 사용해서 할 수 있다. See section 정적 패턴 규칙(Static Pattern Rules).
타겟 하나에 대한 여러 규칙(Multiple Rules for One Target)
하나의 파일이 여러 규칙들의 타겟이 될 수 있다. 모든 규칙에서 언급된 모든 종속물들은 그 타겟에 대한 종속물 리스트 하나로 합쳐진다. 타겟이 한 규칙의 임의의 종속물보다 더 오래된 것이라면 그 명령이 실행된다.
하나의 파일에 대해서 실행될 명령들 집합은 하나만 존재할 수 있다. 규칙 하나 이상이 동일한 파일에 대한 명령들을 제공한다면 make는 마지막으로 주어진 명령 집합을 사용하고 에러 메시지를 출력할 것이다. (특별한 경우로써 그 파일의 이름이 점으로 시작하면 에러메시지는 출력되지 않는다. 이런 이상한 행동은 다른 make의 구현과 호환을 이루기 위해서이다.) 여러분의 makefile들을 이런식으로 작성하는 이유는 없다; 그것이 왜 make가 여러분에게 에러 메시지를 주는 이유이다.
종속물만 있는 여분의 규칙이 동시에 많은 파일들에게 여분의 종속물들 제공하는 데 사용될 수 있다. 예를 들어서 만들어지고 있는 모든 컴파일러 결과 파일들의 리스트를 담고 있는 objects라는 이름의 변수를 보통 가진다. 이들중 모두가 `config.h' 파일이 변경되면 반드시 컴파일되어야 한다는 것을 말하는 쉬운 방법은 다음과 같이 작성하는 것이다:
objects = foo.o bar.o
foo.o : defs.h
bar.o : defs.h test.h
$(objects) : config.h
이것은, 실제로 오브젝트 파일들을 만드는 방법을 지정하는 규칙들을 변경하지 않고서 삽입되거나 제거될 수 있다. 또한 추가의 종속물을 간헐적으로 추가하고자 한다면 이것은 사용하기 편리한 폼이 될 것이다.
추가된 종속물들은 make에 대한 명령 매개변수로 여러분이 설정한 변수로 지정될 수 있다는 것이 다른 좋은 좋은 점이다. (see section 변수 겹쳐쓰기(Overriding Variables)). 예를 들어서,
extradeps=
$(objects) : $(extradeps)
이것은 명령 `make extradeps=foo.h'가 `foo.h'를 각 오브젝트 파일에 대해서 종속물로써 생각할 것이지만 이런 매개변수가 없는 평범한 `make'는 그렇지 않을것이라는 것을 의미한다.
하나의 타겟에 대한 명시된 규칙들 중의 어떤 것도 명령들을 갖지 않는다면 make는 어떤 명령들을 찾기 위해서 적용가능한 묵시적 규칙을 검색한다 see section 묵시적 규칙(Using Implicit Rules)).
정적 패턴 규칙(Static Pattern Rules)
정적 패턴 규칙(Static pattern rules)은 다수의 타겟을 지정하고 타겟의 이름에 기반해서 각 타겟에 대한 종속물 이름들을 구축하는 규칙이다. 이것은 다수의 규칙을 가지는 하나의 일반 규칙보다 좀 더 일반적이다. 왜냐면 타겟들이 동일한 종속물들을 가질 필요가 없기 때문이다. 그들의 종속물들은 반드시 비슷(analogous)해야 하지만 반드시 동일(identical)할 필요는 없다.
정적 패턴 규칙의 문법(Syntax of Static Pattern Rules)
다음은 정적 패턴 규칙의 문법이다.
targets ...: target-pattern: dep-patterns ...
commands
...
여기서 targets 리스트는 이 규칙이 적용될 대상 타겟들을 지정한다. 타겟들은 일반 규칙의 타겟과 마찬가지로 와일드카드 문자들을 가질 수 있다 (see section 파일 이름에 와일드카드 사용(Using Wildcard Characters in File Names)).
target-pattern과 dep-patterns은 각 타겟에 대한 종속물들을 계산하는 방법을 말하는 것이다. 각 타겟은 target-pattern에 대해서, 줄기(stem)이라고 불리는, 타겟 이름 부분을 추출하기 위해서 비교된다. 이 줄기는 종속물 이름들을 만들기 위해서 dep-patterns 각각에 대입된다. (각 dep-pattern으로부터 하나씩)
각 패턴은 보통 하나의 `%' 문자를 담고 있다. target-pattern가 타겟 하나와 비교될 때, `%'는 타겟 이름의 임의의 부분과 매치될 수 있다; 이런 부분은 줄기(stem)라고 불린다. 이 패턴의 나머지 부분들은 정확하게 매치되어야 한다. 예를 들엇 타겟 `foo.o'가 패턴 `%.o'와 매치된다. 이 때 `foo'가 줄기이다. `foo.c'와 `foo.out'은 그 패턴과 매치되지 않는다.
각 타겟에 대한 종속물 이름들은 각 종속물 패턴에 있는 `%'에 대한 줄기를 대치함으로써 만들어진다. 예를 들어서 한 종속물 패턴이 `%.c'이라면 줄기 `foo'의 대치는 종속물 이름 `foo.c'를 제공한다. `%'를 갖지 않는 종속물 패턴을 작성하는 것도 합법적이다; (이렇게 쓰는 경우) 이 종속물은 모든 타겟들과 동일하다.
패턴 규칙에 있는 `%' 문자들은 앞에다 역슬래쉬 (`\')로 인용될 수 있다. 딴 방법으로 `%'를 인용할 역슬래쉬들은 좀 더 많은 역슬레쉬들로 인용될 수 있다. `%' 문자들이나 다른 역슬래쉬들을 인용하는 역슬래쉬들은 패턴에서, 이것이 파일이름들에 비교되거나 그것으로 줄기가 대치되기 전에, 제거된다. `%' 문자들을 인용할 위험에 있지 않는 역슬래쉬들은 간섭받지 않는다. 에를 들어서 `the\%weird\\%pattern\\' 패턴은 앞에 `%' 문자를 가진 `the%weird\'를 가지며, `pattern\\' 가 그 뒤에 온다. 마지막에 있는 두개의 역슬래쉬들은 그들이 `%' 문자에 영향을 미치지 않으므로 혼자 남게 된다.
다음은, `foo.o'과 `bar.o' 각각을 대응하는 `.c' 파일로부터 컴파일하는, 예제이다:
objects = foo.o bar.o
all: $(objects)
$(objects): %.o: %.c
$(CC) -c $(CFLAGS) $< -o $@
여기서 `$<'는 종속물의 이름을 갖고 이는 자동 변수이고 `$@'는 타겟의 이름을 갖고 있는 장동 변수이다; see section 자동 변수들(Automatic Variables).
지정된 각 타겟은 타겟 패턴과 반드시 일치해야 한다; 그렇지 않은 각 타겟에 대해서는 경고가 출력될 것이다. 여러분이 파일들의 리스트를 가진다면 이들중 어떤 것들만이 그 패턴과 일치할 것이고 여러분은 filter 함수를 써서 일치하지 않는 파일 이름들을 사용할 수 있다 (see section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis)):
files = foo.elc bar.o lose.o
$(filter %.o,$(files)): %.o: %.c
$(CC) -c $(CFLAGS) $< -o $@
$(filter %.elc,$(files)): %.elc: %.el
emacs -f batch-byte-compile $<
이 예제에서 `$(filter %.o,$(files))'의 결과는 `bar.o lose.o'이고, 첫번째 정적 패턴 규칙은 이런 오브젝트 파일들 각각이 대응하는 C 소스 파일을 컴파일해서 업데이트되도록 한다. `$(filter %.elc,$(files))' 의 결과는 `foo.elc'이다. 그래서 그 파일은 `foo.el'로부터 만들어진다.
다른 예제는 $*를 정적 패턴 규칙안에서 사용하는 방법을 보여준다:
bigoutput littleoutput : %output : text.g
generate text.g -$* > $@
generate 명령이 실행될 때 *는 줄기인 `big'나 `little'로 확장될 것이다.
정적 패턴 규칙 대(對) 묵시적 규칙(Static Pattern Rules versus Implicit Rules)
정적 패턴 규칙은 패턴 규칙으로써 정의된 묵시적 규칙과 많은 면에서 비슷하다 (see section 패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules)). 둘다 타겟에 대한 패턴을 가지고 종속물 이름들을 구축하는 패턴을 가진다. 차이는 make가 규칙이 적용될 때를 결정하는 방법이다.
묵시적 규칙은 그것의 패턴과 일치하는 어떤 타겟에도 적용될 수 있다. 그러나 이것은 그 타겟이 지정된 어떤 명령도 가지지 않을 때, 그리고 종속물들이 찾아질 수 있을 때에만, 적용된다. 하나의 묵시적 규칙보다 많은 것이 적용가능으로 나타난다면 단지 하나만 적용된다; 이 때 그 선택은 규칙들의 순서에 종속적이다.
이에 반해서 정적 패턴 규칙은 여러분이 규칙안에 지정한 정확한 타겟들 리스트에만 적용된다. 이것은 다른 타겟들에는 적용될 수 없으며 지정된 각 타겟에 일정하게 적요된다. 두개의 서로 상충하는 규칙들이 적용되고 이 두개가 명령들을 가진다면 에러이다.
정적 패턴 규칙은 다음과 같은 이유들 때문에 묵시적 규칙보다 더 좋을 수 있다:
● 여러분은 몇개의 파일들에 대해서 이들의 이름이 문법적으로 범주를 가질 수는 없지만 명시적 리스트에 주어질 수 있을 때, 이들의 파일에 대한 일반적인 묵시적 규칙을 오버라이드하고자 할런지도 모른다.
● 여러분이 사용하고 있는 디텍토리들의 정확한 내용물들을 확신할 수 없다면 여러분은 다른 관련없는 파일들이 make로 하여금 잘못된 묵시적 규칙을 사용하도록 할런지 확신할 수 없을 것이다. 그 선택은 묵시적 규칙 검색이 행해지는 순서에 따라 다를 수 있다. 정적 패턴 규칙의 경우 불확실성이 없다: 각 규칙은 정확하게 지정된 타겟에만 적용된다.
더블-콜론 규칙(Double-Colon Rules)
더블-콜론(Double-colon) 규칙은 타겟 이름 뒤에 `:' 대신에 `::'를 사용하여 작성된 규칙을 말한다. 이들은 동일한 타겟이 여러 규칙에서 나타날 때 일반 규칙들과는 다르게 처리된다.
하나의 타겟이 다수의 규칙에서 나타날 때 이런 모든 규칙들은 동일한 타입을 가져야만 한다: 즉, 모두 일반 규칙이거나 모두 더블-콜론 규칙이어야만 한다. 각 더블-콜론 규칙의 명령들은 타겟이 그 규칙의 임의의 종속물보다 더 오래된 것이라면 실행된다. 그래서 더블 콜론 규칙의 모든 것, 또는 임의의 것을 실행하거나, 또는 아무것도 실행시키지 않을 수 있다.
동일한 타겟의 더블-콜론 규칙들은 실제로 완전히 다른 것과 분리된 것이다. 각 더블-콜론 규칙은, 다른 타겟들이 처리되는 것처럼, 개별적으로 처리된다.
하나의 타겟에 대한 더블-콜론 규칙들은 그들이 makefile에 나타난 순서대로 실행된다. 그러나 더블-콜론 규칙들이 실제 의미가 있는 경우는 명령들을 실행하는 순서가 의미가 없는 경우이다.
더블-콜론 규칙들은 어떤면에서는 불명료하고 그렇게 자주 유용한 것이 아니다; 그들은 타겟을 업데이트하는 사용되는 방법이 업데이트를 유발하는 데 사용되는 종속물 파일들에 따라서 다른 경우를 위한 메카니즘을 제공한다. 그리고 그런 경우는 드물다.
각 더블-콜론 규칙은 명령들을 반드시 지정해야 한다; 그렇지 않으면 묵시적 규칙이 사용될 것이다. See section 묵시적 규칙(Using Implicit Rules).
종속물들을 자동으로 생성하기(Generating Dependencies Automatically)
어떤 프로그램을 위한 makefile에서 여러분이 작성하고자 하는 많은 규칙들은 종종 어떤 오브젝트 파일이 다른 헤더 파일에 의존한다는 것만을 말한다. 예를 들어 `main.c'이 #include를 통해서 `defs.h'를 사용한다면 여러분은 다음과 같이 쓸 것이다:
main.o: defs.h
여러분은 make가, `defs.h'가 변할 때마다 `main.o'를 반드시 다시 만들어야 한다는 것을 알게 하기 위해서 이 규칙이 필요하다. 어떤 커다란 프로그램에 대해서는 makefile안에 그런 규칙들 수십개를 작성해야 할 것이다. 그리고, 여러분은 항상 makefile을, #include를 더하거나 제거할 때마다, 조심스럽게 업데이트해야 한다.
이런 고전분투를 피하기 위해서 대부분의 현대 C 컴파일러들은 여러분의 소스 파일에서 #include들을 찾아서, 여러분을 위해서 이런 규칙들 작성할 수 있다. 대개 컴파일러에게 `-M' 옵션을 주어서 이런 일을 할 수 있다. 예를 들어서 다음 명령은:
cc -M main.c
다음과 같은 출력을 생성한다:
main.o : main.c defs.h
그래서 여러분은 더이상 모든 이런 규칙들을 여러분 스스로 작성할 필요가 없다. 컴파일러는 여러분을 위해서 이런 것을 할 것이다.
그런 종속물이 makefile에서 `main.o'를 언급하는 것을 구성한다. 그래서 이것은 묵시적 규칙 검색에 의해서 중간 파일로 절대 생각되어질 수 없다. 이것은 make는 절대 그 파일을 사용한 후에 지우지 않는다는 것을 의미한다.; see section 묵시적 규칙의 연쇄(Chains of Implicit Rules).
구식 make 프로그램들로, 이런 컴파일러 기능을 사용해서 `make depend'과 같은 명령으로 요구에 따른 종속물들을 생성하는 것은 전통적인 현실이었다. 그런 명령은 모든 자동으로-생성된 종속물들을 담고 있는 파일 `depend'를 생성할 것이다; 그리고 나서 makefile은 include를 사용해서 (생성된) 그것을 읽어들인다 (see section 다른 makefile 삽입(Including Other Makefiles)).
GNU make에서는, makefile들을 다시 만드는 기능이, 이런 현실을 구식으로 만든다--여러분은 make에게 명시적으로 종속물들을 다시 생성하도록 말할 필요가 없다. 왜냐면 이것은 항상 out of date인 임의의 makefile을 다시 만들기 때문이다. See section Makefiles가 다시 만들어지는 과정(How Makefiles Are Remade).
우리가 자동 종속물 생성에 대해서 추천하는 방법은 각 소스 파일에 대해서 대응하는 하나의 makefile을 가지는 것이다. 각 소스 파일 `name.c'에 대해서 어떤 파일이 오브젝트 파일 `name.o'인지 나타내는 makefile `name.d'이 존재한다. 이 방법에서 변경된 소스 파일들만이 새로운 종속물들을 생성하기 위해서 다시 스캔될 필요가 있다.
다음은 `name.c'라고 불리는 C 소스 파일로부터 `name.d'라고 불리는, 종속물들로 이루어진 파일 하나(즉, 하나의 makefile)를 생성하기 위한 패턴 규칙이다:
%.d: %.c
$(SHELL) -ec '$(CC) -M $(CPPFLAGS) $< \
| sed '\''s/\($*\)\.o[ :]*/\1.o $@ : /g'\'' > $@; \
[ -s $@ ] || rm -f $@'
패턴 규칙을 정의하는 데 대한 정보를 위해서는 See section 패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules). 쉘에 대한 `-e' 플래그는 $(CC) 명령이 실패하면(0 아닌 상태값으로 exit하면) 즉시 exit하도록 만든다. 보통 쉘은 파이프 라인(이 경우는 sed)에서 마지막 명령의 상태값을 가지고 exit한다. 그래서 make는 컴파일러로부터 0이 아닌 상태값을 보지 못할 것이다.
GNU C 컴파일러로 여러분은 `-M' 플래그 대신 `-MM'를 사용하기를 원할런지 모른다. 이것은 시스템 헤더 파일들에 대해서는 종속물들을 생략하도록 한다. 자세한 것은 See section `Options Controlling the Preprocessor' in Using GNU CC.
sed 명령의 목적은 다음과 같은 것을:
main.o : main.c defs.h
다음과 같은 것으로:
main.o main.d : main.c defs.h
변환하는 것이다(예를 들어서). 이것은 각 `.d'파일이 대응하는 `.o' 파일이 종속하고 있는 모든 소스와 헤더 파일들에 종속하도록 만든다. make는 그러면 소스나 헤더 파일들 중에 임의의 것이 변하면 종속물들을 재생성해야 한다는 것을 알고 있다.
일단 `.d' 파일들을 다시 만드는 규칙을 정의했다면 여러분은 그것들 모두를 읽어 들이기 위해서 include 지시어를 사용한다. See section 다른 makefile 삽입(Including Other Makefiles). 예를 들어서:
sources = foo.c bar.c
include $(sources:.c=.d)
(이 예제는 소스 파일들 `foo.c bar.c'을 종속물 makefile들 `foo.d bar.d'의 리스트로 변환하기 위해서 대치 변수 참조를 사용한다. 대입 참조에 대한 완전한 정보를 위해서는 See section 대입 참조(Substitution References).) `.d'가 다른 것들과 비슷하게 makefile들이기 때문에 make는 그것들을 여러분으로부터 어떤 추가의 작업도 필요로 할 것 없이, 필요하다면 다시 만든다. See section Makefiles가 다시 만들어지는 과정(How Makefiles Are Remade).
규칙내 명령 작성(Writing the Commands in Rules)
규칙의 명령들은 하나 하나씩 실행되는 쉘 명령 라인들로 이루어진다. 각 명령은 반드시 탭 하나로 시작해야 한다. 한 가지 예외는, 첫번째 명령은 목적물-종속물 라인에 세미콜론으로 구분되어 뒤에 붙어있을 수 있다는 것이다. 빈라인들과 주석뿐인 라인들은 명령 라인들 사이 사이에 올 수 있다; 그들은 모두 무시된다. (그러나 하나의 탭으로 시작하는 겉으로 보기에 빈 라인은 실제 빈 라인이 아니다라는 것을 주의하자! 이것은 빈 명령이다;see section 빈 명령 사용하기(Using Empty Commands).)
유저들은 많은 다른 쉘 명령들을 사용할 수 있지만 makefile에 있는 명령들은, makefile이 다른 경우를 지정하지 않았다면, 항상 `/bin/sh'에 의해서 해석된다. See section 명령 실행(Command Execution).
사용되고 있는 쉘이 주석들이 명령 라인에 쓰일 수 있는지 없는지와 그들이 사용하는 문법이 무엇인지를 결정한다. 쉘이 `/bin/sh'이라면 `#'은 라인의 마지막을 늘리는 주석을 시작한다. `#'가 라인의 맨 앞에 올 필요는 없다. `#' 앞에 있는 텍스트는 주석이 아니다.
명령 에코(Command Echoing)
일반적으로 make는 각 명령 라인을 그것이 실행되기 전에 디스플레이한다. 우리는 이것을, 여러분이 그 명령들을 직접 타이핑하는 모양이므로, echoing라고 부른다.
어떤 라인이 `@'로 시작할 때, 그 라인의 에코는 나타나지 않는다. `@'는 명령이 쉘에 전달되기 전에 버려진다. 전형적으로 여러분은 이것을, makefile을 통해서 진행되는 상황을 표시하기 위해 echo와 같은 명령과 같은, 어떤 것을 출력하는 것이 그것의 유일한 하는 일인 명령에 대해서 사용할 것이다:
@echo About to make distribution files
make는 `-n' 또는 `--just-print' 플래그를 받으면 실행 없이 에코만 한다. See section 옵션들의 요약(Summary of Options). 이런 경우 그리고 이런 경우에만 `@'으로 시작하는 명령들조차도 출력된다. 이 플래그는 그것을을 실제로 수행하지 않고서, make가 생각하기에 어떤 명령들이 필요한 것인가를 찾아낼 때 유용하다.
make에 대한 `-s' 또는 `--silent' 플래그는, 마치 모든 명령들이 `@'으로 시작하는 것처럼 모든 에코를 금지시킨다. 종속물이 없는 특수 타겟 .SILENT 규칙은 이것과 동일한 효과를 가진다 (see section 특수 내장 타겟 이름(Special Built-in Target Names)). .SILENT는 `@'가 좀 더 플렉시블하기 때문에 기본적으로 잘 안쓴다.
명령 실행(Command Execution)
타겟을 업데이트하기 위해서 명령들을 실행할 때, 각 라인에 대한 새로운 서브쉘들을 만듬으로써 실행된다. (실제로 make는 결과에 영향을 미치지 않는 지름길을 취할런지도 모른다.)
Please note: 이것은 cd와 같이 각 프로세스에게 로컬인 변수들을 설정하는 쉘 명령들은 다음 명령 라인들에 영향을 미치지 않을 것이다. (2) cde를 사용하고 다음 명령에 영향을 미치기를 원한다면 이 두개를 단일 라인에 넣고 그 가운데 세미콜론을 사용하자. 그러면 make는 그들을 단일 명령으로 생각하고 그들을 같이 쉘에게 전달할 것이다. 예를 들어서:
foo : bar/lose
cd bar; gobble lose > ../foo
여러분이 단일 쉘 명령을 여러 라인들로 분할하고자 한다면 여러분은 마지막 서브라인만 제외하고 모든 라인의 마지막에다 역슬래쉬를 사용해야 한다. 그런 라인들의 시퀀스는 역슬래쉬-개행 시퀀스를 제거함으로써, 그것을 쉘에게 전달하기 전에, 단일 라인으로 조합된다. 그래서 다음은 이전 예제와 동일한 것이다:
foo : bar/lose
cd bar; \
gobble lose > ../foo
쉘로 사용된 프로그램은 변수 SHELL로부터 취해진다. 디폴트로 `/bin/sh'라는 프로그램이 사용된다.
MS-DOS에서 SHELL이 설정되어 있지 않으면 COMSPEC이라는 변수의 값(이것은 항상 설정된다)이 대신 사용된다.
변수 SHELL를 Makefile들에서 설정하는 라인들을 처리하는 것은 MS-DOS의 경우 다르다. 기본 쉘, `command.com', 은 이상하게 그 기능이 많은 제약이 있고 많은 make 사용자들은 대체 쉘을 설치하는 경향이 있다. 그러므로 MS-DOS에서 make는 변수 SHELL의 값을 시험하고 그것의 행동을 그것이 유닉스 스타일 쉘인가 아니면 DOS- 스타일 쉘인가에 따라서 변경한다. 이것은 SHELL이 `command.com'을 가리키더라도 타당성 있는 기능을 제공한다. `command.com'.
SHELL이 유닉스-스타일 쉘을 가리키면 MS_DOS상의 make는 그 쉘이 실제로 찾아질 수 있는 것인가 아닌가를 추가로 검사한다; 그렇지 않다면 이것은 SHELL을 설정한 라인을 무시한다. MS-DOS에서 GNU make는 다음과 같은 위치들에서 쉘을 검색한다:
1. SHELL에 의해서 지정된 정확한 위치에서. 예를 들어서 makefile이 `SHELL = /bin/sh'라고 지정했다면 make는 현재 드라이브의 `/bin' 디렉토리에서 찾을 것이다.
2. 현재 디렉토리.
3. PATH 변수에 있는 각 디렉토리에서 순서대로 검색한다.
이것이 시험한 모든 디렉토리에서 make는 첫번째 특정한 파일(위의 예제에서는 `sh')를 찾는다. 이것이 없으면 실행 파일임을 나타내는 알려진 확장자들 중의 하나를 가지는 파일을 그 디렉토리에서 또한 찾을 것이다. 예를 들어서 `.exe', `.com', `.bat', `.btm', `.sh', 그리고 나머지.
이런 시도들중에 어ㄸ너 것이라도 성공하면 SHELL의 값은 찾아진 쉘의 풀 경로명으로 설정될 것이다. 그러나 이들중 어떤 것도 찾아지지 않으면 SHELL는 변경될 것이고 그래서 이것을 설정한 라인은 효과적으로 무시될 것이다. 이것이, make가 실행하는 시스템에서 그런 쉘이 실제로 설치되었다면, 유닉스-스타일 쉘에 종속적으로 make가 유일하게 지원하는 것이 될 것이다.
이런 쉘에 대한 확장된 검색은 SHELL이 Makefile에서 설정된 경우로 제한된다는 것에 유의하자; 이것이 환경변수로 또는 명령행에서 지정되면 여러분은 유닉스에서 하는 것과 아주 똑같이, 이것을 쉘의 완전한 경로명으로 설정할 것으로 기대된다.
위와 같은 DOS-종속적인 처리의 효과는 `SHELL = /bin/sh'(많은 유닉스 makefile들이 하는 것처럼)라고 말하는 Makefile은 여러분이 PATH의 어떤 디렉토리에 예를 들면 `sh.exe'과 같은 것을 설치해놓았을 경우, 변경없이 MS-DOS에서 사용될 것이다라는 것이다.
대부분의 변수들과는 다르게 SHELL 변수는 절대로 환경변수로부터 설정되지 않는다. 이것은 왜냐면 SHELL 환경변수가 인터렉티브한 사용을 위한 쉘 프로그램에 대한 여러분의 개인적인 선택을 지정할 때 사용되기 때문이다. 이것과 같은 개인적인 선택들이 makefile의 기능들에 영향을 미치지는 것은 아주 안좋을 수 있다. See section 환경으로부터의 변수들(Variables from the Environment). 그러나 MS-DOS와 MS-Windows에서 환경변수 SHELL의 값은 사용된다. 왜냐면 그런 시스템들에서 대부분의 사용자들은 이런 변수를 설정하지 않기 때문이다. 그러므로 make에 의해서 사용되도록 특별히 설정되는 경우가 대부분일 것이다. MS-DOS에서 SHELL의 설정이 make에 대해서 적절하지 않다면 여러분은 변수 MAKESHELL를 make가 사용해야 하는 쉘에 대해서 지정할 수 있다; 이것은 SHELL의 값을 오버라이드할 것이다.
패러럴 실행(Parallel Execution)
GNU make는 여러 명령들을 동시에 실행하는 방법을 알고 있다. 일반적으로 make는 한번에 하나의 명령만을 실행하고 다음의 것을 실행하기전에 그것이 종료될 때까지 기다린다. 그러나 `-j' 또는 `--jobs' 옵션은 make 에게 많은 명령들을 동시에 실행하도록 한다.
MS-DOS에서 `-j' 옵션은 효과가 없다. 왜냐면 그 시스템은 멀티-프로세싱을 지원하지 않기 때문이다.
`-j' 옵션 뒤에 정수가 붙으면 이것은 한 번에 수행할 명령들의 개수를 말한다; 이것은 작업 슬롯(job slots) 의 개수라고 불린다. `-j' 옵션 뒤에 정수로 보이는 것이 없다면 작업 슬롯의 개수에 제한이 없어진다. 작업 슬롯의 디폴트 개수는 1이다. 이것은 순차적인 실행(한번에 하나씩)을 의미한다.
다수의 명령들을 동시에 실행하는 것의 한가지 즐겁지 않은 결과는 모든 명령들의 출력물이 명령들이 그것을 보낼 때 나타난다는 것이다. 그래서 서로 다른 명령들로부터의 메시지들이 여기저기 섞여서 나타난다.
다른 문제는 두 프로세스들이 동일한 장치로부터 입력을 동시에 취할 수 없다는 것이다; 그래서 단지 하나의 명령이 터미널로부터 한 시점에 입력을 받으려고 시도한다. 그래서 make는 하나를 제외한 모든 실행중인 명령들의 표준 입력 스트림들을 무효화할 것이다. 이것은, 여러개의 자식 프로세스들이 있을 경우 대부분의 자식 프로세스들에 대해서 표준 입력으로부터 읽으려고 시도하는 것은 보통 치명적인 에러(`Broken pipe' 시그널)를 만들것이다라는 것을 의미한다
어떤 명령이 유효한 표준 입력 스트림(터미널로부터 올, 또는 여러분이 make의 표준입력을 리다이렉트한 어떤 것이라도 이곳으로부터 올)을 가지고 있는지 예측하는 것은 거의 불가능하다. 처음 명령이 항상 첫번째를 얻을 것이다. 그리고 명령은 하나가 끝난 후 시작한 첫번째 명령이 다음 것을 얻을 것이다. 이런 식으로 계속된다.
우리가 좀 더 나은 대안을 찾는다면 make의 이런 양식이 작동하는 방법을 바꿀 것이다. 그러기 전에 여러분이 병렬 처리 기능을 사용하고 있다면 표준 입력을 사용하는 어떤 명령도 의존해서는 안된다; 그러나 이런 기능을 사용하고 있지 않다면 표준 입력은 모든 명령들에서 일반적으로 잘 작옹한다.
어떤 명령이 실패하고(시그널에 의해서 kill되거나 0이 아닌 상태값을 가지고 exit하고), 에러들이 그 명령에 대해서 무시되지 않으면 (see section 명령에서 에러(Errors in Commands)), 동일한 타겟을 다시 만드는 남은 명령 라인들은 실행되지 않을 것이다. 명령이 실패하고 `-k'나 `--keep-going' 옵션이 주어지지 않으면 (see section 옵션들의 요약(Summary of Options)), make는 실행을 중지한다. 어떤 이유에서건(시그널을 포함해서) 실행중인 자식 프로세스들을 가진 make가 종료하게 되면 그것은 실제로 나가기 전에 자식 프로세스들이 종료하기를 기다린다.
시스템의 부하가 아주 클때 여러분은 아마도 부하가 적을 때보다 더 적은 작업들을 실행하고자 할 것이다. 여러분은 `-l' 옵션을 써서 make에게 한번에 실행할 작업들의 개수를, 평균 부하에 기초해서 제한하도록 지시할 수 있다. `-l' 또는 `--max-load' 옵션은 그 뒤에 부동-소숫점 숫자가 붙는다. 예를 들어서,
-l 2.5
이것은 make가, 평균 부하가 2.5보다 크면 한 작업보다 더 많은 작업을 시작하지 못하도록 할 것이다. 뒤에 숫자가 없는 `-l' 옵션은, 이전에 `-l' 옵션으로 지정된 것이 있다면, 부하 제한을 제거한다.
좀 더 정확하게, make가 하나의 작업을 시작할 때, 그리고 적어도 하나의 실행중인 작업을 가지고 있을 때, 이것은 현재 평균 부하를 측정한다; `-l'로 주어진 제한보다 더 낮지 않다면 make 는 평균 부하가 그 제한보다 낮아질 때까지 혹은 모든 다른 작업들이 종료될 때까지 기다린다.
디폴트로 부하 제한은 없다.
명령에서 에러(Errors in Commands)
각 쉘 명령이 리턴한 후, make는 그것의 종료 상태값을 조사한다. 그 명령이 성공적으로 종료하면 다음 명령 라인이 새로운 쉘에서 실행된다; 마지막 명령 라인이 종료된 후 그 규칙은 종료한다.
에러가 있으면(종료 상태값이 0이 아니면), make는 현재 규칙을 그리고 아마도 모든 규칙들을, 포기한다.
때때로 어떤 명령의 실패가 문제를 가리키는 것은 아니다. 예를 들어서 여러분은 mkdir 명령을 사용해서 어떤 디렉토리의 존재 유무를 검사할 수도 있다. 그런 디렉토리가 이미 존재한다면 mkdir는 에러를 보고할 것이다. 그러나 여러분은 아마도 make가 그것을 신경쓰지 않고 계속하기를 원할 것이다.
명령 라인에서 에러들을 무시하기 위해서 그 라인 텍스트의 시작부분(초기 탭 문자 뒤에)에 `-' 하나를 넣는다. `-'는 명령이 실행을 위해서 쉘로 전달되기 전에 무시된다.
예를 들어서,
clean:
-rm -f *.o
이것은 rm이 어떤 파일을 제거할 수 없다하더라도 계속하도록 한다.
여러분이 make를 `-i'나 `--ignore-errors' 플래그를 써서 실행할 때 에러들이 모든 규칙의 모든 명령들에서 무시된다. makefile에 있는 특수 타겟 .IGNORE에 대한 규칙은, 종속물들이 없을 때, 동일한 효과를 낸다. 에러를 무시하는 이런 방법들은 `-'가 좀 더 유연하기 때문에 구식이 되버렸다.
에러들이 무시되어야 할 때, `-'나 `-i' 플래그 때문에, make는 에러 리턴을 성공처럼 취급한다. 단, 여러분에 그 명령이 exit한 상태 코드를 말해주는 메시지를 출력하고 에러가 무시되었다는 것을 말하는 것외는 그렇다.
make가 무시하도록 요구받지 않은 어떤 에러가 발생하면, 이것은 현재 타겟이 정상적으로 다시 만들어질수 없다는 것을 의미하고, 이것에 직간접적으로 의존하고 있는 다른 어떤 것들도 또한 만들어질 수 없다는 것을 의미한다. 이런 타겟들에 대한 더이상의 어떤 명령들도 실행되지 않을 것이다. 왜냐면 그들의 사전조건(precondition)들이 이루어지지 않았기 때문이다.
일반적으로 make는 이런 상황에서 즉각 포기하여 0이 아닌 상태값을 리턴한다. 그러나 `-k'나 `--keep-going' 플래그가 지정되면 포기하고 0이 아닌 상태값을 리턴하기 전에, make는 계류중인 타겟들의 다른 종속물들을 생각하기 시작하고, 그것들을 필요하다면 다시 만든다. 예를 들어서 한가지 오브젝트 파일을 컴파일할 때 에러가 생긴 후에 `make -k'는 이미 다른 오브젝트 파일들을 링크가하는 것이 불가능할 것이라는 것을 안다하더라도 다른 이런 오브젝트 파일들을 게속 컴파일할 것이다. See section 옵션들의 요약(Summary of Options).
일반적인 행동은 여러분의 목적이 특정한 타겟이 갱신되도록 하는 것이라고 가정한다; 일단 make가 이것이 불가능한 것을 배우게 되면 이것은 그 실패를 즉각 보고할 것이다. `-k' 옵션은, 실제 목적이 프로그램 내에서 만들어진 가능한 많은 변화를 테스트하는 것이라고, 그리고 아마도 몇가지 독립적인 문제들을 찾아서 여러분이 그것들을 다음 컴파일 시도 이전에 교정할 수 있도록 하는 것이라고 말하는 것이다. 이것이 바로 왜 이맥스의 compile 명령이 디폴트로 `-k' 플래그를 전달하는가에 대한 이유이다. @cindex Emacs (M-x compile)
일반적으로 어떤 명령이 실패할 때, 이것이 타겟 타일을 변경하여 버렸다면, 그 파일은 오염된 것이고 사용될 수 없는 것이다---아니면 적어도 이것은 완전히 갱신된 것이 아니다. 그러나 그 파일의 타임스탬프는 이것이 이제 갱신된 것이라고 말한다. 그래서 다음번 make가 실행할 때 이것은 그 파일을 갱신하려고 시도하지 않을 것이다. 이런 상황은 명령이 시그널에 의해서 kill되었을 때와 동일하다; see section make를 인터럽트 또는 죽이기(Interrupting or Killing make). 그래서 일반적으로 해야 할 올바른 일은 그 명령이 그 파일을 변경 시작한 후 실패했다면 그 타겟 파일을 지우는 것이다. .DELETE_ON_ERROR가 타겟으로써 나타나면 make는 이런 일을 할 것이다. 이것은 대개 항상 make가 하였으면 하는 것이지만 이것은 역사적으로 현실적인 것이 아니다; 그래서 호환성을 위해서 여러분은 반드시 이것을 명시적으로 요구해야 한다.
make를 인터럽트 또는 죽이기(Interrupting or Killing make)
make가 치명적인 시그널을 어떤 명령이 실행하고 있을 때, 받는다면 이것은 그 명령이 업데이트하려고 한 타겟 파일을 삭제할 것이다. 이것은 타겟 파일의 마지막-변경 시간이 make가 맨처음 그것을 검사한 이후 변경되었다면 이루어진다.
타겟을 삭제하는 목적은 make가 다음에 실행될 때 확실히 출발선으로부터 다시 만들어지도록 하는 것이다. 왜 이런가? 여러분이 컴파일러가 실행하고 있을 때 Ctrl-c를 입력했다고 그리고 오브젝트 파일 `foo.o'을 작성하기 시작했다고 가정하자. Ctrl-c는 컴파일러를 킬하게 되어 마지막-변경 시간이 소스 파일 `foo.c'보다 더 새로운 불완전한 파일을 만들게 된다. 그러나 make도 또한 Ctrl-c 시그널을 받게 되고 이 불완전한 파일을 삭제한다. make가 이것을 하지 않는다면 다음 make 호출은 `foo.o'이 갱신이 필요한 파일이 아니라고 생각할 것이다---그래서 이것이 반쯤 부족한 오브젝트 파일을 링크하려고 할 때 링커는 이상한 에러 메시지를 내게 될 것이다.
여러분은 어떤 타겟에 의존하는 특수 타겟 .PRECIOUS을 만듬으로써 이런 식의 타겟 파일의 삭제를 막을 수 있다. 타겟을 다시 만들기 전에 make는 그것이 .PRECIOUS의 종속물들 중에 있는지 없는지를 검사하고 그것에 의해서 그 타겟이 시그널이 발생되었을 때 삭제되어야 하는지 그러지 않는지를 결정한다. 여러분이 이렇게 해야 할 몇가지 이유는 다음과 같다. 타겟은 어떤 소규모 형식으로 갱신된다. 또는 타겟은 변경-시간을 기록하기 위해서만 존재한다(그것의 내용은 상관이 없다). 또는 타겟은 다른 종류의 문제를 막기 위해서 모든 시점에 존재해야만 한다.
make의 재귀적 사용(Recursive Use of make)
make의 재귀적 사용이란 make를 makefile에서 하나의 명령으로 사용한다는 것이다. 이 테크닉은 여러분이 더 큰 시스템을 만드는 여러 서브시스템들을 위한 여러 분리된 makefile들을 원할 때 유용하다. 예를 들어서 여러분이 자신의 makefile을 가지고 있는 `subdir' 서브디렉토리를 가지고 있고 상위 디렉토리의 makefile을 사용해서 그 서브 디렉토리에 대해서 make를 실행하고자 한다고 가정하자. 여러분은 다음과 같이 작성해서 이렇게 할 수 있다:
subsystem:
cd subdir && $(MAKE)
또는 동일하게 다음과 같이 할 수도 있다 (see section 옵션들의 요약(Summary of Options)):
subsystem:
$(MAKE) -C subdir
여러분은 이 예제를 그대로 복사해서 재귀적 make 명령을 작성할 수도 있지만 그들이 작동하는 방식과 이유, 그리고 서브-make가 톱-레벨 make에 어떻게 연결되어 있는가에 대해서 알아야 할 것들이 많이 있다.
여러분의 편의를 위해서 GNU make는 변수 CURDIR를 현재 작업 디렉토리의 경로명으로 설정한다. -C가 쓰였다면 오리지널 디렉토리가 아니라 새로운 디렉토리의 경로를 포함할 것이다. 그값은(CURDIR의 값 ?) 이것이 makefile안에서 설정되었다면 가질 우선순위와 동일하다(디폴트로 환경 변수 CURDIR는 이 값을 오버라이드하지 않을 것이다). 이 변수를 설정하는 것은 make의 작동에 영향을 미치지 않는다.
MAKE 변수가 작동하는 방법(How the MAKE Variable Works)
재귀적인 make 명령들은, 다음에서 볼 수 있듯이 `make' 명령 이름을 명시적으로 쓰지 않고, 항상 MAKE변수를 사용하는 것이 좋다.
subsystem:
cd subdir && $(MAKE)
이 변수의 값은 make가 호출되는 파일 이름이다. 이 파일 이름이 `/bin/make'이라면 실행될 명령은 `cd subdir && /bin/make'일 것이다. 톱-레벨 makefile을 실행하기 위해서 특수한 버전의 make를 사용한다면 동일한 특수한 버전이 재귀적 호출에도 사용될 것이다.
특수한 기능으로써, MAKE를 규칙의 명령에서 사용한다는 것은 `-t' (`--touch'), `-n' (`--just-print'), 또는 `-q' (`--question')옵션의 효과를 변경한다. MAKE변수를 사용하는 것은 명령 라인의 처음에 `+'문자를 사용하는 것과 동일한 효과가 있다. See section 명령 실행 대신에...(Instead of Executing the Commands).
위의 예제에서 `make -t' 라는 명령을 생각해보자. (`-t'옵션은 실제 아무런 명령도 실행하지 않고서도 목적물을 가장 최근의 타임 스탬프를 가지는 것으로 마킹한다; section 명령 실행 대신에...(Instead of Executing the Commands).) `-t'의 일반적인 정의를 따라서, 예제에서 `make -t' 명령은 `subsystem'라는 이름을 가진 파일ㅇ르 하나 생성하고 아무것도 안할 것이다. 여러분이 실제로 원하는 것은 `cd subdir &&' make -t 이다; 그러나 이것은 현존하는 명령을 요구한다. 그래서 `-t'가 명령을 실행하지 말라고 한 것이다.
특수한 기능이 이것을 여러분이 원하는 것으로 만든다: 어떤 규칙의 명령이 변수 MAKE을 담고 있을 때마다 플래그 `-t', `-n' 그리고 `-q'는 그 라인을 적용하지 않는다. MAKE를 담고 있는 명령 라인들은 대부분의 명령이 실행하지 않도록 하는 플래그의 존재에도 불구하고 보통 실행된다. 일반적인 MAKEFLAGS 메카니즘은 플래그들을 서브-make (see section 서브-make에 대한 통신 옵션(Communicating Options to a Sub-make)) 에게 전달하여, 파일을 터치하라는 또는 명령들을 인쇄하라는 여러분의 요구가 서브시스템에 보급된다.
서브-make에 대한 통신 변수(Communicating Variables to a Sub-make)
톱-레벨 make의 변수 값들은 명시적 요구에 의해서 환경을 통해서 서브-make로 전달될 수 있다. 이런 변수들은 서브-make에서 디폴트로 정의되지만 서브-make makefile에 의해서 사용되는, makefile에서 지정된 것을, `-e' 스위치 (see section 옵션들의 요약(Summary of Options))를 사용하지 않으면, 오버라이드하지 않는다.
변수를 전달해주기 위해서 또는 익스포트(export)하기 위해서 make는 각 명령을 실행하기 위해서 환경에다 그 변수와 값을 더한다. 그러면 서브-make는 환경을 사용해서 그의 변수값들의 테이블을 초기화한다. See section 환경으로부터의 변수들(Variables from the Environment).
명시적인 요구를 제외하고, make는 이것이 환경에서 초기에 정의되거나 명령 라인에서 설정된 경우에만, 그리고 그것의 이름이 영문자, 숫자 그리고 밑줄로 이루어졌다면, 익스포트한다. 어떤 쉘들은 영문자, 숫자, 그리고 밑줄이 아닌 문자로 이루어진 환경변수 이름들을 대처하지 못한다.
특수 변수 SHELL과 MAKEFLAGS들은 항상 익스포트된다(그것들을 unexport하지 않았다면). MAKEFILES는 그것을 어떤 것으로 설정하면 익스포트된다.
make는 명령 라인에서 정의된 변수 값들을, MAKEFLAGS 변수에 그들을 넣어서, 자동으로 아래로 전달한다. 다음 섹션을 보자.
변수들이 make에 의해서 디폴트로 생성되었다면 이들은 보통 아래로 전달되지 않는다 (see section 묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules)). 서브-make는 자신을 위해서 이들을 정의할 것이다.
여러분이 특정 변수가 서브-make에 익스포트되기를 원한다면 다음과 같이 export 지시어를 사용하라:
export variable ...
어떤 변수가 익스포트되는 것을 금지하고자 한다면 다음과 같이 unexport 디렉티브를 사용한다:
unexport variable ...
편리하게 여러분은 어떤 변수를 정의하면서 동시에 그것을 익스포트할 수 있다:
export variable = value
이것은 다음과 같은 결과를 가진다:
variable = value
export variable
그리고
export variable := value
는 다음과 같은 결과를 가진다:
variable := value
export variable
비슷하게
export variable += value
는 다음과 동일하다:
variable += value
export variable
See section 변수에 텍스트를 덧붙이기(Appending More Text to Variables).
여러분은 export와 unexport 지시어들이 그들이 쉘에서 작동하는 것과 동일한 방식으로 make에서 작동한다는 것을 알았을 수도 있다.
모든 변수들이 디폴트로 익스포트되는 것을 원한다면 여러분은 export을 다음과 같이 홀로 쓰면 된다:
export
이것은 make에게 export나 unexport 지시어에서 명시적으로 언급되지 않은 변수들은 모두 익스포트되어야 한다는 것을 말한다. unexport 지시어에서 주어진 임의의 변수는 여전히 익스포트되지 않을 것이다. 여러분이 홀로 export만 사용하여 변수들을 디폴트로 익스포트한다면 그것의 이름이 알파벳과 숫자 그리고 밑줄이 아닌 것을 담고 있을 때, 명시적으로 export 지시어에서 언급하지 않는 한, 익스포트되지 않을 것이다.
export 지시어를 홀로 써서 얻어낸 행동은 GNU make의 더 오래된 버전들에서 디폴트이었다. 여러분의 makefile들이 이런 행동에 의존하고 여러분이 make의 예전 버전들과의 호환성을 얻고자 한다면 여려분은 특수한 타겟 .EXPORT_ALL_VARIABLES를 export 지시어를 사용하는 대신 쓸 수 있다. 이것은 오래된 make들에 의해서 무시될 것이다. 반면에 export 지시어는 문법 에러를 유발할 것이다.
비슷하게 여러분은 unexport를 홀로 써서 make가 디폴트로, 변수들을 모두 익스포트하지 않도록 지시할 수 있다. 이것은 디폴트 행동이기 때문에 export가 홀로 이전에(아마 include된 makefile에서) 사용되었을 때에만, 이것을 사용할 필요가 있을 것이다. export과 unexport를 둘다 홀로 써서 어떤 명령들에 대해서 변수들이 익스포트되고 다른 것들에 대해서는 익스포트되지 않도록 할 수 없다. 홀로 사용된 export나 unexport 지시어 중에서 마지막으로 사용된 것만이 make의 전체 실행 행동양식을 결정한다.
특수한 기능으로써, 변수 MAKELEVEL는, 이것이 윗레벨에서 아래레벨로 전달될 때, 변경된다. 이 변수의 값은 레벨의 깊이를 십진수로 표현한 문자열이다. 그 값은 톱-레벨 make에 대해서 `0'이다; 서브-make에 대해서는 `1'이고, 서브-서브-make에 대해서는 `2'이다. 이런 식으로 계속된다. 증가는 make가 어떤 명령에 대한 환경을 셋업할 때 발생한다.
MAKELEVEL의 주요 사용은 조건 지시어 (see section Makefile의 조건 부분(Conditional Parts of Makefiles)) 안에서 그것을 테스트할 때이다; 재귀적으로 실행된다면 한가지 방식으로 작동하고 직접 실행한다면 다른 방식으로 작동하는 makefile을 작성할 수 있다.
변수 MAKEFILES를 사용해서 모든 서브-make 명령들이 추가의 makefile들을 사용하도록 할 수 있다. MAKEFILES의 값은 공백으로 분리된 파일 이름들의 리스트이다. 이 변수는, 외부-레벨 makefile안에서 정의되었다면, 환경을 통해서 아래로 전달된다; 그리고 나서 이것은 서브-make에 대해서, 보통의 또는 지정된 makefile들을 읽도록, 외부 makefile들의 리스트로 취급된다. See section MAKEFILES 변수(The Variable MAKEFILES).
서브-make에 대한 통신 옵션(Communicating Options to a Sub-make)
`-s'와 `-k' 같은 플래그들은 자동으로 변수 MAKEFLAGS를 통해서 서브-make에게 전달된다. 이 변수는 make에 의해서 make가 받는 플래그 문자들을 담고 있도록 자동으로 셋업된다. 그래서 `make -ks'라고 하면 MAKEFLAGS는 값 `ks'를 가진다.
결과적으로 모든 서브-make는 그 환경안에서 MAKEFLAGS에 대한 값을 가진다. 이에 대한 대응으로 그것은 그 값으로부터 플래그들을 취해서 그들이 매개변수로써 전달된 것처럼 이들을 처리한다. See section 옵션들의 요약(Summary of Options).
명령행에서 정의된 변수들과 비슷하게 MAKEFLAGS를 통해서 서브-make에게 전달된다. `='를 담고 있는 MAKEFLAGS의 값의 워드들을 make는 그들이 명령행에 나타난 것처럼, 변수 정의로 취급한다. See section 변수 겹쳐쓰기(Overriding Variables).
`-C', `-f', `-o', 그리고 `-W' 옵션들은 MAKEFLAGS에 들어가지 않는다; 이들 옵션들은 아래로 전달되지 않는다.
`-j' 옵션은 특수한 경우이다 (see section 패러럴 실행(Parallel Execution)). 이것을 어떤 숫자값으로 설정하면 `-j 1'가 항상 지정한 값 대신에 MAKEFLAGS에 들어간다. 이것은 왜냐면, `-j' 옵션이 서브-make들에 들어간다면 요구한 것보다 더 많은 작업들을 병렬로 실행하도록 할 것이기 때문이다. `-j'를 숫자 매개변수 없이 주면 이것은 아래로 전달된다. 왜냐면 다수 무한(multiple infinities)란 1값에 지나지 않기 때문이다.
다른 플래그들은 아래로 전달하고자 하지 않는다면 반드시 다음과 같이 MAKEFLAGS의 값을 변경해야 한다:
subsystem:
cd subdir && $(MAKE) MAKEFLAGS=
명령 라인 변수 정의들은 실제로 MAKEOVERRIDES라는 변수에 나타나고 MAKEFLAGS는 이 변수에 대한 참조를 담고 있다. 플래그들을 정상적으로 아래로 전달하고자 하지만 명령행 변수 정의들은 아래로 전달하고자 하지 않는다면 다음과 같이 MAKEOVERRIDES를 빈 것으로 리셋할 수 있다:
MAKEOVERRIDES =
이렇게 하는 것이 항상 유용한 것은 아니다. 그러나 어떤 시스템들은 환경의 크기가 작게 제한되어 있을 수 있고 많은 정보들을 MAKEFLAGS의 값으로 넣는 것은 이 제한을 넘을수도 있다. `Arg list too long'와 같은 에러 메시지를 본다면 이것이 그런 문제이다. (POSIX.2와의 엄격한 호환을 위해서 MAKEOVERRIDES를 변경하는 것은, 특수 타겟 `.POSIX'이 makefile에 있다면, MAKEFLAGS에는 영향을 미치지 않는다. 여러분은 아마도 이것에 대해서 신경쓰지 않을 것이다.)
비슷한 변수 MFLAGS도 역사적인 호환을 위해서 존재한다. 이것은 명령행 변수 정의들을 담고 있지 않다는 점과, 이것이 빈것이 아니라면 항상 시작한다(MAKEFLAGS는 이것이 such as `--warn-undefined-variables'과 같은 단일-문자 버전이 아닌 옵션으로 시작할 때에만 하이픈으로 시작한다)는 점을 제외하고 MAKEFLAGS과 동일한 값을 가진다. MFLAGS는 전통적으로 재귀적인 make 명령안에서 다음과 같이 명시적으로 사용된다:
subsystem:
cd subdir && $(MAKE) $(MFLAGS)
그러나 이제 MAKEFLAGS는 이런 사용을 여분의 것으로 만들었다. makefile들이 오래된 make 프로그램들에 대해서 호환이 되도록 하기를 원한다면, 이런 테크닉을 사용하자; 이것은 좀 더 현대적인 make 버전들에서도 잘 작동할 것이다.
MAKEFLAGS 변수는, make를 실행할 때마다 설정되는, `-k' (see section 옵션들의 요약(Summary of Options))와 같은 어떤 옵션들을 가지기를 원한다면 유용할 수 있다. makefile안에서, 이 makefile에 대해서 영향을 미쳐야 하는 추가의 프래그들을 지정하기 위해서, MAKEFLAGS를 설정할 수도 있다. (MFLAGS는 이런식으로 사용될 수 없다. 이 변수는 호환성을 위해서만 설정된다; make는 여러분이 이것을 위해서 설정한 값을 어떤식으로든 해석하지 않는다.)
make가 MAKEFLAGS의 값을 해석할 때(환경이나 makefile로부터), 이것은 그 값이 하이픈으로 시작하지 않는다면, 하이픈 하나를 앞에다 먼저 단다. 그리고 나서 그 값을 공백으로 분리된 워드들로 자르고 이들 워드들이 명령행에서 주어진 옵션들인것처럼 이런 워드들을 파싱한다(`-C', `-f', `-h', `-o', `-W', 그리고 긴-이름 버전들은 무시되는 것은 제외; 그리고 무효한 옵션에 대해서 에러는 발생하지 않는다).
MAKEFLAGS를 환경에 넣는다면 make의 행동에 맹렬하게 영향을 미칠, make 자신과 makefile의 목적을 해치는 어떤 옵션들도 넣지 않도록 주의해야 한다. 예를 들어서 `-t', `-n', 그리고 `-q' 옵션들은, 이런 변수들 중의 하나에 넣는다면, 위험한 결과들을 낼 것이고 분명히 적어도 놀라운 아마도 성질내게 만드는 결과들을 얻을 것이다.
`--print-directory' 옵션
재귀적 make 호출의 여러 레벨들을 가진다면 `-w'나 `--print-directory' 옵션은 make가 각 디렉토리를 처리하기 시작할 때와 make가 이것의 처리를 종료할 때 이것을 보여줌으로써 좀 더 이해하기 쉬운 출력을 한다. 예를 들어서 `make -w'가 `/u/gnu/make' 디렉토리안에서 실행되면 make는 다음과 같은 형태의 라인을 출력할 것이다:
make: Entering directory `/u/gnu/make'.
그리고 처리가 완료되면 다른 것을 하기 전에, 다음과 같은 라인을:
make: Leaving directory `/u/gnu/make'.
출력한다.
일반적으로 이 옵션을 지정할 필요가 없다. 왜냐면 `make'가 이것을 대신 하기 때문이다: `-w'는 `-C' 옵션을 사용할 때, 그리고 서브-make들 안에서 자동으로 켜진다. make는 `-s'도 또한 사용한다면 `-w'를 자동으로 켜지 않을 것이다. 이것은 조용히 하라는 옵션이다. 또는 `--no-print-directory' 라는 옵션을 사용해서 명시적으로 그렇게 하는 것을 하지 못하도록 할 수 있다.
명령들을 묶어서 정의하기(Defining Canned Command Sequences)
동일한 명령 시퀀스가 다양한 타겟들을 만드는데 유용할 때, 그것을 define라는 지시어로 묶인 시퀀스(canned sequence)로 정의할 수 있고 그 묶인 시퀀스를 그런 타겟들에 대한 규칙들로부터 참조할 수 잇다. 묶인 시퀀스는 실제로 하나의 변수이다. 그래서 그 이름은 다른 변수 이름들과 같아서는 안된다.
다음은 명령들의 묶인 시퀀스 하나를 정의하는 예제이다:
define run-yacc
yacc $(firstword $^)
mv y.tab.c $@
endef
여기서 run-yacc는 정의되고 있는 변수의 이름이다; endef는 정의의 마지막을 표시한다; 이들 사이의 라인들이 명령들이다. define 지시어는 묶인 시퀀스안에서 변수 참조와 함수 호출들을 확장하지 않는다; `$' 문자들, 괄호들, 변수 이름들, 기타 등등 모두는 정의하고 있는 변수의 값의 일부가 된다. define의 완전한 설명에 대해서, See section 축어 변수 정의(Defining Variables Verbatim).
이 예제의 첫번째 명령은 Yacc를, 이 묶인 시퀀스를 사용하는 규칙의 첫번째 종속물이면 무엇이든지 이것에 대해서, 실행시킨다. Yacc의 결과 파일은 항상 `y.tab.c'라는 이름이다. 두번째 명령은 그 규칙의 타겟 파일 이름으로 이 결과를 덮어쓴다.
묶인 시퀀스를 사용하려면 그 변수를 어떤 규칙의 명령들안에 대입하면 된다. 이것을 다른 변수(see section 변수 참조의 기본(Basics of Variable References)) 들 처럼 대입할 수 있다. define에 의해서 정의된 변수들은 재귀적으로 확장되는 변수들이기 때문에 define안에서 작성하는 모든 변수 참조들은 이때 확장된다. 예를 들어서:
foo.c : foo.y
$(run-yacc)
`foo.y'는 이것이 run-yacc의 값안에 나타날 때, `$^' 변수에 대입되며 `foo.c'가 `$@'에 대해서 대입된다.
이것은 현실적인 예제이지만 이 구체적인 것은 실제의 경우 별로 필요가 없는 것이다. 왜냐면 make는 포함된 파일이름들에 기반해서 이런 명령들을 추측해내는 묵시적 규칙을 갖고 있기 때문이다 (see section 묵시적 규칙(Using Implicit Rules)).
명령 실행에서 묶인 시퀀스이 각 라인은 그 라인이 규칙에 홀로 나타난 것처럼, 앞에 탭 문자를 달고 있는 것처럼, 취급된다. 특별히 make는 각 라인에 대해서 분리된 서브쉘을 호출한다. 여러분은 묶인 시퀀스에 잇는 각 라인의 앞에다 명령 라인들에 영향을 미치는 특수 접두 문자(`@', `-', and `+')들을 사용할 수 있다. See section 규칙내 명령 작성(Writing the Commands in Rules). 예를 들어서 다음과 같은 묶인 시퀀스를 사용해서:
define frobnicate
@echo "frobnicating target $@"
frob-step-1 $< -o $@-step-1
frob-step-2 $@-step-1 -o $@
endef
make는 첫번째 라인, echo 명령 자체를 에코하지 않을 것이다. 그러나 다음 두 라인들은 에코할 것이다.
한편 묶인 시퀀스를 참조하는 명령 라인에 붙은 접두 문자들은 그 시퀀스에 있는 각 라인에 대해서 적용된다. 그래서 다음 라인은:
frob.out: frob.in
@$(frobnicate)
어떤 명령도 에코하지 않는다. (`@'에 대한 완전한 설명에 대해서, See section 명령 에코(Command Echoing).)
빈 명령 사용하기(Using Empty Commands)
아무것도 하지 않는 명령들을 정의하는 것이 때때로 유용하다. 이것은 공백외에 아무것도 없는 명령을 줌으로써 정의될 수 있다. 예를 들어서:
target: ;
이것은 `target'에 대해서 빈 명령 문자열을 정의한다. 또는 빈 명령 문자열을 정의하기 위해서 탭문자로 시작하는 한 라인을 사용할수도 있지만 이것은 그런 라인이 빈것처럼 보이지 않기 때문에 혼동을 일으킬 수 있다.
아무것도 하지 않는 명령을 왜 정의해야 할까에 대해서 의아해 할런지도 모르겠다. 어떤 타겟이 묵시적 명령들(묵시적 규칙들로부터 또는 .DEFAULT 특수 타겟으로부터; see section 묵시적 규칙(Using Implicit Rules) 그리고 see section 최후의 디폴트 규칙 정의(Defining Last-Resort Default Rules))을 얻지 못하도록 하는 것이 그 유일한 이유이다.
실제 파일이 아니지만 그들의 종속물들이 다시 만들어질 수 있도록하기 위해서만 존재하는 타겟들에 대해서 빈 명령 문자열을 곧잘 정의할 수도 있다. 그러나 이것은 그렇게 하기 위한 가장 좋은 방법이 아니다. 왜냐면 종속물들이, 타겟 파일이 실제로 존재한다면, 제대로 다시 만들어지지 않을 것이기 대문이다. 이렇게 하기 위한 좀 더 나은 방법을 찾는다면 See section 가짜 목적물(Phony Targets).
변수 사용 방법(How to Use Variables)
변수(variable)란 그 변수의 값(value)으로 알려진 텍스트 문자열을 표현하기 위해서 makefile에서 정의된 이름이다. 이런 값들은 명시적인 요구에 의해서, 타겟으로, 종속물로, 명령들로, 그리고 makefile의 다른 일부로 대입된다. (make의 다른 어떤 버전들에서는 변수들이 매크로(macros)라고 불린다.)
규칙안에 있는 쉘 명령들을 제외하고, 변수들과 함수들은, `='를 사용한 변수 정의의 오른편을 읽을 때, define 지시어를 사용한 변수 정의의 바디를 읽을 때, 확장된다.
변수들은 파일 이름들 리스트들, 컴파일러에게 전달하는 옵션들, 실행할 프로그램들, 소스 파일들을 찾을 디렉토리들, 결과를 쓸 디렉토리들, 또는 상상할 수 있는 모든 것을, 표현할 수 잇다.
변수 이름은 `:', `#', `=', 또는 시작이나 끝에 공백문자를 담고 있지 않는, 문자들의 임의의 시퀀스일 수 있다. 그러나 알파벳, 숫자, 그리고 밑줄이 아닌 것을 담고 있는 변수 이름들은 피해야 한다. 왜냐면 그들이 미래에 다른 특수한 의미를 가질 수 있기 때문이다. 그리고 어떤 쉘에서는 그들이 환경을 통해서 서브-make에게 전달될 수 없기 때문이다. (see section 서브-make에 대한 통신 변수(Communicating Variables to a Sub-make)).
변수 이름들은 대소문자를 구분한다. `foo', `FOO', 그리고 `Foo'는 모두 서로 다른 변수이다.
변수 이름에 대해서 대문자 알파벳을 사용하는 것이 전통적이지만 makefile 안에서 내부적인 목적으로 사용되는 변수 이름은 소문자 알파벳을 사용하고 묵시적 규칙들을 제어하는 파라미터에 대해서 또는 사용자가 명령 옵션들로 오버라이드(see section 변수 겹쳐쓰기(Overriding Variables))해야 하는 파라미터에 대해서는 대문자로 예약해놓기를 권하는 바이다.
몇가지 변수들이 단일 구두점이나 단지 몇문자들로 이루어진 이름을 가진다. 이런 것들은 자동 변수들(automatic variables)이고 그들은 특별한 특수 용도를 가진다. See section 자동 변수들(Automatic Variables).
변수 참조의 기본(Basics of Variable References)
변수에 값을 대입하기 위해서 변수의 이름을 괄호나 중괄호로 묶은 다음 달러 기호를 앞에 붙인다: `$(foo)' 또는 `${foo}'는 변수 foo에 대한 유효한 참조이다. `$'의 특별한 의미 때문에 파일 이름이나 명령안에서 단일 달러 기호의 효과를 가지기 위해서는 반드시 `$$'를 써야 한다.
변수 참조들은 어떤 문맥 중에서도 사용될 수 있다: 타겟, 종속물, 명령, 대부분의 지시어, 그리고 새로운 변수 값 안에서. 다음은 일반적인 경우의 예제이다. 여기서 변수는 어떤 프로그램의 모든 오브젝트 파일들의 이름들을 갖고 있다:
objects = program.o foo.o utils.o
program : $(objects)
cc -o program $(objects)
$(objects) : defs.h
변수 참조들은 엄격한 텍스트 대입이 일어나는 방식으로 작동한다. 그래서 다음과 같은 규칙은
foo = c
prog.o : prog.$(foo)
$(foo)$(foo) -$(foo) prog.$(foo)
C 프로그램 `prog.c'을 컴파일하는 데 사용될 수 있다. 변수 값 앞에 있는 공백들은 변수 할당에서 무시되기 때문에 foo는 정확하게 `c'이다. (여러분의 makefile을 실제로 이렇게 작성하지 마라!)
달러 기호, 열기-괄호 또는 열기-중괄호가 아닌 하나의 문자 앞에다 달러 기호를 붙이면 이것은 그 단일 문자를 변수 이름으로 취급한다. 그래서 x 변수에 대한 참조로써 `$x'를 사용할 수 있다. 그러나 이런 관례는, 자동 변수(see section 자동 변수들(Automatic Variables))의 경우를 제외하고는 사용되지 않도록 강하게 권장되고 있다.
변수의 두 취향(The Two Flavors of Variables)
GNU make에서 한 변수가 값을 가질 수 있는 방법은 두가지이다; 우리는 이것들을 변수의 두 flavors이라고 부른다. 이 두 취향들은 그들이 확장될 때 무엇을 하는가와 그들이 정의된 방법에 따라서 구분된다.
첫번째 변수 취향은 recursively expanded 변수이다. 이런 종류의 변수들은 `='(see section 변수 설정(Setting Variables))를 사용한 라인들이나 define 지시어 (see section 축어 변수 정의(Defining Variables Verbatim))에 의해서 정의된다. 여러분이 지정한 값은 있는 그대로 설치된다; 이것이 다른 변수들에 대한 참조를 담고 있다면 이런 참조들은 그 변수가 대입될 때마다 확장된다(어떤 다른 문자열을 확장하는 코스에서). 이것이 일어날 때 이것은 recursive expansion라고 불린다.
예를 들어서,
foo = $(bar)
bar = $(ugh)
ugh = Huh?
all:;echo $(foo)
이것은 `Huh?'를 에코한다: `$(foo)'는 `$(bar)'로 확장된다. 그리고 이것은 `$(ugh)'로 확장된다. 그리고 이것은 마지막으로 `Huh?'로 확장된다.
이런 변수의 취향은 다른 make 버전들에 의해서 지원되는 유일한 종류이다. 이것은 장점도 있고 단점도 있다. 장점은(대부분의 사람들이 말하듯이) 다음과 같다:
CFLAGS = $(include_dirs) -O
include_dirs = -Ifoo -Ibar
이것은 원래 의도된 대로 수행할 것이다: `CFLAGS'가 명령안에서 확장될 때, 이것은 `-Ifoo -Ibar -O'로 확장될 것이다. 가장 큰 단점은 변수의 마지막에다 무언가를 덧붙일 수 없다는 것이다. 다음과 같이
CFLAGS = $(CFLAGS) -O
이것은 변수 확장의 무한 루프를 발생할 것이기 때문이다. (실제로 make는 무한 루프를 검출하고서 에러를 보고한다.)
다른 단점은 정의안에서 참조된 임의의 함수(see section 텍스트 변환을 위한 함수(Functions for Transforming Text))가 변수가 확장될 때마다 실행될 것이라는 것이다. 이것은 make가 더 느리게 실행하도록 만든다; 더 나쁜 것은 이것은 wildcard와 shell 함수들이, 그들이 호출될 때 쉽게 제어할 수 없기 때문에 또는 얼마나 많이 호출될 것인가를 제어할 수 없기 때문에 예측할 수 없는 결과를 만들어 낸다.
재귀적으로 확장되는 변수들의 이런 모든 문제점들과 불편함을 피하기 위해서 다른 취향이 있다: 단순하게 확장되는 변수들(simply expanded variables).
Simply expanded variables 는 `:=' (see section 변수 설정(Setting Variables))를 사용해서 정의된다. 단순하게 확장되는 변수의 값은 변수가 정의될 때 다른 변수들과 함수들에 대한 참조를 확장하면서 단 한번만 스캔된다. 단순하게 확장되는 변수의 실제 값은 여러분이 작성한 텍스트를 확장한 결과이다. 이것은 다른 변수에 대한 어떤 참조도 담고 있지 않다; 이것은 그들을 값을 이 변수가 정의되었던 때의 것과 같은 것으로 갖는다. 그래서
x := foo
y := $(x) bar
x := later
는 다음과 같다:
y := foo bar
x := later
단순하게 확장된 변수가 참조될 때 그것의 값은 있는 그대로 대입된다.
다음은 좀 더 복잡한 예제인데, shell 함수(See section shell 함수(The shell Function).)와 `:='를 결합해서 사용하는 것을 예시한 것이다. 이 예제는 또한 변수 MAKELEVEL에 대한 사용을 보여준다. 이 변수는 이것이 한 레벨에서 다른 레벨로 지나갈 때 변하는 것이다. (MAKELEVEL에 대한 정보에 대해서는 See section 서브-make에 대한 통신 변수(Communicating Variables to a Sub-make).)
ifeq (0,${MAKELEVEL})
cur-dir := $(shell pwd)
whoami := $(shell whoami)
host-type := $(shell arch)
MAKE := ${MAKE} host-type=${host-type} whoami=${whoami}
endif
`:='의 이런 사용의 장점은 전형적인 `디렉토리 안으로 들어가는' 명령이 다음과 같이 보일 때이다:
${subdirs}:
${MAKE} cur-dir=${cur-dir}/$@ -C $@ all
단순 확장 변수들은 일반적으로 복잡한 makefile 프로그래밍을 좀 더 예측가능하도록 만든다. 왜냐면 이들은 대부분의 프로그래밍 언어에서의 변수들처럼 작동하기 때문이다. 그들은 어떤 변수를 자신의 값(또는 확장 함수들 중의 하나에 의해서 어떤 방식으로 처리된 이것의 값)을 사용하여 재정의할 수 있도록 하며 확장 함수들을 좀 더 효율적으로 사용할 수 있도록 한다 (see section 텍스트 변환을 위한 함수(Functions for Transforming Text)).
또한 이들을 사용해서 제어된 선두 공백문자(controlled leading whitespace)를 변수 값들로 채용할 수 있다. 선두 공백문자들은 입력에서, 변수 참조와 함수 호출들의 대입이 있기 이전에, 제거된다; 이것은 선두 공백문자들을 다음과 같이 변수 참조로 막음으로써 변수 값안에 선두 공백문자들을 넣을수 있다는 것을 의미한다:
nullstring :=
space := $(nullstring) # end of the line
여기서 변수 space의 값은 정확히 하나의 스페이스이다. `# end of the line' 주석은 여기에서 명확성을 위해서 들어가 있는 것이다. 뒤에 있는 공백문자들이 변수 값들로부터 제거되지 않기 때문에 라인의 마지막에 있는 하나의 스페이스가 동일한 효과를 가질 것이다(그러나 좀 더 읽기가 힘들다). 공백 문자를 변수 값의 마지막에다 넣는다면 라인의 마지막에서 저것과 같이 주석을 넣는 것이, 여러분의 의도를 명확하게 하기 위해서, 좋은 생각이다. 역으로 변수 값의 마지막에다 임의의 공백 문자들을 넣고자 하지 않는다면, 다음과 같이 라인의 마지막에다 몇개의 공백 문자 뒤에 아무데나 주석을 넣지 않도록 반드시 기억하자:
dir := /foo/bar # directory to put the frobs in
여기에서 dir 변수의 값은 `/foo/bar '이다(네개의 뒤에 붙은 스페이스들과 함께). 이것은 아마도 의도한 바가 아닐 것이다. (이 정의하에서 `$(dir)/file'과 같은 것을 상상해보라!)
변수들에 대한 다른 할당 연산자 `?='가 있다. 이것은 조건 변수 할당 연산자(conditional variable assignment operator)라고 불린다. 왜냐면 이것은 그 변수가 아직 정의되지 않았을 경우에만 효력을 가지기 때문이다. 다음 문장은:
FOO ?= bar
다음과 정확하게 동일하다 (see section origin 함수(The origin Function)):
ifeq ($(origin FOO), undefined)
FOO = bar
endif
빈 값으로 설정된 변수도 여전히 정의된 것이기 때문에, `?='는 그 변수를 설정하지 않는다는 것에 주의하자.
변수 참조의 고급 기능(Advanced Features for Reference to Variables)
이 섹션은 좀 더 유연한 방식으로 변수들을 참조하는 데 사용할 수 있는 고급 기능들을 몇가지 설명한다.
대입 참조(Substitution References)
substitution reference(대입 참조)는 한 변수의 값을 지정하는 다른 대체값으로 대입한다. 이것은 `$(var:a=b)' (또는 `${var:a=b}') 형식이며 이것의 의미는, 변수 var의 값을 취해서 한 단어의 뒤에 있는 각 a를 그 값안에 있는 b로 교체하고 결과 문자열을 대입한다는 것을 의미한다.
우리가 "한 단어의 뒤에 있는"이라고 말할 때, 우리는 a가 대체되기 위해서는, 이것이 공백문자가 뒤에 있도록 또는 그 값의 마지막에 있도록 나타나야 한다는 것을 의미한다는 것이다; 그 값안에서 다른 위치에 있는 a는 변경되지 않을 것이다. 예를 들어서:
foo := a.o b.o c.o
bar := $(foo:.o=.c)
이것은 `bar'를 `a.c b.c c.c'로 설정한다. See section 변수 설정(Setting Variables).
대입 참조는 실제로 patsubst 확장 함수 (see section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis))의 사용의 축소판이다. 우리는 대입 참조를, 다른 make 구현물과의 호환성을 위해서, patsubst과 함께 제공한다.
대입 참조의 다른 타입은 patsubst의 풀 파워를 사용할 수 있도록 한다. 이것은 위에서 기술된 `$(var:a=b)'과 동일한 형식을 가진다. 다만 이제는 a가 반드시 단일 `%'를 반드시 담아야 한다는 점을 제외하고 말이다. 이런 경우는 `$(patsubst a,b,$(var))'와 동일하다. patsubst 함수 설명은 See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
For example:
foo := a.o b.o c.o
bar := $(foo:%.o=%.c)
이것은 `bar'를 `a.c b.c c.c'로 설정한다.
계산된 변수 이름(Computed Variable Names)
계산된 변수 이름들은 정교한 makefile 프로그래밍에서나 필요한 복잡한 개념이다. 대부분의 목적의 경우 이것들을 생각할 필요가 없다. 단 변수의 이름안에 달러 기호를 넣는 것은 심각한 결과를 만들어낼 수 있다는 것을 아는 것을 제외하고 말이다. 그러나 여러분이 모든 것을 이해하기를 원하는 타입의 사람이라면 또는 실제로 그들이 무엇을 하는지 이해하고자 한다면 계속 읽기 바란다.
변수들은 하나의 변수 이름안에서 참조될 수 있다. 이런 것을 우리는 계산된 변수 이름(computed variable name) 또는 포개진 변수 참조(nested variable reference)라고 부른다. 예를 들어서,
x = y
y = z
a := $($(x))
이것은 a를 `z'로 정의한다: `$($(x))'안에 있는 `$(x)'는 `y'로 확장되기 때문에 `$($(x))'는 `$(y)'로 확장되고 이것은 다시 `z'로 확장된다. 여기서 참조하는 변수의 이름은 명시적으로 언급되지 않았다; 이것은 `$(x)'의 확장에 의해서 계산되었다. `$(x)' 참조는 바깥 변수 참조에 안에 포개져 있다.
이전 예제는 두 레벨의 포갬을 보여준 것이지만 임의의 레벨도 가능하다. 예를 들어서 다음은 세단계 레벨이다:
x = y
y = z
z = u
a := $($($(x)))
여기서 가장 안쪽에 있는 `$(x)'는 `y'로 확장되고 그래서 `$($(x))'는 `$(y)'로 확장되며 이것은 다시 `z'로 확장된다; 이제 우리는 `$(z)'를 가진다. 이것은 `u'이 된다.
하나의 변수 이름 안에서 재귀적으로-확장되는 변수들에 대한 참조는 일반적인 스타일로 다시 확장된다. 예를 들어서:
x = $(y)
y = z
z = Hello
a := $($(x))
이것은 a를 `Hello'로 정의한다: `$($(x))'는 `$($(y))'이 되고 이것은 `$(z)'이 되며 이것은 다시 `Hello'가 된다.
포개진 변수 참조들은 다른 참조들과 마찬가지로 변경된 참조들과 함수 호출들 (see section 텍스트 변환을 위한 함수(Functions for Transforming Text))을 가질 수 있다. 예를 들어서 subst 함수 (see section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis))를 사용하는 다음 예제는:
x = variable1
variable2 := Hello
y = $(subst 1,2,$(x))
z = y
a := $($($(z)))
결국 a를 `Hello'로 정의한다. 이것과 같이 둘둘 꼬인 포개진 참조를 쓰고자 하는 사람이 있을런지 의심스럽지만 이것은 잘 작동하는 것이다: `$($($(z)))'는 `$($(y))'로 확장된다. 그리고 이것은 다시 `$($(subst 1,2,$(x)))'이 된다. 이것은 x로부터 `variable1' 값을 얻어서 `variable2'로 대입해서 이것을 변경한다. 그래서 전체 문자열은 `$(variable2)'이 된다. 그리고 이것은 그것의 값이 `Hello'인 단순 벼수 참조이다.
계산된 변수 이름은 단일 변수 참조로 완전히 이루어질 필요가 없다. 이것은 몇개의 변수 참조들을, 몇가지 불변 텍스트와 함께, 가질 수 있다. 예를 들어서, 다음은
a_dirs := dira dirb
1_dirs := dir1 dir2
a_files := filea fileb
1_files := file1 file2
ifeq "$(use_a)" "yes"
a1 := a
else
a1 := 1
endif
ifeq "$(use_dirs)" "yes"
df := dirs
else
df := files
endif
dirs := $($(a1)_$(df))
dirs에게 use_a와 use_dirs의 설정에 종속적으로, a_dirs, 1_dirs, 또는 1_files와 동일한 값을 줄 것이다.
계산된 변수 이름들은 또한 대입 참조에서 다음과 같이 사용될 수 있다:
a_objects := a.o b.o c.o
1_objects := 1.o 2.o 3.o
sources := $($(a1)_objects:.o=.c)
이것은 sources를, a1의 값에 따라서, `a.c b.c c.c'나 `1.c 2.c 3.c'로 정의한다.
포개진 변수 참조들의 이런 종류의 사용에 대한 유일한 제한은 그들이 호출된 함수의 이름의 일부를 지정할 수 없다는 것이다. 이것은 인식된 함수 이름에 대한 테스트가 포개진 참조들의 확장 이전에 이루어지기 때문이다. 예를 들어서,
ifdef do_sort
func := sort
else
func := strip
endif
bar := a d b g q c
foo := $($(func) $(bar))
이것은 sort나 strip 함수에게 매개변수로써 `a d b g q c'를 주지 않고, `foo'에게 변수 `sort a d b g q c'나 `strip a d b g q c' 의 값을 준다. 이런 제한은, 그런 변화가 좋은 아이디어라고 보여질 경우 제거될 수도 있다.
변수 할당의 왼쪽편에서, 또는 define 지시어 안에서 다음과 같이 계산된 변수 이름들을 사용할수도 있다:
dir = foo
$(dir)_sources := $(wildcard $(dir)/*.c)
define $(dir)_print
lpr $($(dir)_sources)
endef
이 예제는 변수 `dir', `foo_sources', 그리고 `foo_print'를 정의한다.
포개진 변수 참조(nested variable references)는 재귀적으로 확장된 변수(recursively expanded variables) (see section 변수의 두 취향(The Two Flavors of Variables)) 와, 비로 이들 모두 makefile 프로그래밍을 할 때 아주 복잡한 방식으로 사용되지만, 많이 다르다는 것을 주목하자.
변수가 값을 얻는 방법(How Variables Get Their Values)
변수들은 다음과 같은 몇가지 방법으로 값들을 얻을 수 잇다:
● make를 실행할 때 값을 지정하거나 오버라이드할 수 있다. See section 변수 겹쳐쓰기(Overriding Variables).
● 할당(assignment) (see section 변수 설정(Setting Variables)) 또는 축어적(verbatim) 정의 (see section 축어 변수 정의(Defining Variables Verbatim)) 등으로 makefile안에서 값을 지정할 수있다.
● 환경의 변수들이 make 변수들이 된다. See section 환경으로부터의 변수들(Variables from the Environment).
● 몇가지 자동(automatic) 변수들이 각 규칙에 대해서 새로운 값들을 받는다. 이런것 각각은 단일 Several automatic variables are given new values for each rule. Each of these has a single conventional use. See section 자동 변수들(Automatic Variables).
● 몇가지 변수들이 상수 초기값들을 가진다. See section 묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules).
변수 설정(Setting Variables)
makefile로부터 변수를 설정하기 위해서는 `='나 `:='가 뒤에 붙은 변수 이름으로 시작하는 라인을 작성한다. 그 라인에서 `='나 `:=' 뒤에 오는 것은 무엇이든 값(value)이 된다. 예를 들어서 다음은,
objects = main.o foo.o bar.o utils.o
objects라는 이름의 변수를 정의한다. 변수의 주변에 있는 공백문자들, `=' 뒤에 있는 공백문자들은 무시된다.
`='로 정의된 변수들은 재귀적으로 확장된(recursively expanded) 변수들이다. `:='로 정의된 변수들은 단순하게 확장된(simply expanded) 변수드이다; 이들 정의들은 이 정의가 만들어지기 이전에 확장되었을 변수 참조들을 담을 수있다. See section 변수의 두 취향(The Two Flavors of Variables).
변수 이름은 함수와 변수 참조들을 가질 수 있다. 이들은 그 라인이 사용할 실제 변수 이름을 찾기 위해서 읽혀질 때 확장된다.
한 변수의 값의 길이는 제한이 없다. 단 컴퓨터의 스와핑 공간의 크기에 종속적이다. 어떤 변수 정의가 길면 그것을 몇개의 라인들로 나누고 원하는 위치에 역슬래쉬-개행문자를 넣어서 쪼개는 것도 좋은 생각이다. 이것은 make의 기능에 영향을 미치지 않고 makefile이 좀 더 읽히기 쉽도록 만들 것이다.
대부분의 변수 이름들은 그것을 전혀 설정하지 않으면, 값으로써 빈 문자열을 가지는 것으로 생각된다. 몇가지 변수들이 빈 것이 아닌 내장 초기 값들을 가지지만 여러분은 그것들을 일반적인 방식으로 설정할 수 있다 (see section 묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules)). 몇가지 특수 변수들이 각 규칙에 대해서 새로운 값으로 설정된다; 이런 것들은 자동(automatic) 변수라고 한다 (see section 자동 변수들(Automatic Variables)).
어떤 변수가 그것이 앞서 설정되지 않았을 경우에만 어떤 값으로 설정되기를 원한다면 `=' 대신에 단축 연산자 `?='를 사용할 수 있다. 다음 `FOO' 변수의 두가지 설정들은 동일하다 (see section origin 함수(The origin Function)):
FOO ?= bar
그리고
ifeq ($(origin FOO), undefined)
FOO = bar
endif
변수에 텍스트를 덧붙이기(Appending More Text to Variables)
이미 정의된 변수의 값에다 텍스트를 추가하는 것은 종종 유용하다. 여러분은 이것을 다음과 같이 `+='이 담겨진 라인으로 한다:
objects += another.o
이것은 objects 변수의 값을 취해서 텍스트 `another.o'를 그것에 더한다(앞에다 하나의 공백을 붙인다). 그래서:
objects = main.o foo.o bar.o utils.o
objects += another.o
이것은 objects를 `main.o foo.o bar.o utils.o another.o'로 설정한다.
`+='를 사용하는 것은 다음과 비슷하다:
objects = main.o foo.o bar.o utils.o
objects := $(objects) another.o
그러나 여러분이 좀 더 복잡한 값들을 사용할 때 중요해지는, 방법상에서 차이가 난다.
문제의 변수가 이전에 정의된 것이 아니라면 `+='는 `='인 것처럼 작동한다: 이것은 재귀적으로-확장된 변수를 정의한다. 그러나 이전의 정의가 있다면, `+='가 하는 정확한 일은 원래 정의한 변수의 취향이 무엇이었는가에 따라서 달라진다. 변수의 두 취향에 대한 설명을 보려면, See section 변수의 두 취향(The Two Flavors of Variables).
여러분이 어떤 변수의 값에다 `+='로 무엇인가를 덧붙일 때, make는 기본적으로, 그 변수의 초기 정의에서 여분의 텍스트를 포함한 것처럼 작동한다. 맨먼저 `:='로 정의해서 단순 확장 변수를 만들었다면 `+='는 그것에다 단순-확장 정의를 추가하고, `:='가 하는 것처럼 이전 값에다 그것을 덧붙이기 이전에 새로운 텍스트로 확장한다. (`:='의 완전한 설명에 대해서는, see section 변수 설정(Setting Variables)). 사실
variable := value
variable += more
는 완전히 다음과 동일하다:
variable := value
variable := $(variable) more
한편 일반 `='를 사용하여 재귀적으로-확장되도록 맨처음 정의했던 변수에 `+='를 사용한다면 make는 조금 다른 것을 한다. 재귀적으로-확장되는 변수를 정의할 때 make는 그 변수를 여러분이 변수나 함수 참조로 설정한 값으로 즉각 확장하지 않는다는 것을 기억하자. 그 텍스트를 있는 그대로 넣는 대신에 이런 변수와 함수 참조들이 나중에, 새로운 변수를 참조할 때, 확장되도록 저장한다 (see section 변수의 두 취향(The Two Flavors of Variables)). 재귀적으로-확장되는 변수에 대해서 `+='를 사용할 때 여러분이 지정한 새로운 텍스트를 make가 어디에 덧붙이는 곳이 바로 이 확장되지 않은 텍스트이다.
variable = value
variable += more
이것은 다음과 거의 동일하다:
temp = value
variable = $(temp) more
단 하나 물론 이것은 temp라는 변수를 정의하지 않는다는 점을 제외하고 말이다. 이것의 중요성은 그 변수의 예전 값이 변수 참조를 담고 있을 때 발생한다. 다음 일반 예제를 보자:
CFLAGS = $(includes) -O
...
CFLAGS += -pg # enable profiling
첫번째 라인은 CFLAGS 변수를 다른 변수 includes에 대한 참조로써 정의한다. (CFLAGS는 C 컴파일을 위한 규칙들에 의해서 사용된다; see section 묵시적 규칙들의 카달로그(Catalogue of Implicit Rules).) `='를 정의에서 사용하는 것은 CFLAGS가 재귀적으로-확장된 변수로 만든다. 이것은 `$(includes) -O'가, make가 CFLAGS의 정의를 처리할 때 확장되지 않는다는 것을 의미한다. 그래서 includes는 그의 값이 효력을 발휘하도록 정의될 필요가 아직 없는 것이다. 이것은 CFLAGS에 대한 다른 참조가 있기전에 정의되기만 하면 된다. `+='를 사용하지 않고서 CFLAGS의 값에다 무엇인가를 덧붙이려고 한다면 우리는 다음과 같이 할런지도 모른다:
CFLAGS := $(CFLAGS) -pg # enable profiling
이것은 거의 근사한 것이지만 우리가 원하는 바로 그것은 아니다. `:='를 사용하면 CFLAGS를 다시 단순하게-확장되는 변수로 재정의해버린다; 이것은 make가 그 변수를 설정하기 전에 `$(CFLAGS) -pg'라는 텍스트로 확장해버린다는 것을 의미한다. includes가 아직도 정의된 것이 아니라면 우리는 ` -O -pg'를 얻고, 나중에 나온 includes 정의는 아무런 효력을 발휘하지 못한다. 역으로 `+='를 사용함으로써 우리는 CFLAGS를 확장되지 않은 값 `$(includes) -O -pg'로 설정한다. 그래서 우리는 includes에 대한 참조를 보존한다. 그러므로 그 값이 나중에 정의를 얻게 되면 `$(CFLAGS)'와 같은 참조는 여전히 그 값을 사용한다.
override 지시어
어떤 변수가 명령 매개변수 (see section 변수 겹쳐쓰기(Overriding Variables)) 로 설정되었다면 makefile 안의 일반 할당은 무시된다. 명령 매개변수로 설정된 바 있더라도 그 변수를 makefile 안에서 설정하고자 한다면 override 지시어를 사용할 수 있다. 이것은 다음과 같이 보이는 라인이다:
override variable = value
또는
override variable := value
좀 더 많은 텍스트를 명령 라인에서 정의된 변수에다 덧붙이려면 다음과 같이 사용한다:
override variable += more text
See section 변수에 텍스트를 덧붙이기(Appending More Text to Variables).
override 지시어는 makefile과 명령 매개변수들 간의 전쟁에서 자동 조절을 위해서 고안된 것이 아니었다. 이것은 사용자가 명령 매개변수들로 지정한 값들을 변경하거나 더할 수 있도록 고안된 것이다.
예를 들어서 C 컴파일러를 실행할 때 언제나 `-g' 스위치를 원한지만 사용자에게 보통처럼 명령 매개변수들로 다른 스위치를 지정하는 것을 허락하고자 한다고 가정하자. 그러면 다음과 같이 override 지시어를 사용할 수 있을 것이다:
override CFLAGS += -g
override 지시어를 define 지시어로 또한 사용할 수 있다. 이것은 여러분이 기대하는 것과 비슷하게 작동할 것이다:
override define foo
bar
endef
define에 대한 정보는 다음 섹션을 참조.
축어 변수 정의(Defining Variables Verbatim)
어떤 변수의 값을 설정하는 다른 방법은 define 지시어를 사용하는 것이다. 이 지시어는 개행 문자들이 그 값에 포함되는 것을 허용하는 비일상적인 문법을 가진다. 이렇게 하는 것은 명령들의 묶인 시퀀스(canned sequence)를 정의할 때 편리하다.
define 지시어는, 동일한 라인에, 그 변수의 이름이 뒤따라오고 그외는 아무것도 없다. 변수의 값은 다음에 있는 라인들에 나타난다. 값의 끝은 endef 를 담고 있는 라인에 의해서 표시된다. 문법상의 이런 차이외에 define 은 `='와 비슷하게 작동한다: 이것은 재귀적으로-확장되는 변수를 생성한다 (see section 변수의 두 취향(The Two Flavors of Variables)). 변수의 이름은 함수와 변수 참조를 담고 있을 수 있다. 이것은 사용되는 실제 변수 이름을 찾기 위해서 지시어가 읽힐 때 확장된다.
define two-lines
echo foo
echo $(bar)
endef
일반 할당에서의 값은 개행을 가지지 못한다; 그러나 define 안의 값들의 라인을 나누는 개행들은 그 변수의 값이 된다(endef 앞에 잇는 마지막 개행은 예외인데 이것은 값의 일부로 생각되지 않는다).
이전 예제는 기능적으로 다음과 동일하다:
two-lines = echo foo; echo $(bar)
세미콜론으로 나뉜 두 명령들이 두개의 분할된 쉘명령들과 비슷하게 작동하기 때문이다. 그러나, 두개의 분리된 라인을들 사용하는 것은 make 가 쉘을 두번 호출하여 각 라인에 대해서 독립된 서브쉘에서 실행된다는 것을 주목하자. See section 명령 실행(Command Execution)
define 으로 만들어진 변수 정의들이 명령행 변수 정의들보다 우선순위가 더 높기를 바란다면 define 과 함께 override 지시어를, 다음과 같이 묶어서 쓸 수 있다:
override define two-lines
foo
$(bar)
endef
See section override 지시어.
환경으로부터의 변수들(Variables from the Environment)
make 의 변수들은 make 가 실행중인 환경으로부터 올 수 있다. make 가 시작할 때 본 모든 환경변수들은 make 변수로 동일한 이름과 동일한 값을 가진채 변환된다. 그러나 makefile에서의 명시적 할당이나, 명령 매개변수를 사용한 명시적 할당은 환경을 오버라이드한다. (`-e' 플래그가 지정되면 환경으로부터의 값들이 makefile에 있는 할당들을 오버라이드한다. See section 옵션들의 요약(Summary of Options). 그러나 이것은 권장되는 바가 아니다.)
그래서 CFLAGS 라는 변수를 환경에서 설정하면 이런 컴파일러 스위치들을 대부분의 makefileㄷ르에 있는 모든 C 컴파일이 사용하도록 할 수 잇다. 이것은 표준 또는 전통적인 의미의 변수들에 대해서 안전하다. 왜냐면 어떤 makefile도 그들을 다른 것으로 사용하지 않을 것이라는 것을 여러분은 알고 있기 때문이다. (그러나 이것은 완전히 믿을만한 것이 아니다; 어떤 makefile들은 CFLAGS를 명시적으로 지정해서 환경에 잇는 값에 의해서 영향을 받지 못할 수도 있기 때문이다.)
make가 재귀적으로 호출될 때 외부 호출에서 정의된 변수들은 내부 호출로, 환경을 통해서 전달될 수 있다 (see section make의 재귀적 사용(Recursive Use of make)). 디폴트로 환경으로부터 또는 명령행으로부터 온 변수들만이 재귀적 호출에 전달된다. export 지시어를 사용해서 다른 변수들을 익스포트할 수 있다. 자세한 내용은 See section 서브-make에 대한 통신 변수(Communicating Variables to a Sub-make).
환경으로부터의 변수들을 다르게 사용하는 것은 권장되지 않는다. makefile들이 그들의 기능을 그들의 제어 바깥에서 설정된 환경변수들에 의존한다는 것은 별로 현명한 것이 아니다. 왜냐면 이렇게 하는 것은 동일한 makefile을 가지고 다른 사용자들이 다른 결과를 얻게 만들기 때문이다. 이것은 대부분의 makefile의 전체 목적에 위배된다.
그런 문제들은 SHELL 이라는 변수로, 특별히 잘 일어날 것이다. 이것은 일반적으로 환경에서 사용자의 인터렉티브 쉘로 지정하는 데 사용된다. 이런 선택이 make 에 영향을 미치는 것은 원하는 것이 아닐 것이다. 그래서 make 는 SHELL 환경변수의 값을 무시한다 (SHELL 이 보통 설정되지 않는 MS-DOS와 MS-Windows는 제외. See section 명령 실행(Command Execution).)
타겟-종속적인 변수 값(Target-specific Variable Values)
make 에 있는 변수값들은 보통 전역적이다; 즉, 그들이 평가된 위치와 상관없이 이들은 동일하다(물론 그들이 리셋되지 않는다면). 한가지 예외는 자동 변수들의 경우이다 (see section 자동 변수들(Automatic Variables)).
다른 예외는 타겟-종속 변수 값(target-specific variable values)이다. 이 기능은 동일한 변수에 대해서, make 가 현재 빌드하고 있는 타겟에 기반해서, 다른 값들을 정의할 수 있도록 한다. 자동변수의 경우 이런 값들은 단지 타겟의 명령 스크립트의 내용안에서(그리고 다른 타겟-종속적인 할당에서)만 사용 가능하다.
타겟-종속적인 변수값은 다음과 같이 설정한다:
target ... : variable-assignment
또는 다음과 같이 정의한다:
target ... : override variable-assignment
다수의 target 값들은 타겟 리스트의 각 멤버에 대해서 타겟-종속적인 값을 개별적으로 생성한다.
variable-assignment 는 할당의 유효한 형태이면 아무거나 된다; 재귀적 (`='), 정적 (`:='), 덧붙이기 (`+=', 또는 조건 (`?='). variable-assignment에 나타나는 모든 변수들은 타겟의 내용물 안에서 평가된다: 그래서 임의의 사전-정의된 타겟-종속적인 변수 값들이 효력을 발휘할 것이다. 이 변수는 실제로 어떤 "전역" 값과도 구분이 된다는 점에 주목하자: 두 변수들이 동일한 취향(재귀적 vs. 정적)을 반드시 가질 필요는 없다.
타겟-종속적인 변수들은 다른 makefile 변수와 동일한 우선순위를 가진다. 명령행에서 주어진 변수들이(그리고 `-e' 옵션이 주어졌다면 환경에서 주어진 변수들이) 우선권을 가질것이다. override를 지정하는 것은 타겟-종속 변수 값이 더 선호되도록 할 것이다.
타겟-종속적인 변수들의 특수한 기능이 하나 더 있다: 타겟-종속적인 변수를 정의할 때 그 변수의 값이 또한 이 타겟의 모든 종속물들에 대해서도 영향을 미친다(단 이런 종속물들이 그들 자신의 타겟-종속적인 변수 값으로써 그것을 오버라이드하지 않았다면 말이다). 그래서 예를 들면 다음과 같은 문장은:
prog : CFLAGS = -g
prog : prog.o foo.o bar.o
CFLAGS를 `prog'에 대한 명령 스크립트에서 `-g'로 설정할 것이다. 그러나 이것은 또한 CFLAGS를 `prog.o', `foo.o', 그리고 `bar.o'를 생성하는 명령 스크립트안에서, 그리고 이들의 종속물들을 생성하는 임의의 명령 스크립트들을 생성하는 명령 스크립트들 안에서 `-g'로 설정할 것이다.
패턴-종속적인 변수값(Pattern-specific Variable Values)
타겟-종속적인 변수값 (see section 타겟-종속적인 변수 값( Target-specific Variable Values)) 에 덧붙여서, GNU make는 패턴-종속적인 변수값을 지원한다. 이 형에서 변수는 지정된 패턴과 일치하는 임의의 타겟에 대해서 정의된다. 이런식으로 정의된 변수들은, 그 타겟에 대해서 명시적으로 정의된 임으의 타겟-종속적인 변수들 이후에, 그리고 타겟 종속적인 변수가 어버이 타겟에 대해서 정의되기 전에, 검색된다.
패턴-종속적인 변수값은 다음과 같이 지정한다:
pattern ... : variable-assignment
또는 다음과 같이:
pattern ... : override variable-assignment
여기서 pattern 는 %-패턴이다. 타겟-종속 변수값과 동일하게 다수의 pattern 값들이 각 패턴에 대해서 개별적으로 패턴-종속 변수값을 생성한다. variable-assignment 는 유효한 할당이면 무엇이든 된다. 임의의 명령행 변수 설정이, override가 지정되지 않았다면, 더 높은 우선순위를 가진다.
예를 들어서:
%.o : CFLAGS = -O
이것은 패턴 %.o와 일치하는 모든 타겟들에 대해서 `-O'를 CFLAGS의 값으로 할당할 것이다.
Makefile의 조건 부분(Conditional Parts of Makefiles)
조건(conditional) 은 makefile의 어떤 부분이 변수의 값에 따라서 사용되거나 무시되도록 한다. 조건은 한 변수를 다른 것과, 또는 한 변수의 값을 상수 문자열과 비교할 수 있다. 조건은 make가 실제로 makefile에서 "보는" 것을 제어한다. 그러므로 실행시의 쉘 명령들을 제어하는 데에는 사용될 수 없다.
조건의 예(Example of a Conditional)
다음 조건의 예제는 make에게 CC 변수가 `gcc'이라면 일단의 라이브러리 모음을 사용하라고 말하는 것이다. 그렇지 않다면 다른 라이브러리 모음을 사용하도록 말하는 것이다. 두 명령 라인들 중의 어떤 것이 어떤 규칙에 대해서 사용될 것인가를 제어함으로써 작동한다. 그 결과로 make에 대한 매개변수로써 `CC=gcc'를 쓰면, 어떤 컴파일러가 사용될 것인가 뿐만 아니라 어떤 라이브러리들이 링크될 것인가를 변경한다.
libs_for_gcc = -lgnu
normal_libs =
foo: $(objects)
ifeq ($(CC),gcc)
$(CC) -o foo $(objects) $(libs_for_gcc)
else
$(CC) -o foo $(objects) $(normal_libs)
endif
이 조건은 세가지 지시어들을 사용한다: 하나는 ifeq, 하나는 else, 그리고 나머지 하나는 endif.
ifeq 지시어는 조건을 시작하고 조건을 지정한다. 콤머로 분리되고 괄호로 둘러싸인 두개의 매개변수들을 가진다. 변수 대입이 두 매개변수들에 대해서 수행되고 난 뒤에 그들이 비교된다. ifeq 뒤에 오는 makefile의 라인들은 두 매개변수들이 일치할 경우 사용된다; 그렇지 않으면 그들은 무시된다.
else 지시어는 다음 라인들이, 이전 조건이 실패하였다면, 수행되도록 한다. 위의 예제에서 이것은 두번째 대안 링크 명령이, 첫번째 대안이 사용되지 않을때마다, 사용된다는 것을 의미한다. else를 조건에 가지는 것은 선택이다.
endif 지시어는 조건을 종료한다. 모든 조건은 반드시 endif로 종료해야 한다. 이 뒤에 조건이 아닌 makefile의 텍스트가 온다.
예제가 예시하는 것처럼 조건은 텍스트 레벨에서 작동한다: 조건의 라인들은 조건에 따라서 makefile의 일부로 취급되거나 아니면 무시된다. 이것은 규칙과 같은 makefile의 더 큰 문법 유닛들이 왜 조건의 시작이나 끝과 겹쳐져 있을 수 있는가에 대한 이유이다.
변수 CC가 변수 `gcc'를 가질 때 위의 예제는 다음과 같은 효과를 가진다:
foo: $(objects)
$(CC) -o foo $(objects) $(libs_for_gcc)
변수 CC가 임의의 다른 값을 가진다면 그 결과는 다음과 같을 것이다:
foo: $(objects)
$(CC) -o foo $(objects) $(normal_libs)
어떤 변수 할당을 조건화해서 변수를 무조건 사용함으로써, 동일한 결과가 다른 식으로 얻어질 수 있다:
libs_for_gcc = -lgnu
normal_libs =
ifeq ($(CC),gcc)
libs=$(libs_for_gcc)
else
libs=$(normal_libs)
endif
foo: $(objects)
$(CC) -o foo $(objects) $(libs)
조건의 문법(Syntax of Conditionals)
else를 가지지 않는 단순한 조건의 문법은 다음과 같다:
conditional-directive
text-if-true
endif
text-if-true는 임의 라인의 텍스트일 수 있다. 이것은 조건이 참일 때 makefile의 일부로 여겨진다. 조건이 거짓이면 어떤 텍스트도 사용되지 않는다.
복잡한 조건의 문접은 다음과 같다:
conditional-directive
text-if-true
else
text-if-false
endif
조건이 참이면 text-if-true가 사용된다; 그렇지 않으면 text-if-false 이 사용된다. text-if-false는 임의 라인의 텍스트일 수 있다.
conditional-directive 의 문법은 조건이 단순하든지 아니면 복잡하든지 동일하다. 서로 다른 조건들을 테스트하는 서로 다른 지시어들이 네개 있다. 이들은 다음과 같다:
ifeq (arg1, arg2)
ifeq 'arg1' 'arg2'
ifeq "arg1" "arg2"
ifeq "arg1" 'arg2'
ifeq 'arg1' "arg2"
arg1과 arg2에 있는 모든 변수 참조들을 확장하고서 그들을 비교한다. 그들이 서로 같다면 text-if-true가 사용될 것이고; 그렇지 않다면 text-if-false가, 있다면, 사용될 것이다. 어떤 변수가 빈것이 아닌 값을 가진것인가 아닌가를 테스트하고자 할 경우가 많다. 값이 변수와 함수의 복잡한 확장으로부터 온 것일 때, 빈것으로 생각한 확장이 실제로 공백문자들을 담고 있어서 빈것으로 보이지 않을 수도 있다. 그러나 strip 함수 see section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis)) 를 사용해서 공백문자를 빈것이 아닌 값으로 해석하는 것을 피할 수 있다. 예를 들면:
ifeq ($(strip $(foo)),)
text-if-empty
endif
이것은 $(foo) 의 확장이 공백문자를 담고 있다고 하더라도 text-if-empty 를 평가할 것이다.
ifneq (arg1, arg2)
ifneq 'arg1' 'arg2'
ifneq "arg1" "arg2"
ifneq "arg1" 'arg2'
ifneq 'arg1' "arg2"
이것은 arg1과 arg2에 있는 모든 변수 참조들을 확장한 뒤 그것들을 비교한다. 그들이 다르다면 text-if-true 가 사용될 것이고; 그렇지 않다면 text-if-false가, 존재한다면, 사용될 것이다.
ifdef variable-name
변수 variable-name 가 빈것이 아닌 값을 가진다면, text-if-true 가 사용될 것이다; 그렇지 않다면 text-if-false 가, 존재한다면, 사용될 것이다. 한번도 정의된 바가 없는 변수들은 빈 값을 가진다. ifdef 는 어떤 변수가 값을 가지는지 안가지는지에 대해서만 테스트한다는 것에 주의하자. 이것은, 값이 빈것인가 아닌가를 보기 위해서 변수를 확장하지 않는다. 결과적으로 ifdef를 사용한 테스트들은 foo =와 같은 것들을 제외한 모든 정의들에 대해서 참을 리턴한다. 빈 값에 대한 테스트를 하려면 ifeq ($(foo),) 를 사용한다. 예를 들어서,
bar =
foo = $(bar)
ifdef foo
frobozz = yes
else
frobozz = no
endif
이것은 `frobozz'를 `yes'로 설정하는 반면에 다음은:
foo =
ifdef foo
frobozz = yes
else
frobozz = no
endif
`frobozz'를 `no'로 설정한다.
ifndef variable-name
variable-name 변수가 빈 값을 가진다면 text-if-true 가 사용된다; 그렇지 않으면 text-if-false, 존재한다면, 사용된다.
조건 지시어 라인에서 맨앞에 있는 여분의 공백들은 허용되고 이들은 무시된다. 그러나 탭은 허용되지 않는다. (탭으로 시작한다면 규칙의 명령으로 생각될 것이다.) 이런 것 외에 여분의 공백들이나 탭들이 지시어 이름이나 매개변수 안을 제외하고는, 어디에서나 아무런 효과없이 삽입될 수 있다. `#' 로 시작하는 주석이 라인의 마지막에 올 수 있다.
조건의 일부인 다른 두 지시어들은 else와 endif이다. 이런 지시어들 각각은 단일 워드로, 매개변수 없이 사용된다. 여분의 공백들이 그 라인의 맨처음에 올 수도 있으며 이들은 무시된다. 그리고 라인의 끝에 공백들이나 탭들이 올 수 있다. `#'로 시작하는 주석은 라인의 끝에 나타날 수 있다.
조건은 makefile의 어떤 라인들을 make가 사용할 것인가에 영향을 미친다. 조건이 참이면, make는 text-if-true 라인들을 makefile의 일부로 읽는다; 조건이 거짓이면 make는 이런 라인들을 완전히 무시한다. 규칙과 같은 makefile의 문법 유닛들이 조건의 끝이나 처음에 걸쳐 안전하게 쪼개질 수 있다.
make는 그것이 makefile을 읽을 때 조건들을 평가한다. 결과적으로 조건의 테스트 안에서 자동 변수들을 사용할 수 없다. 왜냐면 그들은 명령들이 실행되기 전에는 정의되지 않기 때문이다 (see section 자동 변수들(Automatic Variables)).
참을수 없는 혼동을 막기 위해서 하나의 makefile안에서 조건을 시작하고 다른 makefile 안에서 끝내지는 것은 허용되지 않는다. 그러나, include 지시어를 조건 안에 사용할 수 있다. 단 그 include된 파일 안에서 그 조건을 종료하려고 시도하지 않는다면 말이다.
플래그 검사 조건(Conditionals that Test Flags)
`-t'와 같은 make 명령 플래그들을, 변수 MAKEFLAGS과 findstring 함수 (see section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis)) 를 사용함으로써, 검사하는 조건을 작성할 수 있다. 이것은 touch가 파일이 업데이트된 것으로 만들기에 충분하지 않을 때 유용하다.
findstring 함수는 한 문자열이 다른 것의 부분문자열로 나타난 것인가 아닌가를 결정한다. `=t' 플래그를 테스트하고자 한다면 `t'를 첫번째 문자열로, MAKEFLAGS를 다른 문자열로 사용한다.
예를 들어서 다음은 아카이브 파일이 갱신된 것으로 표시하는 것을 끝내도록 하기 위해서, `ranlib -t'를 사용해서 정리하는 방법이다:
archive.a: ...
ifneq (,$(findstring t,$(MAKEFLAGS)))
+touch archive.a
+ranlib -t archive.a
else
ranlib archive.a
endif
`+' 프리픽스는 이런 명령 라인들이 "재귀적" 이어서 그들이 `-t' 플래그에도 불구하고 실행될 것이라는 것을 표시한다. See section make의 재귀적 사용(Recursive Use of make).
텍스트 변환을 위한 함수(Functions for Transforming Text)
함수(functions)는 여러분이 makefile안에서, 작업할 파일들을 알아내거나 아니면 사용할 명령들을 알아낼 수 있도록, 텍스트를 처리하는 것이다. 함수는 dfn{함수 호출(function call)} 안에서 사용한다. 여기에서 함수의 이름과 함수가 작업할 텍스트(매개변수(arguments) 를 제공한다. 함수 처리의 결과는 makefile의 그 호출 위치에 삽입된다. 마치 변수가 대입된 것처럼.
함수 호출 문법(Function Call Syntax)
함수 호출은 변수 참조와 닯았다. 이것은 다음과 같이 보일 것이다:
$(function arguments)
또는 다음과 같이 보일 것이다:
${function arguments}
여기서 function는 함수 이름이다; make의 일부인 이름들 짧은 리스트의 하나. 새로운 함수를 정의하기 위한 준비는 없다.
arguments는 함수의 매개변수들이다. 이들은 함수와 하나 이상의 공백이나 탭으로 분리되며, 한 개 이상의 매개변수들이 있으면 그들은 콤머로 구분된다. 그런 공백문자와 콤머들은 매개변수 값의 일부가 되지 않는다. 함수 호출을 둘러싸는 데 사용한 구분자들은, 괄호들이나 중괄호들은, 짝이 맞는 꼴로만 나타날 수 있다; 다른 종류의 구분자들은 단신으로 나타날 수 있다. 매개변수들 자신이 다른 함수 호출들이나 변수 참조들을 가진다면 모든 참조들에 대해서 동일한 종류의 구분자들을 사용하는 것이 가장 현명할 것이다; `$(subst a,b,${x})' 이 아니라 `$(subst a,b,$(x))' 를 쓰자. 이렇게 하는 것이 좀 더 명확하기 때문이다. 그리고 한가지 종류의 구분자만이 참조의 끝을 찾기 위해서 서로 비교되기 때문이다.
각 매개변수 텍스트는 매개변수 값을 만드는 변수 대입과 함수 호출들에 의해서 처리된다. 이것이(이 결과가) 함수가 작동하는 대상 텍스트이다. 대입은 매개변수들이 나타난 순서대로 행해진다.
콤머들과 일치하지 않은 괄호나 중괄호들은 매개변수가 작성된것과 동일한 텍스트로 나타날 수 없다; 앞에 있는 공백들은 작성된 것과 같은 첫번째 매개변수의 텍스트로 나타날 수 없다. 이런 문자들은 변수 대입을 통해서 매개변수 값들로 넣어질 수 있다. 먼저 그것의 값들이 콤마나 공백 문자들로 구분된 변수 comma와 space를 정의한 뒤 이들 변수들을 그런 문자들이 필요한 곳에, 다음과 같이, 대입한다:
comma:= ,
empty:=
space:= $(empty) $(empty)
foo:= a b c
bar:= $(subst $(space),$(comma),$(foo))
# bar is now `a,b,c'.
여기서 subst 함수는 foo의 값 전체에서 각 스페이스를 콤머로 변경하고 그 결과를 이 값에 대입한다.
문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis)
다음은 문자열들에 대해서 작동하는 함수들이다:
$(subst from,to,text)
text 텍스트에 대해서 텍스트의 대치를 수행한다: 이것 안에서 from이 나오면 to로 대치된다. 그 결과가 대입된다. 예를 들어서
$(subst ee,EE,feet on the street)
는 `fEEt on the strEEt'를 대입한다.
$(patsubst pattern,replacement,text)
text 안에서 공백문자로 분리된 단어들 중 pattern와 매치되는 단어를 찾아서 그것들을 replacement로 변경한다. 여기서 pattern는 와일드카드 역할을 하는 `%'를 가질 수 있는데, 이것은 어떤 단어 내에 있는 임의 개수의 어떤 문자들과도 매치된다.
replacement도 역시 `%'를 가질 수 있는 데 `%'는 pattern 안에서 `%'과 매치된 텍스트에 의해서 대치된다. patsubst 함수 호출에 있는 `%' 문자들은 앞에 역슬래쉬 (`\')를 써서 인용될 수 있다. `%'를 인용했을 역슬래쉬들은 더 많은 역슬래쉬들에 의해서 인용당할 수 있다. `%' 문자들이나 다른 역슬래쉬들을 인용하는 역슬래쉬는 패턴에서, 이것이 파일 이름들과 비교되거나 그안에 대입된 줄기를 가지기 전에, 제거된다. `%' 문자들을 인용할 위험이 없는 역슬래쉬들은 아무런 간섭도 하지 않는다. 예를 들어서 `the\%weird\\%pattern\\' 는 `%' 문자 앞에 `the%weird\' 가 있고 뒤에 `pattern\\' 가 있다. 마지막 두 역슬래쉬들은 그들이 어떤 `%' 문자에도 영향을 미치지 않기 때문에 잔류한다. 단어들 사이에 있는 공백문자는 단일 스페이스 문자로 줄어든다; 이에 앞서거나 뒷선 공백문자들은 무시된다. 예를 들어서 다음은,
$(patsubst %.c,%.o,x.c.c bar.c)
`x.c.o bar.o' 라는 값을 만든다. 대입 참조(see section 대입 참조(Substitution References) 는 patsubst 의 효과를 얻는 더 단순한 방법이다:
$(var:pattern=replacement)
는 다음과 동일하다
$(patsubst pattern,replacement,$(var))
두번째 짧은 표기 방법은 patsubst의 가장 일반적인 사용들 중의 하나를 단순하게 만든다: 파일 이름들의 끝에 있는 접미사(확장자?)를 교체한다.
$(var:suffix=replacement)
이것은 다음과 동일하다.
$(patsubst %suffix,%replacement,$(var))
예를 들어서, 다음과 같은 오브젝트 파일들의 리스트를 가지고 있다면:
objects = foo.o bar.o baz.o
이에 대응하는 소스 파일들의 리스트를 얻기 위해서 다음과 같이 쉽게 작성할 수 있다:
$(objects:.o=.c)
이것은 다음과 같은 일반형태를 사용하는 것 대신에 쓸수 있다:
$(patsubst %.o,%.c,$(objects))
$(strip string)
이 함수는 string의 앞뒤에 있는 공백문자들을 제거하고 내부에 있는 하나 이상의 공백문자들을 단일 스페이스로 교체한다. 그래서 `$(strip a b c )'의 결과는 `a b c'가 된다. strip 함수는 조건과 함께 사용될 때 아주 유용할 수 있다. 어떤 것을 빈 문자열 `'과, ifeq 또는 ifneq를 사용해서, 비교할 때 보통 빈 문자열과 일치하는 공백의 문자열을 원할 것이다 (see section Makefile의 조건 부분(Conditional Parts of Makefiles)). (그래서, ) 다음과 같은 것은 원하는 결과를 얻지 못한다:
.PHONY: all
ifneq "$(needs_made)" ""
all: $(needs_made)
else
all:;@echo 'Nothing to make!'
endif
ifneq 지시어에서 변수 참조 `$(needs_made)' 를 함수 호출 `$(strip $(needs_made))' 로 바꿈으로써 좀 더 엄격(robust)하게 만들 것이다.
$(findstring find,in)
이 함수는 in에서 find를 찾는다. 있다면 그 값은 find가 된다; 그렇지 않다면 그 값은 빈 것이 된다. 이 함수를 조건에서 사용해서 주어진 문자열 안에서 특정 문자열의 존재 여부를 검사할 수 있다. 그래서 다음과 같은 두 예제들은,
$(findstring a,a b c)
$(findstring a,b c)
`a'와 `' (빈 문자열) 각각을 만든다. findstring의 실질적인 응용에 대해서는 See section 플래그 검사 조건(Conditionals that Test Flags).
$(filter pattern...,text)
이 함수는 pattern 단어들 중의 임의의 것과 일치하지 않는, text 내의 공백문자로 분리된 단어들을 모두 제거하고 일치하는 단어들만을 리턴한다. 패턴은, 위의 patsubst 함수에서 사용된 패턴과 마찬가지로, `%'을 사용하여 작성된다. filter 함수는 한 변수 안에서 (파일 이름과 같은) 다른 타입의 문자열들을 분리 제거하는 데 사용될 수 있다. 예를 들어서:
sources := foo.c bar.c baz.s ugh.h
foo: $(sources)
cc $(filter %.c %.s,$(sources)) -o foo
는 `foo'가 `foo.c', `bar.c', `baz.s' 그리고 `ugh.h' 에 의존하지만 `foo.c', `bar.c' 그리고 `baz.s' 만이 명령안에서 컴파일러에 대해 지정되어야 한다는 것을 말한다.
$(filter-out pattern...,text)
이 함수는 text에서 pattern 단어들과 일치하는, 공백문자들로 분리된 단어들을 모두 제거하고 일치하지 않는 단어들만을 리턴한다. 이것은 filter 함수의 정확한 반대이다. 예를 들어서, 다음이 주어졌다면:
objects=main1.o foo.o main2.o bar.o
mains=main1.o main2.o
다음은 `mains'에 있지 않는 오브젝트 파일들 모두를 담고 있는 리스트를 생성한다:
$(filter-out $(mains),$(objects))
$(sort list)
이 함수는 list에 있는 단어들을 렉시컬(사전) 순서로 소팅하고 중복도니 단어들을 제거한다. 그 결과는 단일 스페이스들로 분리된 단어들의 리스트이다. 그래서,
$(sort foo bar lose)
이것은 `bar foo lose'를 리턴한다. 부수적으로 sort 함수는 중복된 단어들을 제거하기 때문에 이것을 소팅 순서에 대해서 신경쓰지 않더라도 이런 목적으로 이 함수를 사용할 수 있다.
다음은 subst와 patsubst 사용의 현실적인 예제이다. makefile이 VPATH 변수를 사용하여 make가 종속 파일들을 검색해야 할 디렉토리 리스트를 지정한다고 가정하자 (see section VPATH: 모든 종속물에 대한 검색 패스(Search Path for All Dependencies)). 이 예제는 C 컴파일러에게 동일한 디렉토리 리스트에서 헤더 파일들을 찾는 방법을 말하는 방법을 보여준다.
VPATH의 값은 `src:../headers'와 같이 콜론으로 분리되는 디렉토리 리스트이다. 첫번째, subst 함수는 콜론들을 스페이스들로 변경하는 데 사용된다:
$(subst :, ,$(VPATH))
이것은 `src ../headers'를 만든다. 그리고 나서 patsubst는 각 디렉토리 이름을 `-I' 플래그로 변경하는 데 사용된다. 이것은 변수 CFLAGS의 값에 더해질 수 있다. 이것은 자동으로 다음과 같이 C 컴파일러에게 전달된다:
override CFLAGS += $(patsubst %,-I%,$(subst :, ,$(VPATH)))
이것의 효과는 텍스트 `-Isrc -I../headers'를 CFLAGS에게 사전에 주어졌던 값에 덧붙이는 것이다. override 지시어는, CFLAGS의 이저의 값이 명령 매개변수로 주어졌다 하더라도 새로운 값이 할당되도록 하는 데 사용된다 (see section override 지시어).
파일 이름들을 위한 함수(Functions for File Names)
내장 확장 함수들 몇가지는 특별히 파일 이름들을 또는 파일 이름들 리스트를 분해하는 데 연관이 있다.
다음 함수들 몇가지는 파일 이름에 대해서 특정 변환을 수행한다. 함수의 매개변수는 공백문자로 분리된, 일련의 파일 이름들로 취급된다. (앞뒤에 있는 공백문자들은 무시된다.) 이 일련의 파일 이름들 각각은 동일한 방식으로 변환되고 그 결과는 그들 사이에 단일 스페이스들을 넣어서 묶인 것이 된다.
$(dir names...)
이것은 names에 있는 각 파일 이름에서 디렉토리-파트를 추출한다. 파일 이름의 디렉토리-파트는 그 안에 있는 마지막 슬래쉬까지의 (그리고 이 마지막 슬래쉬를 포함한) 모든 것이다. 그 파일 이름이 슬래쉬가 없으면 디렉토리 파트는 문자열 `./'가 된다. 예를 들어서,
$(dir src/foo.c hacks)
는 `src/ ./'라는 결과를 만든다.
$(notdir names...)
이 함수는 names에 있는 각 파일 이름의 디렉토리-부분을 제외한 모든 것을 추출한다. 파일 이름에 슬래쉬가 없으면 변화되지 않는다. 그렇지 않는 경우 마지막 슬래쉬까지 모든 것이 그것으로부터 제거된다. 슬래쉬로 끝나는 파일 이름은 빈 문자열이 될 것이다. 이렇게 되는 것은 불행한 것이다. 왜냐면 이렇게 되는 것은, 그 결과가 항상 매개변수가 가지는 것과 동일하지 않은 개수의 공백으로-분리된 파일 이름들을 가진다는 것을 의미하기 때문이다; 그러나 우리는 다른 어떤 유효한 대안을 보지 못했다. 예를 들어서,
$(notdir src/foo.c hacks)
는 `foo.c hacks'라는 결과를 만든다.
$(suffix names...)
이 함수는 names에 있는 각 파일 이름의 접미사(확장자 ?)를 추출한다. 파일 이름이 소숫점(period)를 갖고 있다면 접미사는 마지막 소숫점부터 시작한 모든 것이다. 그렇지 않다면 접미사는 빈 문자열이다. 이것은 종종, names가 빈 것이 아닐 때도 그 결과가 빈 것이 될 수도 있으며, names가 다수의 파일 이름들을 가진다 하더라도 그 결과는 더 적은 개수의 파일 이름들을 가질 수 있다는 것을 의미한다. 예를 들어서,
$(suffix src/foo.c src-1.0/bar.c hacks)
는 `.c .c'라는 결과를 만든다.
$(basename names...)
이 함수는 names에 있는 각 파일 이름의 접미사를 제외한 모든 것을 추출한다. 파일 이름이 소숫점을 갖고 있다면 basename은 처음부터 마지막 소수점까지의 (소숫점은 포함하지 않음) 모든 것이 된다. 디렉토리 부분에 있는 소숫점들은 모두 무시된다. 소숫점이 없으면 basename은 전체 파일 이름이 된다. 예를 들어서,
$(basename src/foo.c src-1.0/bar hacks)
는 `src/foo src-1.0/bar hacks' 라는 결과를 만든다.
$(addsuffix suffix,names...)
매개변수 names는 공백문자들로 분리된, 일단의 이름들로 취급된다; suffix는 유닛으로써 사용된다. suffix의 값은 각 개별 이름의 끝에 더해지고 그들 사이에 단일 스페이스들을 추가한 더 큰 이름들이 그 결과이다. 예를 들어서,
$(addsuffix .c,foo bar)
는 `foo.c bar.c'라는 결과를 만들어낸다.
$(addprefix prefix,names...)
매개변수 names는 공백문자들로 구분된, 일단의 이름들로 취급된다; prefix는 유닛으로써 사용된다. prefix의 값은 각 개별 이름의 앞에 붙고, 그들 사이에 단일 스페이스들로 채워 연결된 더 커다란 이름들이 결과이다. 예를 들어서,
$(addprefix src/,foo bar)
는 `src/foo src/bar'라는 결과를 만든다.
$(join list1,list2)
이것은 두 매개변수들을 단어 단위로(word by word) 연결(concatenate)한다: 연결된 두개의 첫 단어들(각 매개변수에서 가지고 온 것)이 결과의 첫번째 단어를 구성하고 두개의 두번째 단어들이 결과의 두번째 단어를 구성한다. 이런식으로 계속된다. 그래서 결과의 n번째 단어는 각 매개변수의 n번째 단어로부터 온다. 한 매개변수가 다른 것보다 더 많은 단어들을 가진다면 여분의 단어들은 변경없이 결과에 복사된다. 예를 들어서 `$(join a b,.c .o)'는 `a.c b.o'를 생성한다. 리스트에서 단어들 간의 공백문자는 보존되지 않는다; 이것은 단일 스페이스로 대체된다. 이 함수는 dir과 notdir 함수들의 결과들을 머지(merge)해서 이들 두 함수들에 주어진 파일들의 오리지널 리스트를 만들 수 있다.
$(word n,text)
이것은 text의 n번째 단어를 리턴한다. n의 합법적인 값은 1부터 시작한다. n가 text에 있는 단어들 개수보다 더 크다면 그 값은 빈 것이 된다. 예를 들어서,
$(word 2, foo bar baz)
`bar'를 리턴한다.
$(wordlist s,e,text)
이것은 s로 시작하고 e로 끝나는(각각 포함) text안의 단어들 리스트를 리턴한다. s와 e의 합법적인 값들은 1부터 시작한다. s가 text에 있는 단어들 개수보다 크다면 그 값은 빈 것이 된다. e가 text에 있는 단어들 개수보다 크다면 text의 끝까지의 단어들이 리턴된다. s가 e보다 더 크다면 make는 그들을 서로 맞바꾼다(swap). 예를 들어서,
$(wordlist 2, 3, foo bar baz)
는 `bar baz'를 리턴한다.
$(words text)
이것은 text에 있는 단어들 개수를 리턴한다. 그래서, text의 마지막 단어는 $(word $(words text),text) 로 표현될 수 있다.
$(firstword names...)
names 매개변수는 공백으로 분리된, 일단의 이름들로 생각된다. 그 값은(이 함수의 결과값은) 그 시리즈의 첫번째 이름이다. 이름들의 마지막은 무시된다. 예를 들어서,
$(firstword foo bar)
는 `foo'라는 결과를 만든다. 비록 $(firstword text) 가 $(word 1,text)과 같지만 firstword 함수는 그 단순성 때문에 남았다.
$(wildcard pattern)
pattern 매개변수는 파일 이름 패턴이다. 전형적으로 와일드 카드 문자들 (쉘 파일 이름 패턴과 동일한) 을 담고 있다. wildcard 함수의 결과는 패턴과 일치하는 현존하는 파일들의 이름들을 스페이스로 분리한 리스트이다. See section 파일 이름에 와일드카드 사용(Using Wildcard Characters in File Names).
foreach 함수(The foreach Function)
foreach 함수는 다른 함수들과 아주 다르다. 이것은 텍스트의 한 조각이 반복적으로 사용되도록 한다. 이때 매번 그것에 대해서 다른 대입이 수행된다. 이것은 쉘 sh의 for 명령, 그리고 C-쉘 csh의 foreach 명령과 닮은 것이다.
foreach 함수의 문법은 다음과 같다:
$(foreach var,list,text)
첫번째 두 매개변수들, var와 list는 다른 것이 수행되기 전에 확장된다; 마지막 매개변수 text는 동일한 시간에 확장되지 않는다. 그리고 나서 list의 확장된 각 단어에 대해서 var의 확장된 값을 가지는 변수는 이 단어로 설정되고 그 다음에 text가 확장된다. 아마 text는 그 변수에 대한 참조를 담고 있을 것이다. 그래서 그것의 확장은 매번 다르다.
결과적으로 text는 list에 있는 공백으로-분리된 단어들 개수만큼 확장된다. text의 여러 확장들이 그들 사이에 스페이스들을 넣어서 연결되어 foreach의 결과를 만든다.
다음 단순한 예제는 변수 `files'를 `dirs' 리스트의 디렉토리들에 있는 모든 파일들의 리스트로 설정한다.
dirs := a b c d
files := $(foreach dir,$(dirs),$(wildcard $(dir)/*))
여기서 text는 `$(wildcard $(dir)/*)'이다. 첫번째 반복은 dir에 대해서 값 `a'을 찾아 넣고서 `$(wildcard a/*)'와 동일한 결과를 생산한다; 두번째 반복은 `$(wildcard b/*)'이라는 결과를 생성한다; 그리고 세번째는 `$(wildcard c/*)'.
이 예제는 다음 예제와 동일한 (`dirs'를 설정하는 것 빼고) 결과를 가진다:
files := $(wildcard a/* b/* c/* d/*)
text가 복잡할 때, 추가의 변수로, 그것에 이름을 주어서 가독성을 증진할 수 있다:
find_files = $(wildcard $(dir)/*)
dirs := a b c d
files := $(foreach dir,$(dirs),$(find_files))
여기서 우리는 변수 find_files를 이런 식으로 사용하고 있다. 우리는 평범한 `='를 써서 재귀적으로-확장되는 변수 하나를 정의했다. 그래서 그것의 값을 foreach의 제어하에서 다시 확장되어지는 실제 함수 호출에 따라서 가진다; 단순하게-확장되는 변수는 그렇지 않을 것이다. 왜냐면 wildcard가 find_files를 정의하는 순간에 한번만 호출될 것이기 때문이다.
foreach 함수는 변수 var에 대한 항구적인 효과를 가지지 않는다; foreach 함수 호출 이후 이것의 값과 취향은 그들이 이전에 그랬던 것과 동일하다. 다른 list로부터 취해진 다른 값들은 잠시 동안만, foreach의 실행 동안만, 효력이 있다. 변수 var는 foreach의 실행동안 단순하게-확장되는 변수이다. var가 foreach 함수 호출 이전에 정의된 것이 아니라면 이것은 그 호출 뒤에도 정의된 것이 아니다. See section 변수의 두 취향(The Two Flavors of Variables).
변수들 이름들을 결과로 가지는 복잡한 변수 표현식을 사용할 때 상당히 조심해야 한다. 왜냐면 많은 이상한 것들이 유효한 변수 이름들이지만 여러분이 의도한 것이 아닐 수도 있기 때문이다. 예를 들어서,
files := $(foreach Esta escrito en espanol!,b c ch,$(find_files))
이것은 find_files 값이 이름이 `Esta escrito en espanol!' (es un nombre bastante largo, no?) 인 변수를 참조하고 있다면 유용하겠지만 이것은 실수일 가능성이 더많다.
origin 함수(The origin Function)
origin 함수는 변수들의 값에서 나타나지 않는다는 점에서 다른 함수들과 다르다; 이것은 하나의 변수에 대해서 어떤 것을 말하는 것이다. 특별히 이것은 이것이 어디로부터 온 것인가를 말한다.
origin 함수의 문법은 다음과 같다:
$(origin variable)
variable은 질의하고 있는 변수의 이름이다; 그 변수에 대해서 참조하는 것은 아니다. 그러므로 그것을 쓸 때 `$'나 괄호들을 일반적인 경우처럼 쓰지 않을 것이다. (그러나 그 이름안에서 변수 참조를 쓸 수 있다. 상수가 아닌 이름을 원한다면 말이다.)
이 함수의 결과는 그 변수 variable이 정의된 방법을 말하는 문자열이다:
`undefined'
변수 variable이 전혀 정의된 바가 없다면 이 값을 가진다.
`default'
변수 variable이, CC나 기타 등등처럼 일반적인 디폴트 정의를 갖고 있다면 이 값을 가진다. See section 묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules). 디폴트 변수를 재정의한 것이라면 origin 함수는 추후 정의의 원천(origin)을 리턴할 것이다.
`environment'
variable이 환경 변수로써 정의된 것이고 `-e' 옵션이 켜진 것이 아니라면 이 값을 가진다. (see section 옵션들의 요약(Summary of Options)).
`environment override'
variable가 환경 변수로 정의되었고 `-e' 옵션이 켜졌다면 이 값을 가진다 (see section 옵션들의 요약(Summary of Options)).
`file'
variable가 makefile에서 정의된 것이라면 이 값을 가진다.
`command line'
variable이 명령행에서 정의된 것이라면 이 값을 가진다.
`override'
variable가 override 지시어로 makefile에서 정의된 것이라면 이 값을 가진다 (see section override 지시어).
`automatic'
variable이 각 규칙의 명령들의 실행에 대해서 정의된 자동 변수라면 이 값을 가진다 (see section 자동 변수들(Automatic Variables)).
이 정보는 주로 어떤 변수의 값을 믿고자 하는가 안하는가를 결정할 때 유용하다 (호기섬을 충족하는 것 말고). 예를 들어서 다른 makefile `bar'를 포함하는 makefile `foo'를 가지고 있다고 가정하자. 명령 `make -f bar'를 실행한다면, 환경이 bletch의 정의를 갖고 있다고 하더라도, bletch가 `bar'에 정의된 것을 원한다. 그러나 `foo'가 `bar'를 포함하기 전에 bletch를 정의했다면 그 정의를 오버라이드하기를 원하지 않을 것이다. 이것은 override 지시어를 `foo'에서 사용하고 그 정의를 `bar'에서 나중의 정의 이전에 정의함으로써 그렇게 할 수 있다; 불행하게도 override 지시어는 모든 명령행 정의들을 오버라이드할 것이다. 그래서, `bar'는 다음을 포함할 수 있을 것이다.
ifdef bletch
ifeq "$(origin bletch)" "environment"
bletch = barf, gag, etc.
endif
endif
bletch가 환경으로부터 정의되었다면 이것은 그것을 재정의할 것이다.
bletch의 이전 정의를 override하고자 하고 이것이 환경으로부터 온 것이라면, `-e'하에서조차, 여러분은 다음과 같이 쓸수 있을 것이다:
ifneq "$(findstring environment,$(origin bletch))" ""
bletch = barf, gag, etc.
endif
여기서 `$(origin bletch)'가 `environment' 또는 `environment override' 를 리턴한다면 재정의가 일어난다. See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
shell 함수(The shell Function)
shell 함수는 wildcard 함수 (see section wildcard 함수(The Function wildcard))를 제외하고, 이것이 make의 바깥 세상과 통신한다는 점에서, 다른 함수들과 다르다.
shell 함수는 대부분의 쉘에서 역홑따옴표(``')가 수행하는 기능과 동일한 기능을 수행한다: 이것은 command expansion을 한다. 이것은 쉘 명령인 매개변수를 취하고 명령의 결과를 리턴한다는 것을 의미한다. make가 이 결과에 대해서, 주변 텍스트로 이것을 대입하기 전에, 하는 유일한 처리는 각 개행이나 캐리지-리턴 / 개행 쌍을 단일 공백으로 변환하는 것이다. 이것은 또한 끝에 달린 (캐리지-리턴과) 개행을, 이것이 결과의 마지막이라면, 제거한다.
shell함수에 대한 호출에 의해서 실행된 명령은 함수 호출이 확장될 때 실행된다. 대부분의 경우 이것은 makefile이 읽힐 때이다. 규칙의 명령안에 있는 함수 호출들은 그 명령이 실행될 때 확장된다는 것이 예외이며, 이것은 다른 모든 것들과 마찬가지로 shell이라는 함수 호출에도 적용되는 것이다.
다음은 shell 함수의 사용에 대한 몇가지 예제들이다:
contents := $(shell cat foo)
이것은 contents를 `foo' 파일의 내용으로 설정한다. 각 라인을 분리하는 공백들(개행이라기 보다는)로.
files := $(shell echo *.c)
이것은 files를 `*.c'의 확장으로 설정한다. make가 아주 이상한 쉘을 사용하고 있지 않다면 이것은 `$(wildcard *.c)'과 동일한 결과를 얻는다.
make 실행 방법(How to Run make)
어떤 프로그램을 어떻게 재컴파일할 것인가를 말하는 makefile은 한가지 이상의 방법으로 사용될 수 있다. 가장 간단한 사용은 out of date인 모든 파일을 재컴파일하는 것이다. 보통 makefile들은 여러분이 make를 매개변수 없이 실행한다 하더라도 그렇게 하도록 작성된다.
그러나 여러분은 이런 파일들 중에서 몇개만 업데이트하고자 할런지도 모른다; 여러분은 다른 컴파일러나 다른 컴파일 옵션들을 사용하고자 할런지도 모른다; 여러분은 또는, 그것들을 변경하지 않고서 어떤 파일이 out of date인지를 알아내고자 할런지도 모른다.
여러분이 make를 실행할 때 매개변수들을 주어서 여러분이 이런 것들이나 다른 많은 것들을 할 수 있다.
make의 종료 코드는 항상 다음 세가지 값들 중의 하나이다:
0
make가 성공하면 종료 코드는 0이다.
2
어떤 에러를 만났다면 종료 코드는 2이다. 이것은 특정 에러를 설명하는 메시지들을 출력할 것이다.
1
`-q' 플래그를 사용하였고 make가 어떤 타겟이 아직 up to date가 아니라고 판단하면 종료 코드는 1이다. See section 명령 실행 대신에...(Instead of Executing the Commands).
Makefile을 지정하는 매개변수(Arguments to Specify the Makefile)
makefile의 이름을 지정하는 방법은 `-f'나 `--file' 옵션을 사용하는 것이다(`--makefile'도 작동한다). 예를 들어서 `-f altmake'라는 옵션은 `altmake'을 makefile로 사용하라고 말하는 것이다.
`-f' 플래그를 여러번 사용하였고 각각의 `-f' 뒤에 매개변수가 따른다면 모든 지정된 파일들은 서로 묶여서 makefile로 사용된다.
`-f' 또는 `--file' 플래그를 사용하지 않는다면 `GNUmakefile', `makefile', 그리고 `Makefile'를 이 순서대로 있나 없나 검사해보고 있는 첫번째의 것을 또는 만들어질 수 있는 첫번째의 것을 사용하는 것이 디폴트이다. (see section Makefiles 작성(Writing Makefiles)).
goal을 지정하는 매개변수(Arguments to Specify the Goals)
goals은 make가 궁극적으로 업데이트하려고 할 타겟들이다. 다른 타겟들은 그들이 goal의 종속물이나 goals의 종속물의 종속물 등으로 나타난다면 업데이트된다.
디폴트로 goal은 makefile의 첫번째 타겟이다(점으로 시작하는 타겟은 계산하지 않는다). 그러므로 makefile들은 보통 첫번째 타겟이 전체 프로그램을 컴파일하기 위한 것이나 그들이 설명하는 프로그램들을 컴파일하기 위한 것이다. makefile의 첫번째 규칙이 여러개의 타겟들을 가진다면 그 규칙의 첫번째 타겟이, 전체 리스트가 아니라, 디폴트 goal이 된다.
여러분은 make에다 다른 goal이나 매개변수를 가진 goal을 지정할 수 있다. goal의 이름을 매개변수처럼 사용하면 된다. 몇개의 goal을 지정한다면 make는 각각을 주어진 차례대로 처리한다.
makefile에 있는 임의의 타겟은 goal로 지정될 수 있다(그것이 `-'로 시작하거나 `='를 담고 있지 않다면 말이다. 이런 경우 일반적인 옵션인 switch나 변수 정의로 각각 생각되어진다.) make가 그것들을 만드는 방법을 말한 묵시적 규칙들을 찾을수만 있다면, makefile에 없는 타겟들도 지정될 수 있다.
Make 는 특수변수 MAKECMDGOALS를 명령 라인에서 여러분이 지정한 goal들의 리스트로 지정할 것이다. 명령 라인에 어떤 goal도 지정되지 않았다면 이 변수는 빈 것이 된다. 이 변수는 특수한 상황에서만 사용되어야 한다는 것에 주의하자.
`.d' 파일들을 clean 규칙들 see section 종속물들을 자동으로 생성하기(Generating Dependencies Automatically)) 동안에 포함하는 것을 피해서 make가 그들을 다시 즉각 제거하기 위해서만 그들을 생성하지 않도록 하는 것이 적절한 사용의 예이다:
sources = foo.c bar.c
ifneq ($(MAKECMDGOALS),clean)
include $(sources:.c=.d)
endif
프로그램의 한 부분만을 컴파일하고자 하거나 여러 프로그램들 중의 하나만 컴파일하고자 할 경우가 목적을 지정하는 한가지 사용법이다. 다시 만들고자 하는 각 파일을 목적으로 지정하자. 예를 들어서 몇가지 프로그램들을 담고 있는 디렉토리를 생각해보자. 다음과 같이 시작하는 makefile과 함께:
.PHONY: all
all: size nm ld ar as
프로그램 size에 대해서 작업하고 있다면 `make size' 라고 해서 그 프로그램의 파일들만이 재컴파일되도록 하기를 원할 것이다.
목적(goal)을 지정하는 다른 사용법은, 일반적인 모드가 아닌 파일들을 만드는 것이다. 예를 들어서 디버깅 결과인 파일이나 테스트를 위해서 특별히 컴파일된 프로그램이 있을 수 있다. 이들은 디폴트 목적의 종속물이 아닌 makefile내의 규칙을 가진다.
목적을 지정하는 다른 사용법은 포티 타겟 (see section 가짜 목적물(Phony Targets)) 이나 빈 타겟 (see section 이벤트를 기록하기 위한 빈 타겟 파일(Empty Target Files to Record Events) 과 연결된 명령들을 실행하는 것이다. 많은 makefile들이 소스 파일들을 제외한 모든 것들을 삭제하는 `clean'이라는 이름의 포니 타겟을 담고 있다. 자연스럽게 이것은 여러분이 `make clean'라고 명시적으로 요구할 때에만 수행된다. 다음은 전형적인 포니 및 빈 타겟 이름들이다. GNU 소프트웨어 팩키지들이 사용하는 표준 타겟 이름들의 전체를 보려면 See section 사용자들을 위한 표준 타겟(Standard Targets for Users).
`all'
이것은 makefile이 알고 있는 톱-레벨 타겟들 모두를 make 한다.
`clean'
이것은 일반적으로 make를 실행함으로써 생성되는 모든 파일들 삭제한다. Delete all files that are normally created by running make.
`mostlyclean'
이것은 `clean'과 비슷하지만 사람들이 일반적으로 재컴파일하고자 원하지 않는 몇가지 파일들을 지우지 않을 것이다. 예를 들어서 GCC 를 위한 `mostlyclean' 타겟은 `libgcc.a'를 지우지 않는다. 왜냐면 이것을 재컴파일하는 것은 거의 필요없는 것이고 시간만 소비하기 때문이다.
`distclean'
`realclean'
`clobber'
이런 타겟들은 `clean'이 하는 것보다 더 많은 파일들을 지우기 위해서 정의될 것이다. 예를 들어서 이것은 컴파일을 준비하기 위해서 일반ㅈ거으로 생성한 링크들이나 설정 파일들을 지울 것이다. 비록 makefile 그 자체는 이들을 생성하지 않았다 하더라도 말이다.
`install'
이것은 실행 파일을 사용자가 전형적으로 명령들에 대해서 찾는 위치의 디렉토리에다 복사한다; 실행 파일들이 상요하는 보조 파일들도 이들을 찾을 위치의 디렉토리들에 복사한다.
`print'
변경된 소스 파일들의 리스트를 인쇄
`tar'
소스 파일들의 tar 파일을 생성한다.
`shar'
이것은 소스 파일들의 쉘 아카이브(shar 파일)을 생성한다.
`dist'
이것은 소스 파일들의 배포 파일을 생성한다. 이것은 아마도 tar 파일이거나 shar 파일이거나 위의 것들 중 하나의 압축된 버전이거나 이들과 다른 것일 것이다.
`TAGS'
이 프로그램에 대한 태그 테이블을 업데이트한다.
`check'
`test'
makefile 이 빌드하는 프로그램에 대해서 자체 테스트를 수행한다.
명령 실행 대신에...(Instead of Executing the Commands)
makefile은 make에게 타겟이 up to date인가 아닌가 어떻게 판단할 것인가, 그리고 각 타겟을 어떻게 업데이트할 것인가를 지정한다. 그러나 타겟을 업데이트하는 것은 항상 여러분이 원하는 것이 아닐 수도 있다. 어떤 옵션들은 make의 다른 액션을 지정한다.
`-n'
`--just-print'
`--dry-run'
`--recon'
"No-op".
어떤 명령들이 타겟들을 업데이트하기 위해서 사용될 것인가를 출력한다. 그러나 실제 그들을 실행시키지는 않는다.
`-t'
`--touch'
"Touch". 그것을 실제로 변경하지 않고서 타겟들을 마치 업데이트된 것처럼 마킹한다. 다른 말로 해서 make는 컴파일하는 것처럼 가장하지만 실제로는 그들의 내용물들을 변경하지 않는다.
`-q'
`--question'
"Question". 조용히 어떤 타겟들이 이미 업데이트되었는지 아닌지를 찾는다; 그러나 어떤 경우에도 어떤 명령도 실행하지 않는다. 다른말로 하면 컴파일도 안하고 어떤 출력도 일어나지 않는다.
`-W file'
`--what-if=file'
`--assume-new=file'
`--new-file=file'
"What if". 각 `-W' 플래그는 파일 이름이 뒤따른다. 주어진 파일들의 변경 시간들은 make에 의해서 현재 시간으로 기록되는 반면 실제 변경 시간은 동일하게 남는다. `-W' 플래그와 `-n' 플래그를 사용해서 여러분이 특정 파일을 변경한다면 어떤 일이 벌어지는지 확인할 수 있다.
`-n' 플래그를 주면 make는 실제 그들을 실행하지 않지만 일반적인 실행 때와 동일한 명령들을 인쇄한다.
`-t' 플래그를 주면 make는 규칙들에 있는 명령들을 무시하고 다시 만들어져야 할 각 타겟에 대해서 touch라는 명령을 (사실상) 사용한다. `-s'나 .SILENT가 사용되지 않으면, touch 명령 또한 인쇄된다. 속도를 위해서 make는 실제로 프로그램 touch를 호출하지 않을 것이다. 이것은 직접 작업한다.
`-q' 플래그로 make는 아무것도 출력하지 않고 아무런 명령도 실행하지 않지만 종료 상태 코드는 타겟이 이미 갱신된 것이라고 생각되어질 때에만 0이 된다. 종료 상태가 1이면 어떤 갱신이 필요하다는 것을 의미한다. maek가 에러를 만나면 종료 상태는 2이다. 그래서 에러를 타겟이 갱신안되었다는 것과 구분할 수 있다.
이런 세 플래그들 중의 하나 이상을 make의 어떤 호출안에서 사용하는 것은 에러이다.
`-n', `-t', 그리고 `-q' 옵션들은 `+' 문자들로 시작하는 명령 라인들이나 `$(MAKE)'나 `${MAKE}' 문자열들을 담고 있는 명령 라인들에 영향을 미치지 않는다. `+' 문자나 문자열 `$(MAKE)' 또는 `${MAKE}'를 담고 있는 라인들만이 이런 옵션들에 상관없이 실행된다. 동일한 규칙에 있는 다른 라인들은 그들이 `+'로 시작하지 않았거나 `$(MAKE)'나 `${MAKE}'를 담고 있지 않는다면 실행되지 않을 것이다. (See section MAKE 변수가 작동하는 방법(How the MAKE Variable Works).)
`-W' 플래그는 다음과 같은 두 기능을 제공한다:
● `-n'나 `-q' 플래그와 같이 사용하면 여러분은 어떤 파일들을 변경했을 때 make가 어떻게 할 것인가를 볼 수 있다.
● `-n'나 `-q' 플래그 없이, make가 실제로 명령들을 실행할 때, `-W' 플래그는 make가 어떤 파일들이 변경된 것처럼, 실제로 파일들을 변경하지 않고, 작동한다.
`-p'와 `-v' 옵션들은 make나 사용중인 makefile에 대한 정보를 얻을 수 있도록 한다는 점에 주목하자. (see section 옵션들의 요약(Summary of Options)).
어떤 파일들을 재컴파일하는 것을 피하기(Avoiding Recompilation of Some Files)
가끔 소스 파일을 변경했지만 그것에 의존하는 모든 파일들을 재컴파일하고자 원치 않을 수 있다. 예를 들어서 많은 다른 파일들이 의존하고 있는 대상 헤더 파일에다 매크로나 선언을 추가했다고 가정하자. 보수적으로 생각하면 make는 헤더 파일 내용을 변경하면 이것에 의존하는 모든 파일들을 재컴파일해야 한다고 가정한다. 그러나 그들이 반드시 재컴파일될 필요는 없고 그들이 컴파일되는 것을 기다리면서 시간을 낭비하고 싶지 않을 것이다.
헤더 파일을 변경하기 전에 문제들을 예견한다면 `-t' 플래그를 사용할 수 있다. 이 플래그는 make가 규칙들 안에 있는 명령들을 실행하지 않도록 하고 타겟의 최종-변경 시간을 바꿈으로써 타겟이 변경된 것으로 마크한다. 여러분은 다음과 같은 과정을 따를 것이다:
1. 명령 `make'를 사용해서 실제로 재 컴파일이 필요한 소스 파일들을 재컴파일한다.
2. 헤더 파일들을 변경한다.
3. 명령 `make -t'를 사용해서 모든 오브젝트 파일들이 갱신된 것처럼 마킹한다. 다음 번에 여러분이 make를 실행할 때면 헤더 파일의 변화는 어떤 재컴파일도 일으키지 않을 것이다.
이미 헤더 파일을 어떤 파일들이 재컴파일이 필요한 때에 변경하였다면 너무 느린 것이어서 이렇게 할 수 없다. 대신에 여러분은 `-o file' 플래그를 사용할 수 있다. 이것은 특정 파일을 "구닥다리(old)"로 마킹한다 (see section 옵션들의 요약(Summary of Options)). 이것은 그 파일 자체가 다시 만들어지지 않을 것이며 다른 어떤 것도 이것을 위해서 다시 만들어지지 않ㅇ르 것이다. 다음 과정을 따르자:
1. 특정 헤더 파일과 무관한 이유 때문에 컴파일이 필요한 소스 파일들을 `make -o headerfile'를 가지고 재컴파일한다. 몇가지 헤더 파일들이 포함되어 있다면 독립된 `-o' 옵션을 각 헤더 파일에 상요한다.
2. 모든 오브젝트 파일들을 `make -t'로 터치한다.
변수 겹쳐쓰기(Overriding Variables)
`='를 담고 있는 매개변수는 어떤 변수의 값을 지정한다: `v=x'는 변수 v의 값을 x으로 설정한다. 여러분이 이런식으로 값을 지정한다면 makefile내에 있는 동일한 변수의 모든 일반적인 대입은 무시된다; 우리는 이럴 때 명령 라인 매개변수에 의해서 overridden되었다고 말한다.
이런 기능을 사용하기 위한 대부분의 일반적인 방법은 컴파일러에게 외부 플래그들을 전달하는 것이다. 예를 들어서 적절히 작성된 makefile에서 변수 CFLAGS는 C 컴파일러를 실행하는 각 명령에 포함되고 그래서 `foo.c'는 다음과 같이 컴파일될 것이다:
cc -c $(CFLAGS) foo.c
그래서 여러분이 CFLAGS에 대해서 설정한 값이면 무엇이든 발생하는 각 컴파일에 대해서 영향을 미친다. makefile은 아마도 CFLAGS에 대한 일반적인 값으로써 다음과 같이 지정할 것이다:
CFLAGS=-g
make를 실행할 때마다 여러분은, 원한다면, 이 값을 오버라이드할 수 있다. 예를 들어서 `make CFLAGS='-g -O''라고 말한다면 각 C 컴파일은 `cc -c -g -O'로 행해질 것이다. (이것은 변수의 값을 오버라이드할 때 변수의 값안의 스페이스들이나 특수 문자들을 감싸기 위해서 쉘에서 인용(quoting)을 어떻게 사용할 수 있는가를 예시한다.)
변수 CFLAGS는, 그들을 이런식으로 변경할 수 있도록 존재하는 많은 표준 변수들 중에서 유일한 것이다. 완전한 리스트를 보려면 See section 묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules).
makefile이 여러분 자신만의 추가의 변수들을 찾도록 프로그래밍할 수 있다. 그리고 사용자에게 makefile이 작동하는 방식의 다른 면들을 그 변수들을 바꿔서 제어하는 능력을 줄 수 있다.
어떤 변수를 명령 매개변수들로 오버라이드할 때 재귀적으로-확장되는 변수나 단순하게-확장되는 변수 둘 중에 하나를 정의할 수 있다. 위에서 보여진 예제들은 재귀적으로-확장되는 변수를 만든 것이다; 단순하게-확장되는 변수를 만들기 위해서 `=' 대신 `:='를 쓴다. 그러나 변수 참조나 함수 호출을 지정한 value안에 포함하고자 하지 않는다면 어떤 종류의 변수를 생성하든 똑같다.
makefile이 오버라이드한 변수를 변경할 수 있는 길은 하나 있다. 이것은 override 지시어를 사용하는 것이다. 이것은 다음과 같이 보이는 라인이다: `override variable = value' (see section override 지시어).
프로그램의 컴파일 테스트(Testing the Compilation of a Program)
일반적으로 쉘 명령을 실행할 때 에러가 발생하면 make는 즉각 포기하고 영이 아닌 상태값을 리턴한다. 더이상 어떤 타겟의 명령들도 실행되지 않는다. 에러가 발생했다는 것은 goal이 정확하게 다시 빌드될 수 없다는 것을 얘기하는 것이기 때문에 make는 이것을 아는 즉시 보고한다.
방금 수정한 어떤 프로그램을 컴파일할 때 이것은 여러분이 원하는 것이 아닐 수 있다. 대신에 make가 얼마나 많은 컴파일 에러가 나오는지 확인하기 위해서, 시도될 수 있는 모든 파일을 컴파일하려고 하는 것을 바랄 것이다.
이런 경우 `-k' 나 `--keep-going' 플래그를 사용해야 한다. 이것은 make가 계류중인 타겟의 다른 종속물들을 계속 생각하도록 해서 그들이 필요하다면, 포기하고 0이 아닌 상태값을 리턴하기 전에, 다시 만든다. 예를 들어서 하나의 오브젝트 파일을 컴파일하면서 에러가 나온 후, `make -k'는 그것들을 링크하는 것이 불가능하다는 것을 알더라도 다른 오브젝트 파일들을 계속 컴파일할 것이다. 쉘 명령들이 실패한 후 계속할 뿐만이 아니고, `make -k'는 타겟이나 종속 파일들을 만드는 방법을 모른다는 사실을 발견한 후에도 가능한 한 계속한다. 이것은 항상 에러 메시지를 유발하지만 `-k'가 없었다면 이것은 치명적인 에러일 것이다 (see section 옵션들의 요약(Summary of Options)).
make의 일반적인 행동은 여러분의 목적이 goal들이 갱신되도록 하는 것이라고 가정한다; 일단 make가 이것이 불가능한 것을 알면 그 실패를 즉각 보고할 것이다. `-k' 플래그는 실제 목적이 프로그램에서 변경된 부분들을 가능한 한 많이 테스트하는 것이라는 것을 말하는 것이다. 아마도 몇가지 독립적인 문제들을 찾아서 그것들을 다음 컴파일 시도하기 전까지, 교정할 수 있기 위해서 말이다. 이것은 왜 이맥스의 M-x compile 명령이 디폴트로 `-k' 플래그를 전달하는가에 대한 이유이다.
옵션들의 요약(Summary of Options)
다음은 make가 이해하는 모든 옵션들의 테이블이다:
`-b'
`-m'
이런 옵션들은 다른 버전의 make와의 호환성을 위해서 무시된다.
`-C dir'
`--directory=dir'
makefile을 읽기 전에 dir 디렉토리로 변경한다. 다수의 `-C' 옵션들이 지정되면 각각은 이전의 것과 상대적인 것으로 해석된다: 그래서 `-C / -C etc'는 `-C /etc'과 동일한다. 이것은 make의 재귀적인 호출에서 전형적으로 사용된다. (see section make의 재귀적 사용(Recursive Use of make)).
`-d'
`--debug'
일반적인 처리에 덧붙여 디버깅 정보를 출력한다. 디버깅 정보는 어떤 파일들이 다시 만들어져야 하는 것으로 생각되고 있는지 어떤 파일-시간들이 어떤 결과들과 비교되고 있는지 그리고 어떤 묵시적 규칙들이 생각되고 있는지와 어떤 것이 적용되는지에 대해서 말해준다---make가 할 것을 어떻게 결정할 것인가에 대한 모든것.
`-e'
`--environment-overrides'
이것은 환경으로부터 취해진 변수들이 makefile의 변수들보다 더 우선하도록 한다. See section 환경으로부터의 변수들(Variables from the Environment).
`-f file'
`--file=file'
`--makefile=file'
file을 makefile로 읽는다. See section Makefiles 작성(Writing Makefiles).
`-h'
`--help'
make가 이해하는 옵션들을 보여주고 종료한다.
`-i'
`--ignore-errors'
파일들을 다시 만들기 위해서 실행되는 명령들에서 모든 에러들을 무시한다. See section 명령에서 에러(Errors in Commands).
`-I dir'
`--include-dir=dir'
포함된 makefile들을 찾기 위해서 dir 디렉토리를 지정한다. See section 다른 makefile 삽입(Including Other Makefiles). 몇개의 `-I' 옵션들이 몇가지 디렉토리들을 지정하기 위해서 사용되면 이 디렉토리들은 지정된 순서로 검색된다.
`-j [jobs]'
`--jobs=[jobs]'
동시에 실행하는 작업들(명령들)의 개수를 지정한다. 매개변수없이 사용하면 make는 가능한 한 많은 작업들을 실행한다. 하나 이상의 `-j'옵션이 있으면 마지막 것이 사용된다. 명령들이 어떻게 실행되는가에 대한 더 많은 정보에 대해서는, See section 패러럴 실행(Parallel Execution). 이 옵션은 MS-DOS에서 무시된다는 것에 주의하자.
`-k'
`--keep-going'
에러 이후에도 가능한 한 계속하도록 한다. 실패한 타겟, 이것에 의존하는 타겟들 등이 다시 만들어질 수 없는 반면 이런 타겟들의 다른 종속물들은 동일하게 처리될 수 있다. See section 프로그램의 컴파일 테스트(Testing the Compilation of a Program).
`-l [load]'
`--load-average[=load]'
`--max-load[=load]'
다른 작업들이 있고 평균 부하가 적어도 load (부동소숫점 숫자) 이라면 어떤 새로운 작업들(명령들)도 시작되지 않도록 한다. 매개변수가 없으면 이전의 부하 제한을 제거한다. See section 패러럴 실행(Parallel Execution).
`-n'
`--just-print'
`--dry-run'
`--recon'
실행될 명령들을 인쇄하지만 그들을 실행하지는 않는다. See section 명령 실행 대신에...(Instead of Executing the Commands).
`-o file'
`--old-file=file'
`--assume-old=file'
file 라는 파일이 그것의 종속물들보다 더 오래된 것이라도 다시 만들지 않으며 file의 변경이 있더라도 아무것도 다시 만들지 않도록 한다. 기본적으로 이 파일은 아주 오래된 것으로 취급되며 그것의 규칙은 무시된다. See section 어떤 파일들을 재컴파일하는 것을 피하기(Avoiding Recompilation of Some Files).
`-p'
`--print-data-base'
makefile들을 읽은 결과의 데이터베이스(규칙들과 변수 값들)을 인쇄한다; 그리고 나서 보통때처럼 실행하거나 지정된 것처럼 한다. 이것은 또한 `-v' 스위치(아래 참조)에 의해서 주어진 버전 정보를 출력한다. 어떤 파일들도 다시 만들려고 노력하지 않고서 데이터베이스를 출력하려면 `make -p -f /dev/null'를 사용한다.
`-q'
`--question'
"질문 모드(Question mode)". 어떤 명령도 실행하지 않고 어떤 것도 출력하지 않도록 한다; 단지 종료 상태값만 리턴한다. 지정된 타겟이 이미 갱신되었다면 0을 리턴하고 리메이크가 필요하다면 1을 리턴하고, 에러를 만났다면 2를 리턴한다. See section 명령 실행 대신에...(Instead of Executing the Commands).
`-r'
`--no-builtin-rules'
내장 묵시적 규칙들의 사용을 제거한다 (see section 묵시적 규칙(Using Implicit Rules)). 여러분 자신만의 것을 패턴 규칙들을 작성함으로서 정의할 수 있다 (see section 패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules)). `-r' 옵션은 또한 접미사 규칙들에 대한 디폴트 접미사 리스트를 완전히 청소한다 (see section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules)). 그러나 .SUFFIXES에 대한 규칙으로 자신만의 접미사들을 정의할 수 있고, 자신만의 접미사 규칙들을 정의할 수 있다. 단지 규칙들만이 -r 옵션에 의해서 영향을 받는다; 디폴트 변수들은 그대로 효력이 있다 (see section 묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules)).
`-s'
`--silent'
`--quiet'
조용한 작업; 그들이 실행될 때 명령들이 인쇄되지 않는다. See section 명령 에코(Command Echoing).
`-S'
`--no-keep-going'
`--stop'
`-k' 옵션의 효력을 취소한다. 이것은 톱레벨 make로부터 MAKEFLAGS를 통해서 `-k'가 승계된 재귀적인 make 외에는 절대 필요가 없다 (see section make의 재귀적 사용(Recursive Use of make)). 아니면 환경의 MAKEFLAGS에다 `-k'를 설정하였을 때.
`-t'
`--touch'
z명령들을 실행하지 않고 파일들을 터치(실제로 그들을 변경하지 않고서 날짜 시간만 현재 시간으로 마크). 이것은 make의 추후 실행을 속이기 위해서 그 명령이 실행된 것처럼 만든다. See section 명령 실행 대신에...(Instead of Executing the Commands).
`-v'
`--version'
make 프로그램의 버전과 저작권, 개발자 리스트, 그리고 어떤 보증도 없다는 아림을 보여주고 종료한다.
`-w'
`--print-directory'
makefile을 실행하기 전과 후에 작업디렉토리를 담고 있는 메시지를 출력한다. 이것은 복잡하게 포개진 재귀적인 make 명령들로 부터 에러를 추적하는 데 유용할 수 있다. See section make의 재귀적 사용(Recursive Use of make) (실제로 여러분은 `make'가 이것을 하기 때문에 일부러 지정할 필요는 거의 없다; section `--print-directory' 옵션 참조.)
`--no-print-directory'
-w 하에서 작업 디렉토리를 출력하는 것을 금지함. 이 옵션은 -w가 자동으로 켜질 때 유용하지만 여분의 메시지들을 보고 싶지 않을 것이다. See section `--print-directory' 옵션.
`-W file'
`--what-if=file'
`--new-file=file'
`--assume-new=file'
타겟 file이 방금 변경된 것처럼 가장한다. `-n' 플래그와 함께 사용될 때, 이것은 그 파일을 변경한다면 무슨일이 일어나는 가를 보여준다. `-n' 없이 쓰면 이것은 make를 실행하기 전에 주어진 파일에 대해서 touch 명령을 실행하는 것과 거의 유사하다. 단 변경 시간이 make의 상상력 안에서만 변경된다는 것만 빼고 말이다. See section 명령 실행 대신에...(Instead of Executing the Commands).
`--warn-undefined-variables'
make가 정의되지 않은 변수에 대한 참조를 볼 때마다 경고 메시지를 발행한다. 이것은 변수들을 복잡하게 사용하는 makefile을 디버그하려고 할 때 유용할 수 있다.
묵시적 규칙(Using Implicit Rules)
타겟 파일들을 리메이크하는 어떤 표준 방법들이 자주 사용된다. 예를 들어서 오브젝트 파일을 만드는 통상적인 방법은 C 소스로부터 C 컴파일러, cc를 사용하는 것이다.
묵시적 규칙(Implicit rules) 은 사용하고자 할 때 그것들을 자세하게 지정할 필요없도록, 통상적인 테크닉들을 사용하는 방법을 make 에게 말한다. 예를 들어서 C 컴파일을 위한 묵시적 규칙이 있다. 파일 이름들이 어떤 묵시적 규칙들이 실행될 것인가를 결정한다. 예를 들어서 C 컴파일은 `.c' 파일을 보통 취해서 `.o' 파일을 만든다. 그래서 make는 이것이 파일 이름의 끝부분들(확장자들)의 조합을 볼 때 C 컴파일을 위한 묵시적 규칙을 적용한다.
묵시적 규칙들의 연쇄고리가 순차적으로 적용될 수 있다; 예를 들어서, make는 `.y' 파일로부터 `.o' 파일을, `.c' 파일을 경유해서 리메이크할 것이다. See section 묵시적 규칙의 연쇄(Chains of Implicit Rules).
내장 묵시적 규칙들은, 변수들의 값들을 변경해서 여러분이 묵시적 규칙들이 작동하는 방식을 변경할 수 있도록, 그들의 명령에서 몇가지 변수들을 사용한다. 예를 들어서 변수 CFLAGS 는 C 컴파일을 위한 묵시적 규칙에 의해서 C 컴파일러에게 주어진 플래그들을 제어한다. See section 묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules).
여러분 자신만의 묵시적 규칙들을 패턴 규칙들(pattern rules)를 작성함으로써 정의할 수 있다. See section 패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules).
접미사 규칙(uffix rules) 은 묵시적 규칙들을 정의하는 좀 더 제한된 방식이다. 패턴 규칙들이 좀 더 일반적이고 명쾌한 것이지만 접미사 규칙들은 호환성을 위해서 아직 남아 있다. See section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules).
묵시적 규칙 사용(Using Implicit Rules)
make가 타겟 파일을 갱신하기 위한 관습적인 방법을 찾도록 하기 위해서 여러분이 해야 할 일은 명령들을 스스로 지정하지 않도록 하는 것이 전부이다. 명령 라인들이 없는 규칙을 작성하거나 그런 규칙을 전혀 작성하지 말자. 그러면 make는 사용할 묵시적 규칙을, 어떤 종류의 소스 파일이 존재하는가와 만들어질 수 있는가에 기반해서, 찾아낼 것이다.
예를 들어서 makefile이 다음과 같이 생겼다고 하자:
foo : foo.o bar.o
cc -o foo foo.o bar.o $(CFLAGS) $(LDFLAGS)
`foo.o'를 언급했지만 그것에 대한 규칙을 지정하지 않았기 때문에 make는 자동으로 그것을 갱신하는 방법을 말하는 묵시적 규칙을 찾을 것이다. 이것은 `foo.o'가 현재 존재하는지 안하는지에 상관없이 일어난다.
묵시적 규칙이 있으면 이것은 명령들과 하나 이상의 종속물들(소스 파일들) 모두를 공급할 수 있다. 묵시적 규칙이 공급할 수 없는, 헤더 파일들과 같은, 추가의 종속물들을 지정해야 한다면, `foo.o'에 대한 규칙을 명령 라인들이 없이 작성하고자 할 것이다.
각 묵시적 규칙은 하나의 타겟 패턴과 종속물 패턴들을 가진다. 동일한 타겟 패턴을 가지는 많은 묵시적 규칙들이 존재할 수 있다. 예를 들어서 많은 규칙들이 `.o' 파일들을 만들 수 있다: 하나는, `.c' 파일로부터 C 컴파일러를 사용할수도 있고; 다른 것은, `.p' 파일로부터 파스칼 컴파일러를 사용할 수도 있다; 기타 등등. 실제로 적용되는 규칙은 그것의 종속물이 존재하거나 만들어질 수 있는 것 하나이다. 그래서 파일 `foo.c'를 가진다면, make는 C 컴파일러를 실행할 것이다; 그렇지 않고 `foo.p'를 가진다면 make는 파스칼 컴파일러를 실행할 것이다; 기타 등등.
물론, makefile을 작성할 때 여러분은 make가 사용했으면 하는 묵시적 규칙이 어떤 것인가를 알고 있으며, 어떤 종속 파일들이 존재할 것인가를 알고 있기 때문에 make가 그것을 선택할 것이라는 것을 안다. 모든 사전에 정의된 묵시적 규칙들 카달로그를 보려면 See section 묵시적 규칙들의 카달로그(Catalogue of Implicit Rules).
위에서 우리는 하나의 묵시적 규칙이, 요구된 종속물들이 "존재하거나 만들어질 수 있으면" 적용된다고 말했다. 파일은 그것이 maekefile에서 타겟이나 종속물로 명시적으로 지정되고 묵시적 규칙이 그것을 만드는 방법을 재귀적으로 알아낼 수 있다면, "만들어질 수 있다". 묵시적 종속물이 다른 묵시적 규칙의 결과이라면 우리는 연쇄작용(chaining)이 일어났다고 말한다. See section 묵시적 규칙의 연쇄(Chains of Implicit Rules).
일반적으로 make는 각 타겟에 대해서 명령이 없는 묵시적규칙, 각 더블-콜론 규칙을 검색한다. 종속물로만 언급된 파일은, 타겟의 규칙이 아무것도 지정하지 않는 타겟으로 생각되고, 그래서 이것에 대한 묵시적 규칙이 검색된다. 검색이 이루어지는 방법에 대한 자세한 내용은 See section 묵시적 규칙 검색 알고리즘(Implicit Rule Search Algorithm).
명시적 종속물들은 묵시적 규칙 검색에 아무런 영향도 미치지 않는다는 점에 주목하자. 예를 들어서 다음과 같은 명시적 규칙을 생각하자:
foo.o: foo.p
`foo.p'의 종속성은 make가 오브젝트 파일 `.o' 파일에 대한 묵시적 규칙에 따라서 파스칼 소스 파일 `.p' 파일로부터 `foo.o'를 리메이크할 것이다라는 것을 반드시 의미하지 않는다. 예를 들어서 `foo.c'가 이미 존재하고 C 소스 파일로부터 오브젝트 파일을 만드는 묵시적 규칙이 대신 사용된다. 왜냐면 이것이 사전 정의된 묵시적 규칙들의 리스트에서 파스칼에 대한 규칙보다 먼저 나오기 때문이다 (see section 묵시적 규칙들의 카달로그(Catalogue of Implicit Rules)).
묵시적 규칙이 명령들이 없는 타겟에 대해서 사용되기를 원하지 않는다면 타겟에게, 하나의 세미콜론만 작성해서 빈 명령들을 줄 수 있다 (see section 빈 명령 사용하기(Using Empty Commands)).
묵시적 규칙들의 카달로그(Catalogue of Implicit Rules)
다음은 makefile이 이들을 명시적으로 오버라이드하거나 취소하지 않았다면 항상 사용이 가능한 사전에 정의된 묵시적 규칙들의 카달로그이다. 묵시적 규칙들을 취소하거나 오버라이드하는 정보에 대해서 See section 묵시적 규칙 취소시키기(Canceling Implicit Rules). `-r'이나 `--no-builtin-rules' 옵션은 모든 사전에 정의된 규칙들을 취소시킨다.
`-r' 옵션이 주어지지 않았다하더라도, 이들 규칙들 모두가 항상 정의되는 것은 아니다. 많은 사전에 정의된 규칙들은 make에서 접미사 규칙들로 구현된다. 그래서 이들은 접미사 리스트(suffix list)에 의존적으로 정의될 것이다 (특수한 타겟 .SUFFIXES의 종속물들의 리스트). 디폴트 접미사 리스트는 다음과 같다: .out, .a, .ln, .o, .c, .cc, .C, .p, .f, .F, .r, .y, .l, .s, .S, .mod, .sym, .def, .h, .info, .dvi, .tex, .texinfo, .texi, .txinfo, .w, .ch .web, .sh, .elc, .el. 종속물들이 이런 접미사들 중의 하나를 가지는 아래에서 기술된 묵시적 규칙들 모두는 실제로 접미사 규칙들이다. 접미사 리스트를 변경한다면 단지 효력 있는 사전에 정의된 접미사 규칙들만이 여러분이 지정한 리스트에 있는 접미사들 중의 하나나 둘의 이름을 가지는 것들이 될 것이다; 접미사들 중에서 이들 리스트에 있지 않는 규칙들은 사용 불가능이 된다. 접미사 규칙들에 대한 상세한 내용은 See section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules).
C 프로그램 컴파일(Compiling C programs)
`n.o' 는 `n.c' 로부터 `$(CC) -c $(CPPFLAGS) $(CFLAGS)' 형태의 명령에 의해서 자동으로 만들어진다.
C++ 프로그램 컴파일(Compiling C++ programs)
`n.o' 는 `n.cc' 나 `n.C' 로부터 `$(CXX) -c $(CPPFLAGS) $(CXXFLAGS)' 형태의 명령에 의해서 자동으로 만들어진다.
C++ 소스
파일들에 대해서 `.c' 대신에 `.cc' 접미사를 사용하기를 권한다.
파스칼 프로그램 컴파일(Compiling Pascal programs)
`n.o' 는 `n.p' 로부터 `$(PC) -c $(PFLAGS)' 라는 명령을 사용해서 자동으로 만들어진다.
포트란과 Ratfor 프로그램 컴파일(Compiling Fortran and Ratfor programs)
`n.o' 는 `n.r', `n.F' 또는 `n.f' 로부터 포트란 컴파일러를 실행해서 자동으로 만들어진다. 사용된 정확한 명령은 다음과 같다:
`.f'
`$(FC) -c $(FFLAGS)'.
`.F'
`$(FC) -c $(FFLAGS) $(CPPFLAGS)'.
`.r'
`$(FC) -c $(FFLAGS) $(RFLAGS)'.
포트란과 Ratfor 프로그램 사전처리(Preprocessing Fortran and Ratfor programs)
`n.f' 는 `n.r' 또는 file{n.F} 로부터 자동으로 만들어진다. 이 규칙은 Ratfor 또는 사전처리가능한 포트란 프로그램을 엄격한 포트란 프로그램으로 변환하는 사전처리기를 실행시킬 뿐이다. 사용되는 정확한 명령은 다음과 같다:
`.F'
`$(FC) -F $(CPPFLAGS) $(FFLAGS)'.
`.r'
`$(FC) -F $(FFLAGS) $(RFLAGS)'.
Modula-2 프로그램 컴파일(Compiling Modula-2 programs)
`n.sym' 는 `n.def' 로부터 `$(M2C) $(M2FLAGS) $(DEFFLAGS)' 라는 형태의 명령을 사용해서 만들어진다. `n.o'는 `n.mod';로부터 만들어진다. 그 형태는 다음과 같다: `$(M2C) $(M2FLAGS) $(MODFLAGS)'.
어셈블러 프로그램을 어셈블링하고 사전처리하기(Assembling and preprocessing assembler programs)
`n.o' 는 `n.s' 로부터 어셈블러 as 를 실행함으로써 자동으로 만들어진다. 정확한 명령은 `$(AS) $(ASFLAGS)'. `n.s' 는 C 선행처리기 cpp 를 실행함으로써 `n.S' 파일로부터 자동으로 만들어진다. 정확한 명령은 `$(CPP) $(CPPFLAGS)'.
단일 오브젝트 파일을 링크(Linking a single object file)
`n' 는 `n.o' 로부터 C 컴파일러를 경유해서 링커(보통 ld)를 실행함으로써 자동으로 만들어진다. 정확한 명령은 `$(CC) $(LDFLAGS) n.o $(LOADLIBES)'. 이 규칙은 단일 소스 파일을 가지는 단순한 프로그램에 대해서 정확한 것을 한다. 다수의 오브젝트 파일들이 있더라도(아마도 다양한 다른 소스 파일들로부터 온 것) 정확한 것을 행할 것이다. 이들중 하나는 실행 파일의 이름과 같은 이름을 가진다. 그래서,
x: y.o z.o
`x.c', `y.c' 그리고 `z.c' 모두가 존재할 때 다음을 실행할 것이다:
cc -c x.c -o x.o
cc -c y.c -o y.o
cc -c z.c -o z.o
cc x.o y.o z.o -o x
rm -f x.o
rm -f y.o
rm -f z.o
좀 더 복잡한 경우, 이름이 실행 파일로부터 유도되는 오브젝트 파일이 없을 때, 링크를 위해서 명시적 명령을 작성해야 한다. `.o' 오브젝트 파일들로 만들어지는 각 종류의 파일은 컴파일러(`$(CC)', `$(FC)', 또는 `$(PC)' 를 사용해서 자동으로 링크된다; C 컴파일러 `$(CC)'는 `-c' 옵션 없이 `.s' 파일들을 어셈블하는 데 사용된다. 이것은 `.o' 오브젝트 파일들을 중간 파일들로 사용함으로써 이루어진다. 그러나 이것은 한 스텝으로 컴파일하고 링크하는 데 더 빠르다. 이것이 어떻게 이루어지는가이다.
C 프로그램을 Yacc(Yacc for C programs)
`n.c' 는 `n.y'로 부터 `$(YACC) $(YFLAGS)' 라는 명려을 실행함으로써 자동으로 만들어진다.
C 프로그램을 Lex(Lex for C programs)
`n.c' 는 `n.l' 로부터 Lex 를 실행함으로써 자동으로 만들어진다. 실제 명령은 `$(LEX) $(LFLAGS)'.
Ratfor 프로그램을 Lex(Lex for Ratfor programs)
`n.r' 는 Lex를 실행하여 `n.l' 로부터 자동으로 만들어진다. 실제 명령은 `$(LEX) $(LFLAGS)'. 동일한 접미사 `.l'을 모든 Lex 파일들에 대해서 사용하는 관례는, 그들이 Ratfor 코드나 C 코드들 중에 어떤 것을 만들던지 상관없이, make가 특별한 경우에 이 두 언어들 중의 어떤 것을 사용중인지 자동으로 결정하는 것을 불가능하게 만든다. `.l' 파일로부터 오브젝트 파일을 다시 만들기 위해서 make가 호출되었다면 이것은 어떤 컴파일러를 사용할 것인가를 반드시 추측해내야 한다. C 컴파일러라고 추측해낼 수도 있을 것이다. 왜냐면 이것이 가장 일반적이기 때문이다. Ratfor를 사용하고 있다면 make가 이것을 알도록 `n.r'을 makefile안에 언급해야 한다. 또는 Ratfor를 C 파일들 없이, 배타적으로 사용하고 있다면 다음과 같이 해서 묵시적 규칙 접미사 리스트로부터 `.c'를 제거하라:
.SUFFIXES:
.SUFFIXES: .o .r .f .l ...
C, Yacc, 또는 Lex 프로그램으로부터 Lint 라이브러리 만들기(Making Lint Libraries from C, Yacc, or Lex programs)
`n.ln' 는 lint를 실행해서 `n.c' 로부터 만들어진다. 정확한 명령은 `$(LINT) $(LINTFLAGS) $(CPPFLAGS) -i'. `n.y' 나 `n.l' 로부터 만들어진 C 코드에 대해서 동일한 명령이 사용된다.
TeX 과 웹(TeX and Web)
`n.dvi' 는 `n.tex' 로부터 `$(TEX)' 명령에 의해서 만들어진다. `n.tex' 는 `n.web' 로부터 `$(WEAVE)' 로 만들어지거나, `n.w' 로부터 (그리고 `n.ch' 가 존재하거나 만들어질 수 있다면 이것으로부터) `$(CWEAVE)' 명령에 의해서 만들어진다. `n.p' 는 `n.web' 로 부터 `$(TANGLE)' 명령에 의해서 만들어지고 `n.c' 는 `n.w' 로부터(그리고 `n.ch' 이 존재하거나 만들어질 수 있다면 이것으로부터) `$(CTANGLE)' 명령에 의해서 만들어진다.
Texinfo 와 Info
`n.dvi' 는 `n.texinfo', `n.texi', 또는 `n.txinfo' 로부터 `$(TEXI2DVI) $(TEXI2DVI_FLAGS)' 명령을 사용해서 만들어진다. `n.info' 는 `n.texinfo', `n.texi', 또는 `n.txinfo' 로부터 `$(MAKEINFO) $(MAKEINFO_FLAGS)' 명령을 사용해서 만들어진다.
RCS
`n' 이라는 이름을 가진 임의의 파일은 `n,v' 또는 `RCS/n,v' 라는 이름을 가진 RCS 파일로부터, 필요하다면 추출된다. 사용되는 정확한 명령은 `$(CO) $(COFLAGS)' 이다. `n' 는 이것이 이미 존재하거나, 심지어 RCS 파일이 더 새로운 것이라 할 지라도, RCS 로부터 추출되지 않을 것이다. RCS 를 위한 규칙들은 제일 마지막(terminal) (see section 임의의 것과도 일치하는 패턴 규칙(Match-Anything Pattern Rules)) 이어서, RCS 파일들은 다른 소스들로부터 만들어질 수 없다; 그들은 실제로 반드시 존재해야 한다.
SCCS
`n' 는 `s.n' 또는 `SCCS/s.n' 라는 이름을 가진 SCCS 파일로부터, 필요하다면 추출도니다. 사용되는 정확한 명령은 `$(GET) $(GFLAGS)' 이다. SCCS 를 위한 규칙들은 제일 마지막(terminal) (see section 임의의 것과도 일치하는 패턴 규칙(Match-Anything Pattern Rules)) 이이서, SCCS 파일들은 다른 소스로부터 만들어질 수 없다; 그들은 반드시 실제로 존재해야 한다. SCCS 을 위해서, `n' 이란 파일이 `n.sh' 라는 것으로부터 복사되고 실행 가능이 된다(모두에 의해서). 이것은 SCCS 에 체크인되는 쉘 스크립트이다. RCS 는 파일의 실행 퍼미션을 보존하기 때문에 이 기능을 RCS 와 함께 사용할 필요가 없다. 우리는 SCCS 를 되도록이면 사용하지 않도록 권고하는 바이다. RCS 는 널리 더 좋은 것이라고 생각되어지고 있고 또한 공짜이다. 비슷한(또는 더 못한) 상용 소프트웨어 대힌 무료 소프트웨어를 선택함으로써 여러분은 자유 소프트웨어 운동을 지원하는 것이다.
보통 위의 있는 테이블에 나온 변수들만을 변경하고자 할 것이다. 이들은 다음 섹션에서 설명된다.
그러나 내장 묵시 규칙들에 있는 명령들이 실제로 COMPILE.c, LINK.p, 그리고 PREPROCESS.S 와 같은 변수들을 사용한다. 이들의 값은 위에 나열된 명령들을 담고 있다.
make 는, `.x' 소스 파일을 컴파일하는 규칙은 COMPILE.x 라는 변수를 사용한다는 관례를 사용한다. 비슷하게 `.x' 라는 파일로부터 실행 파일ㅇ르 만드는 규칙은 LINK.x 를 사용한다; `.x' 를 선행 처리하는 규칙은 PREPROCESS.x 를 사용한다.
오브젝트 파일을 생성하는 모든 규칙들은 OUTPUT_OPTION 변수를 사용한다. make 는 이 변수를 컴파일 때의 옵션에 따라서, `-o $@'를 담도록, 또는 빈 것이 되도록 정의한다. VPATH (see section 종속물을 위한 디렉토리 검색(Searching Directories for Dependencies) 를 사용할 때와 비슷하게, 다른 디렉토리에 소스가 있을 때, 결과가 정확한 파일로 가도록 하기 위해서 `-o' 옵션을 사용할 필요가 있다. 그러나, 어떤 시스템들에서 컴파일러들은 오브젝트 파일들에 대해서 `-o' 옵션을 받아들이지 않는다. 그런 시스템을 사용하고 있다면, VPATH를 사용한다면, 어떤 컴파일은 그들의 결과를 다른 위치에다 놓을 것이다. 이런 문제에 대한 가능한 해결법(workaround)은 OUTPUT_OPTION 에게 `; mv $*.o $@' 값을 주는 것이다.
묵시적 규칙에 의해 사용되는 변수(Variables Used by Implicit Rules)
내장 묵시적 규칙의 명령들은 어떤 사전정의된 변수들을 자유롭게 사용한다. 이런 변수들을 makefile 안에서, make에 대한 매개변수들로, 또는 환경에서, 묵시적 규칙들을 재정의하지 않고서 이들이 작동하는 방식을 바꾸기 위해, 변경할 수 있다.
예를 들어서 C 소스 파일을 컴파일하는 데 사용되는 명령은 실제로 `$(CC) -c $(CFLAGS) $(CPPFLAGS)' 이다. 사용된 변수들의 실제 값들은 `cc'와 아무것도 아니기 때문에 결국 `cc -c' 이 된다. `CC' 를 `ncc'로 재정의함으로써, `ncc' 가 묵시적 규칙에 의해서 수행되는 모든 C 컴파일에 대해서 사용되도록 할 수 있다. `CFLAGS' 를 `-g' 로 변경해서 `-g' 옵션을 각 컴파일에 전달할 수 있다. C 컴파일을 수행하는 모든 묵시적 규칙들은 `$(CC)' 를 사용하여 그 컴파일러의 프로그램 이름과 모든 것이 컴파일러에게 주어진 매개변수들 안에 `$(CFLAGS)' 를 포함한다.
묵시적 규칙들안에 사용된 변수들은 두가지 클래스들로 구분된다; 프로그램들의 이름인 것들(CC 와 같이)과, 프로그램에 대한 매개변수들을 담고 있는 것들(CFLAGS 와 같이). ("프로그램의 이름" 도 또한 어떤 명령 매개변수들을 가질 수 있지만 이것은 반드시 실제의 실행 프로그램 이름으로 시작해야 한다.) 하나 이상의 변수 값을 가진다면 그것들을 공백문자들로 구분하라.
다음은 내장 규칙들 안에서 프로그램들의 이름으로 사용되는 변수들을 모은 테이블이다:
AR
아카이브-관리 프로그램; 디폴트는 `ar'.
AS
어셈블리 수행 프로그램; 디폴트는 `as'.
CC
C 프로그램을 컴파일하는 프로그램; 디폴트는 `cc'.
CXX
C++ 프로그램들을 컴파일하는 프로그램; 디폴트는 `g++'.
CO
RCS 로부터 파일을 추출하는 프로그램; 디폴트는 `co'.
CPP
결과는 표준 출력으로 내는, C 선행처리기를 실행하는 프로그램; 디폴트는 samp{$(CC) -E}.
FC
포트란과 Ratfor 프로그램들을 컴파일하거나 선행처리하는 프로그램; 디폴트는 `f77'.
GET
SCCS 로부터 파일을 추출하는 프로그램; 디폴트는 `get'.
LEX
Lex 문법들을 C 프로그램들이나 Ratfor 프로그램들로 변환하는 데 사용되는 프로그램; 디폴트는 `lex'.
PC
파스칼 프로그램들을 컴파일하는 프로그램; 디폴트는 `pc'.
YACC
Yacc 문법들을 C 프로그램들로 변환하는 데 사용되는 프로그램; 디폴트는 `yacc'.
YACCR
Yacc 문법들을 Ratfor 프로그램들로 변환하는 데 사용되는 프로그램; 디폴트는 `yacc -r'.
MAKEINFO
Texinfo 소스 파일을 Info 파일로 변환하는 프로그램; 디폴트는 `makeinfo'.
TEX
TeX 소스로부터 TeX DVI 를 만드는 프로그램; 디폴트는 `tex'.
TEXI2DVI
Texinfo 소스로부터 TeX DVI 파일들을 만드는 프로그램; 디폴트는 `texi2dvi'.
WEAVE
Web 을 TeX 로 변환하는 프로그램; 디폴트는 `weave'.
CWEAVE
C Web 을 TeX 로 변환하는 프로그램; 디폴트는 `cweave'.
TANGLE
Web 을 파스칼로 변환하는 프로그램; 디폴트는 `tangle'.
CTANGLE
C Web 을 C 로 변환하는 프로그램; 디폴트는 `ctangle'.
RM
파일을 제거하는 명령; 디폴트 `rm -f'.
다음은 이것의 값들이 위에 있는 프로그램들에 대한 추가의 매개변수들이 되는 변수들을 모은 테이블이다. 이런 모든 것들에 대한 디폴트는 다른 언급이 없다면 빈 문자열이다.
ARFLAGS
아카이브-관리 프로그램에 주어지는 플래그; default `rv'.
ASFLAGS
어셈블러에 주어지는 여분의 플래그 (`.s' 나 `.S' 파일에 대해서 명시적으로 호출되었을 때).
CFLAGS
C 컴파일러에게 주어지는 여분의 플래그.
CXXFLAGS
C++ 컴파일러에게 주어지는 여분의 플래그.
COFLAGS
RCS co 프로그램에게 주어지는 여분의 플래그.
CPPFLAGS
C 선행처리기와 이것을 사용하는 프로그램(C 그리고 포트란 프로그램)에게 주어지는 여분의 플래그.
FFLAGS
포트란 컴파일러에게 주어지는 여분의 플래그.
GFLAGS
SCCS get 프로그램에 주어지는 여분의 플래그.
LDFLAGS
링커 `ld' 를 호출할 것으로 추정되는 컴파일러에게 주어지는 여분의 플래그.
LFLAGS
Lex 에게 주어지는 여분의 플래그.
PFLAGS
파스칼 컴파일러에게 주어지는 여분의 플래그.
RFLAGS
Ratfor 프로그램들에 대해서 포트란 컴파일러에게 주어지는 여분의 플래그.
YFLAGS
Yacc 에게 주어지는 여분에 플래그.
묵시적 규칙의 연쇄(Chains of Implicit Rules)
때때로 어떤 파일은 묵시적 규칙들을 순차적으로 적용해서 만들어질 수 있다. 예를 들어서 `n.o' 라는 파일은 맨먼저 Yacc 를 실행하고 그 다음 cc를 실행해서, `n.y'로부터 만들어질 수 있다. 이런 시퀀스는 연쇄(chain) 라고 불린다.
`n.c' 이 존재한다면, 또는 makefile 에서 언급되었다면, 어떤 특수한 검색도 필요하지 않다; make는 `n.c' 로부터 C 컴파일을 통해서 오브젝트 파일이 만들어질 수 있다는 것을 안다; 나중에 `n.c' 를 만드는 방법을 생각할 때, Yacc 를 실행하기 위한 규칙이 사용된다. 결국 두 `n.c' 과 `n.o' 이 갱신된다.
그러나 `n.c' 이 존재하지 않고 언급되지도 않았다하더라도, make는 그것이 `n.o' 과 `n.y' 사이에서 끓긴 고리라는 것을 안다. 이런 경우 `n.c' 는 중간 파일(intermediate file) 이라고 불린다. 일단 make가 중간 파일을 사용하기로 결정하였다면 이것은 마치 makefile안에서 언급된 것처럼, 그것을 생성하는 묵시적 규칙과 함께 데이터베이스에 넣어지게 된다.
중간 파일들은 모든 다른 파일들처럼 그들의 규칙을 사용해서 다시 만들어진다. 그러나 중간 파일들은 다음과 같은 두가지 방식으로 다르게 취급된다.
첫번째 다른점은, 중간 파일이 존재하지 않을 때 일어나는 것이다. 일반 팡리 b 가 존재하지 않고 make 가 b 에 종속적인 타겟을 생각한다면 이것은 항상 b를 생성한 다음 b로부터 그 타겟을 갱신한다. 그러나 b가 중간 파일이라면 make는 그대로 둘 수도 있다. 이것은 b 또는 궁극적인 타겟을, b의 어떤 종속물도 타겟보다 더 새로운 것이 아니거나 그 타겟을 갱신할 어떤 다른 이유가 없다면, 갱신하려고 하지 않는다.
두번째 다른점은, make가 어떤 다른 것을 갱신하기 위해서 b를 생성한다면, 이것이 더이상 필요없을 때 b를 지운다는 것이다. 그러므로 make 이전에 존재하지 않던 중간 파일은 make 이후에도 존재하지 않는다. make는 어떤 파일이 삭제되고 있는가를 보여주는 `rm -f' 명령을 인쇄함으로써 그 삭제 사실을 여러분에게 보고한다.
일반적으로 어떤 파일은 이것이 makefile에서 타겟이나 종속물로 언급된다면 중간 파일이 될 수 없다. 그러나 특수 타겟 .INTERMEDIATE 의 종속물 리스트에 넣어서 어떤 파일을 명시적으로 중간 파일로 지정할 수 있다. 이것은 그 파일이 어떤 다른 식으로 언급되었다 하더라도 효력을 발휘한다.
중간 파일의 자동 삭제를 그 파일을 이차(secondary) 파일로 지정함으로써 막을 수 있다. 이렇게 하기 위해서 이것을 특수 타겟 .SECONDARY 의 종속물 리스트에 넣으면 된다. 어떤 파일이 이차이라면 make는 그 파일이 사전에 존재하지 않는다는 이유 하나만으로 생성하지는 않을 것이다. 그러나 make 는 그 파일을 자동으로 지우지 않는다. 어떤 파일을 이차로 지정하는 것은 그것을 또한 중간 파일로 지정하는 것이다.
묵시적 규칙(`%.o'와 같은) 의 타겟 패턴을 특수 타겟 .PRECIOUS 의 종속물로 지정해서 타겟 패턴이 그 파일의 이름과 일치하는 묵시적 규칙들에 의해서 만들어진 중간 파일들을 보존할 수 있다. section make를 인터럽트 또는 죽이기(Interrupting or Killing make) 참조.
하나의 연쇄가 두개보다 많은 묵시적 규칙들을 가지고 있을 수 있다. 예를 들어서 RCS, Yacc, 그리고 cc 를 실행해서 `RCS/foo.y,v' 로부터 `foo' 를 만드는 것이 가능하다. 여기서 두 파일 `foo.y' 과 `foo.c' 이 마지막에 지워지는 중간 파일드이다.
어떤 묵시적 규칙도 연쇄에서 두번 이상 나타날 수 없다. 이것은 make 가 링커를 두번 실행해서 `foo.o.o' 로부터 `foo'를 만드는 것과 같은 이상한 일을 생각하지 않을 것이라는 것을 의미한다. 이런 제약은 묵시적 규칙 연쇄를 찾으면서 무한 루프에 빠지는 것을 막는 또다른 장점을 가진다.
그렇치 않다면 규칙 연쇄들에 의해서 처리될, 어떤 경우들을 최적화하는 몇가지 특수 묵시적 규칙들이 있다. 예를 들어서 `foo'를 `foo.c' 로부터 만드는 것은 file{foo.o} 를 중간 파일로 사용해서, 분리된 연쇄 규칙들로 컴파일되고 링크됨으로써 처리될 수 있을 것이다. 그러나 이런 경우 실제로 일어나는 것은 단일 cc 명령으로 컴파일과 링크를 같이 수행하는 특수한 규칙 하나이다. 이런 최적화된 규칙은 규칙들의 순서에서 좀 더 먼저 오기 때문에 스텝-바이-스텝 연쇄보다 더 우선 적용된다.
패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules)
여러분은 패턴 규칙(pattern rule) 을 작성해서 묵시적 규칙을 정의한다. 패턴 규칙은 일반 규칙과, 이것의 타겟이 `%' (그들중 정확히 한개) 문자를 가지고 있다는 점을 제외하고는, 동일하다. 이 타겟은 파일 이름들과 일치하는 패턴으로 생각된다; `%'는 빈 서브문자열이 아니라면 무엇과도 일치할 수 있는 것이다. 반면에 다른 문자들은 그들 자신들과만 일치한다. 그들이 이름들이 타겟 이름과 관련된 방법을 보여주기 위해서 종속물들은 `%'를 사용한다.
그래서 `%.o : %.c' 라는 패턴 규칙은 파일 `stem.c' 로부터 `stem.o' 라는 파일을 만드는 방법을 말한다.
`%' 을 패턴 규칙들에서 사용한 확장이, makefile이 읽힐 때 발생하는 다른 변수나 함수 확장 후에 발생되는 것에 주의하자. See section 변수 사용 방법(How to Use Variables), 그리고 section 텍스트 변환을 위한 함수(Functions for Transforming Text).
패턴 규칙에 대한 소개(Introduction to Pattern Rules)
패턴 규칙은 타겟 안에 `%' 문자 (정확히 그들 중 하나) 를 담고 있다; 그렇지 않으면 이것은 일반 규칙과 완전히 똑같이 보일 것이다. 타겟은 파일이름들과 일치하는 패턴이다; `%' 는 임의의 빈 것이 아닌 부분문자열과 일치하고 다른 문자들은 그들 자신들과만 일치한다.
예를 들어서, 패턴으로써 `%.c' 는 `.c'로 끝나는 임의의 파일 이름과 일치한다. 패턴으로써 `s.%.c' 는 `s.' 로 시작하고 `.c' 로 끝나며 적어도 다섯개의 문자 이상으로 이루어진 임의의 파일 이름과 일치한다. (`%' 와 일치하는 문자가 적어도 하나 있어야 한다.) `%' 와 일치하는 부분문자열은 줄기(stem) 이라고 불린다.
패턴 규칙의 종속물 안에 있는 `%' 는 타겟에서 `%' 와 일치한 것과 동일한 줄기(stem) 을 나타낸다. 패턴 규칙이 적용되기 위해서 그것의 타겟 패턴은 그 파일 이름과 반드시 일치해야 하며 그것의 종속물 패턴은 반드시 존재하거나 만들어질 수 있는 파일들의 이름을 갖고 있어야 한다. 이런 파일들은 그 타겟의 종속물들이 된다.
그래서 다음과 같은 형태의 규칙은
%.o : %.c ; command...
`n.o' 를, `n.c' 파일이 존재하거나 만들어질 수 있다면 종속물 `n.c' 파일을 가지고 만드는 방법을 지정한다.
`%' 를 사용하지 않는 종속물들이 있을 수 있다; 그런 종속물은 이런 패턴 규칙에 의해서 만들어진 모든 파일들에 첨부된다. 이런 변하지 않는 종속물들은 종종 유용하다.
패턴 규칙은 `%' 를 담고 있는 종속물들을 반드시 가질 필요가 없다. 또는 실제 아무런 종속물을 안가져도 된다. 그런 규칙은 효율적으로 일반 와일드 카드가 된다. 이것은 타겟 패턴과 일치하는 임의의 파일을 만드는 방법을 제공한다. See section 최후의 디폴트 규칙 정의(Defining Last-Resort Default Rules).
패턴 규칙들은 한가지 타겟 이상 가질 수 있다. 일반 규칙들과는 다르게 이런 것은 동일한 종속물들과 명령들을 가진 다른 많은 규칙들과 다르게 작동한다. 어떤 패턴 규칙이 다수의 타겟들을 가진다면, make 는 그 규칙의 명령들이 그 타겟들 모두를 만드는 책임이 있다고 이해한다. 명들들은 타겟들 전부를 만들기 위해서 단 한번만 실행된다. 타겟과 일치하는 패턴 규칙을 검색할 때, 규칙을 필요로 하는 타겟과 일치하는 것(규칙)과 다른 규칙의 타겟 패턴들이 흔히 있다: make 는 현재 문제가 되는 파일에 명령들과 종속물들을 주는 것에 대해서만 신경을 쓴다. 그러나 이 파일의 명령들이 실행중일 때 다른 타겟들은 그들 자신이 갱신된 것처럼 마킹된다.
패턴 규칙들이 makefile 에서 나타나는 순서는 아주 중요하다. 왜냐면 이것이 바로 그들이 생각되어지는 순서이기 때문이다. 동일하게 적용가능한 규칙들 중에서 단지 맨처음 찾아진 것만이 사용된다. 여러분이 작성한 규칙들은 내장된 규칙들보다 더 우선한다. 그러나 종속물들이 실제로 존재하거나 언급된 규칙은 항상, 다른 묵시적 규칙들에 의해서 반드시 만들어져야 하는 종속물들을 가진 규칙보다 우선한다는 것을 주의하자.
패턴 규칙 예제(Pattern Rule Examples)
다음은 make에 의해서 실제로 미리 정의된 패턴 규칙들의 몇가지 예제들이다. 먼저 `.c' 파일들을 `.o' 로 컴파일하는 규칙은:
%.o : %.c
$(CC) -c $(CFLAGS) $(CPPFLAGS) $< -o $@
이것은 `x.c' 으로부터 `x.o' 파일을 만들수 있는 규칙을 정의한다. 명령은 규칙이 적용될 때마다 타겟 파일 이름들과 소스 파일 이름들을 대입하기 위한 자동 변수들 `$@' 과 `$<' 를 사용하고 있다. (see section 자동 변수들(Automatic Variables)).
다음은 두번째 내장 규칙이다:
% :: RCS/%,v
$(CO) $(COFLAGS) $<
이것은 서브디렉토리 `RCS' 에서 대응하는 파일 `x,v' 로부터 `x' 파일을 만들 수 있는 규칙을 정의한다. 타겟이 `%' 이기 때문에 이 규칙은, 적절한 종속 파일이 존재한다면, 임의의 파일 무엇에나 용될 것이다. 더블 콜론 은 이 규칙을 terminal 로 만든다. terminal 이란 그것의 종속물이 중간 파일이 아니어야 한다는 것을 의미한다. (see section 임의의 것과도 일치하는 패턴 규칙(Match-Anything Pattern Rules)).
다음 패턴 규칙은 다음과 같은 두 타겟들을 가진다:
%.tab.c %.tab.h: %.y
bison -d $<
이것은 make 에게 `bison -d x.y' 명령이 `x.tab.c' 과 `x.tab.h' 둘다 make 하라고 말하는 것이다. `foo' 가 `parse.tab.o' 과 `scan.o' 에 종속적이고 `scan.o' 파일이 `parse.tab.h' 에 종속적이면, `parse.y' 파일이 변경될 때, `bison -d parse.y' 이 단 ㅏㄴ번 실행될 것이고 두 파일 `parse.tab.o', `scan.o' 의 종속성들이 만족될 것이다. (아마 `parse.tab.o' 파일이 `parse.tab.c' 로부터 그리고 `scan.o' 파일이 `scan.c' 로부터 재컴파일 될 것이고 `foo' 파일은 `parse.tab.o', `scan.o', 그리고 다른 종속물들로 링크될 것이며 이것은 그리고 나서 해피하게 실행될 것이다.)
자동 변수들(Automatic Variables)
`.c' 파일을 `.o' 파일로 컴파일하는 패턴 규칙을 작성하고 있다고 가정해보자: 그렇다면 어떻게 `cc' 명령이 적절한 소스 파일에 대해서 작동하도록 작성할 것인가? 그 소스 파일 이름을 명령에 쓸 수 없다. 왜냐면 그 이름은 묵시적 규칙이 적용되는 때마다 다를 것이기 때문이다.
해야할 일은 make의 특수 기능, 자동 변수(automatic variables) 를 사용하는 것이다. 이런 변수들은 실행되는 각 규칙에 대해서 매번 새롭게, 규칙의 종속물들과 타겟에 기반해서 다시 계산되는 값을 가진다. 이 예에서 `$@' 를 오브젝트 파일 이름에 淪漫?그리고 `$<' 를 소스 파일 이름에 대해서 사용하면 될 것이다.
다음은 자동 변수들을 모아본 테이블이다:
$@
규칙에 있는 타겟의 파일 이름. 타겟이 아카이브 멤버이면 `$@'는 아카이브 파일의 이름이다. 여러개의 타겟들(see section 패턴 규칙에 대한 소개(Introduction to Pattern Rules))을 가지고 있는 패턴 규칙에서 `$@'는 규칙의 명령이 실행되도록 만든 타겟이면 무엇이든 이 타겟의 이름이 된다.
$%
타겟이 아카이브 멤버(See section 아카이브 파일을 갱신하기 위해서 make 사용하기(Using make to Update Archive Files))일때, 타겟 멤버 이름. 예를 들어서 타겟이 `foo.a(bar.o)'이면 `$%'는 `bar.o'이고 `$@'는 `foo.a'이다. 타겟이 아카이브 멤버가 아니면 `$%'는 빈 것이 된다.
$<
첫번째 종속물의 이름. 타겟이 묵시적 규칙으로부터 그의 명령들을 얻었다면 이것은 묵시적 규칙에 의해서 추가된 첫번째 종속물이 될 것이다 (see section 묵시적 규칙(Using Implicit Rules)).
$?
타겟보다 더 새로운 모든 종속물들의 이름들. 이들 사이에는 스페이스들이 들어간다. 아카이브 멤버들인 종속물들에 대해서 이름이 있는 멤버만이 사용된다 (see section 아카이브 파일을 갱신하기 위해서 make 사용하기(Using make to Update Archive Files)).
$^
모든 종속물들의 이름. 이들 사이에는 스페이스들이 들어간다. 아카이브 멤버인 종속물들에 대해서 이름있는(지정된?) 멤버만이 사용된다 (see section 아카이브 파일을 갱신하기 위해서 make 사용하기(Using make to Update Archive Files)). 타겟은 이것이 의존하는 다른 각 파일들에 대해서 각 파일이 종속물 리스트에서 몇번이나 나왔는가에 상관없이, 딱 한번만 사용한다. 그래서 어떤 타겟을 위해서 한번 이상 종속물을 사용한다면 $^ 의 값은 그 이름을 딱 한번 담고 있는 형태가 된다.
$+
이것은 `$^' 와 비슷하다. 그러나 종속물들이 makefile 에서 리스트된 순서와 나타난 대로 중복되었다고 해도 한번 이상 리스트된다. 이것은 특별한 순서로 라이브러리 파일 이름들을 반복하는 것이 의미가 있는 링크 명령들 안에서 주로 유용하다.
$*
묵시적 규칙이 일치하는 (see section 패턴 비교 방법(How Patterns Match)) 대상 줄기(stem). 타겟이 `dir/a.foo.b' 이고 타겟 패턴이 `a.%.b' 이라면 줄기는 `dir/foo' 이다. 줄기는 관련된 파일들의 이름을 만들때 유용하다. 정적 패턴 규칙에서 줄기는 타겟 패턴에서 `%' 과 일치한, 파일 이름의 일부분을 말한다. 명시적 규칙에서는 줄기가 없다; 그래서 `$*' 는 그런식으로 결정될 수 없다. 대신에 타겟 이름이 인식된 접미사로 끝난다면 (see section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules)), `$*' 는 타겟 이름 빼기 접미사로 설정된다. 예를 들어서, 타겟 이름이 `foo.c' 이라면, `$*' 는 `foo' 로 설정된다, 왜냐면 `.c' 가 접미사이기 때문이다. GNU make 는 다른 make 구현물과의 호환성을 위해서만 이런 괴기스런 일을 한다. 일반적으로 묵시적 규칙들이나 정적 패턴 규칙들을 제외하고는 `$*' 를 쓰지 않도록 해야 할 것이다. 명시적 규칙 안의 타겟 이름이 인식된 접미사로 끝나지 않는다면 `$*' 는 그 규칙에 대해서 빈 문자열로 설정된다.
`$?' 는 변경한 종속물들에 대해서만 작업을 하고자 할 때, 명시적 규칙들 안에서도 유용하다. 예를 들어서 `lib' 라는 이름의 아카이브가 몇개의 오브젝트 파일들의 복사물들을 담고 있다고 가정해보자. 다음 규칙은 변경된 오브젝트 파일들만을 아카이브에다 넣을 것이다:
lib: foo.o bar.o lose.o win.o
ar r lib $?
위에서 리스트된 변수들(자동 변수들)중에서, 네개는 단일 파일 이름들인 값들을 가지고 두개는 파일 이름들의 리스트들인 값들을 가진다. 이런 여섯개 변수들은 파일의 디렉토리 이름이나 디렉토리 내의 파일 이름과 같은 값을 추출하는 변종들을 가진다. 변종 변수들의 이름들은 각각 `D' 나 `F' 를 붙여서 이루어진다. 이런 변종들은 GNU make 에서 반쯤 구닥다리이다. 왜냐면 dir 과 notdir 함수들이 동일한 효과를 얻는데 사용될 수 있기 때문이다 (see section 파일 이름들을 위한 함수(Functions for File Names)). 그러나 `F' 변종들은 dir 함수의 결과에서는 항상 나타나는 마지막 슬래쉬를 모두 제거한다는 사실에 주목하자. 다음은 변종들의 테이블이다:
`$(@D)'
The directory part of the file name of the target, with the trailing slash removed. If the value of `$@' is `dir/foo.o' then `$(@D)' is `dir'. This value is `.' if `$@' does not contain a slash.
`$(@F)'
타겟의 파일 이름에서 디렉토리 파트에 들어 있는 파일 부분을 가리킨다. `$@' 의 값이 `dir/foo.o' 이라면 `$(@F)' 는 `foo.o' 이다. `$(@F)' 는 `$(notdir $@)' 과 동일하다.
`$(*D)'
`$(*F)'
줄기의 디렉토리 부분과 디렉토리 파트 안에 들어 있는 파일 부분을 가리킨다; 이 예제의 경우라면 `dir' 과 `foo' 가 될 것이다.
`$(%D)'
`$(%F)'
타겟 아카이브 멤버 이름 중에서 디렉토리 파트와 디렉토리 파트 안에 들어 있는 파일 부분을 가리킨다. 이것은 `archive(member)' 형태의 아카이브 멤버 타겟들에 대해서만 의미가 있고 member 가 디렉토리 이름을 갖고 있을 때만 유용하다. (See section 타겟으로써 아카이브 멤버(Archive Members as Targets0.)
`$(<D)'
`$(<F)'
첫번째 종속물의 디렉토리 파트와 디렉토리 파트 안에 들어 있는 파일 부분을 가리킨다.
`$(^D)'
`$(^F)'
모든 종속물들의 디렉토리 부분들과 디렉토리에 들어 있는 파일 부분들을 가리킨다.
`$(?D)'
`$(?F)'
타겟보다 더 새로운 모든 종속물들의 디렉토리 부분들과 디렉토리 내 파일들 부분을 가리킨다.
이런 자동 변수들에 대해서 얘기할 때 특별한 스타일의 관례를 사용한募?것에 주목하자; objects 와 CFLAGS 와 같은 일반 변수들에 대해서 작성할 때 "변수 <" 가 아니라 "`$<'의 값" 라고 쓴다. 이런 관례가 이런 특별한 경우에 좀 더 자연스럽게 보인다고 생각한다. 이것이 아주 깊은 중요성을 가진다고 추측하지 말자; `$<' 는 `$(CFLAGS)' 가 CFLAGS라는 이름의 변수를 참조하는 것처럼, < 라는 변수를 참조하는 것이다. `$<' 자리에 `$(<)' 라는 변수를 쓸수도 있다.
패턴 비교 방법(How Patterns Match)
타겟 패턴은 둘 중에 또는 둘다 빈 것일 수 있는, 접두사와 접미사 사이에 하나의 `%' 를 가진 것이다. 어떤 파일 이름이 중복없이, 접두사로 시작하고 접미어로 끝나면 패턴이 일치하는 것이다. 접두사와 접미사 사이의 텍스트는 줄기(stem) 이라고 불린다. 그래서 패턴 `%.o' 가 `test.o' 와 일치하면 줄기는 `test' 인 것이다. 패턴 규칙 종속물들은 `%' 문자에 줄기들을 대입해서 만들어진 실제 파일 이름들이다. 그래서 동일한 예제에서 종속물들 중의 하나가 `%.c' 로 작성되면 이것은 `test.c' 로 확장된다.
타겟 패턴이 슬래쉬를 갖지 않으면(그리고 보통 이것은 그렇지 않다), 파일 이름에서 디렉토리 이름들은 그 파일 이름에서, 타겟 접두사와 접미사와 비교되기전에, 제거된다. 파일 이름을 타겟 패턴과 비교한 후 디렉토리 이름들은, 이들 마지막에 있는 슬래쉬와 함께, 패턴 규칙의 종속물 패턴들과 그 파일 이름으로부터 만들어지는 종속물 파일에 더해진다. 디렉토리들은 사용할 묵시적 규칙을 찾을 목적으로만 무시된다. 그러나 그 규칙의 적용에서는 무시되지 않는다. 그래서 `e%t' 는 `src/eat' 과 일치하는 것이고 여기서 `src/a' 이 줄기이다. 종속물들이 파일 이름들이 되면 줄기로부터 디렉토리들이 그 앞에 덧붙여진다. 이때 줄기의 나머지가 `%' 에 대입된다. 종속물 패턴 `c%r' 를 가지고 줄기 `src/a' 는 파일 이름 `src/car' 를 제공한다.
임의의 것과도 일치하는 패턴 규칙(Match-Anything Pattern Rules)
패턴 규칙의 타겟이 단지 `%' 이라면 이것은 파일 이름이 무엇이든 이것과 일치하는 것이다. 우리는 이런 규칙을 임의의 것과도 일치하는(match-anything) 규칙이라고 부른다. 이들은 아주 유용하지만 make 가 그들을 생각하는 시간이 많이 든다. 왜냐면 이것은 타겟으로나 종속물로써 리스트된 각 파일 이름들에 대해서 모든 그런 규칙을 생각해야 하기 때문이다.
makefile 이 `foo.c' 를 언급했다고 하자. 이 타겟에 대해서 make 는 오브젝트 파일 `foo.c.o' 를 링크함으로써, 또는 `foo.c.c' 로부터 한번에 C 컴파일하고-링크함으로써, 또는 `foo.c.p' 로부터 파스칼 컴파일하고-링크함으로써, 그리고 기타 등등 많은 다른 가능성들을에 의해서 `foo.c' 를 만들려고 생각해야만 할 것이다.
이런 가능성들이, `foo.c' 이 C 소스 파일이고 실행 파일이 아니기 때문에, 다소 괴상망칙하다는 것을 우리는 안다. make 가 이런 가능성들을 생각하지 않는다면, `foo.c.o' 과 `foo.c.p' 과 같은 파일들이 존재하지 않을것이기 때문에 그런 가능성들을 궁극적으로 거부할 것이다. 그러나 이런 가능성들은 너무 많기 때문에 그것들을 생각해야 한다면 make 는 아주 느리게 작동할 것이다.
속도를 더 높이기 위해서 make 가 임의의것과도 일치하는 규칙들을 생각할 때 다양한 제약을 둔다. 적용될 수 있는 제약은 두개 있다. 임의의것과도 일치하는 규칙을 정의할 때마다, 그런 규칙에 대해서 하나 또는 다른 하나를 반드시 선택해야만 한다.
한가지 선택은 임의의것과도 일치하는 규칙을 더블 콜론으로 정의함으로써 terminal 로 마킹하는 것이다. 규칙이 terminal 이면 이것은, 그것의 종속물들이 실제로 존재하지 않는 한 적용되지 않는다. 다른 묵시적 규칙들로 만들어질 수 있는 종속물들은 좋은 것이 아니다. 다른 말로 하면 terminal 규칙을 넘어서 더이상의 연쇄 작용이 일어나지 않는다.
예를 들어서 RCS 와 SCCS 파일들로부터 소스들을 추출하는 내장된 묵시적 규칙들은 terminal 이다; 결과적으로 파일 `foo.c,v' 이 존재하지 않는다면 make 는 `foo.c,v.o' 나 `RCS/SCCS/s.foo.c,v' 로부터 중간 파일로써 그것을 마들려고 생각조차 하지 않을 것이다. RCS 와 SCCS 파일들은 일반적으로 최종 소스 파일들이다. 이들은 다른 파일들로부터 다시 만들어지면 안된다; 그러므로 make는 그것들을 다시 만드는 방법들을 찾지 않음으로써 시간을 절약할 수 있다.
임의의것과 일치하는 규칙을 terminal 로 마킹하지 않으면, 이것은 비-terminal. 비-terminal 임의의것과 일치하는 규칙은 특정한 데이터 타입을 가리키는 파일 이름에 적용될 수 없다. 어떤 파일 이름은, 비-임의의것과 일치하는 묵시적 규칙 타겟이 그것과 일치할 경우, 특정 데이터 타입을 가리킨다.
예를 들어서 `foo.c' 는 패턴 규칙 `%.c : %.y' (Yacc 를 실행하는 규칙) 에 대한 타겟과 일치한다. 이 규칙이 실제로 적용가능한가 아닌가에 (파일 `foo.y' 이 존재할때만 발생한다) 대해서 생각할 필요 없이, 그것이 타겟이 일치한다는 사실로써 파일 `foo.c' 에 대한 비-terminal 임의의것과도 일치하는 규칙들 중의 아무거나를 생각하는 것을 막기에는 충분하다. 그래서 make는 `foo.c' 를 `foo.c.o', `foo.c.c', `foo.c.p', 등으로부터 실행 파일로써 만들어볼려는 시도를 생각조차 않는다.
비-terminal 임의의것과 일치하는 규칙들이 특정한 데이터 타입들(실행 파일과 같은)을 담고 있는 파일들과을 만드는 데 사용된다는 것과, 인식된 접미사를 가지는 파일 이름들이 어떤 다른 특정한 데이터 타입(C 소스 파일과 같은)을 가리킨다는 것이 이런 제약의 동기이다.
특수한 내장된 더미 패턴 규칙들은 특정 파일 이름들을 인식해서 비-terminal 임의의것과 일치하는 규칙들이 생각되지 않도록 하기 위해서만 제공된다. 이런 더미 규칙들은 종속물들과 명령들을 가지지 않고 모든 다른 목적들에 대해서 무시된다. 예를 들어서 다음과 같은 내장된 묵시적 규칙은
%.p :
`foo.p' 과 같은 파스칼 소스 파일들이 특정한 타겟 패턴과 일치하므로 `foo.p.o' 나 `foo.p.c' 를 찾느라고 시간을 허비하지 못하도록 하기 위해서 존재한다.
`%.p' 를 위한 것과 같은 더미 패턴 규칙들은 접미사 규칙들에서의 사용을 위해서 유효하게 나열된 모든 접미사들에 대해서 만들어진다 (see section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules)).
묵시적 규칙 취소시키기(Canceling Implicit Rules)
내장 묵시적 규칙(또는 사용자가 정의한 것)을 동일한 타겟과 종속물들을 가지지만 명령들이 다른 새로운 패턴 규칙을 정의함으로써 오버라이드할 수 있다. 새로운 규칙이 정의될 때 내장 규칙이 대체된다. 새로운 규칙이 차지하는 묵시적 규칙들 시퀀스에서의 위치는 그 새로운 규칙을 작성한 위치에 의해서 결정된다.
내장 묵시적 규칙과 동일한 타겟과 종속물들을 가지지만 명령들은 없는 패턴 규칙을 정의함으로써 저 내장 묵시적 규칙을 취소할 수 있다. 예를 들어서 다음은 어셈블러를 실행하는 규칙을 취소할 것이다:
%.o : %.s
최후의 디폴트 규칙 정의(Defining Last-Resort Default Rules)
종속물들을 하나도 갖지 않는 제일-마지막(terminal) 임의의것과도 일치하는 패턴 규칙을 작성함으로써, 마지막(last-resort) 묵시적 규칙을 정의할 수 있다 (see section 임의의 것과도 일치하는 패턴 규칙(Match-Anything Pattern Rules)). 이것은 다른 패턴 규칙과 비슷하다; 이것은 임의의 타겟과도 일치할 것이다는 것이 이것이 특별한 유일한 것이다. 그래서 그런 규칙의 명령들은, 자신의 명령들을 가지지 않는 모든 타겟들과 종속물들에 대해서 그리고 다른 묵시적 규칙이 적용되지 않는 것들에 대해서 사용된다.
예를 들어서 makefile 을 테스트할 때 소스 파일들이 실제 데이터를 가지고 있는 것인가 신경쓰지 않고, 대신 그들이 존재하는가 안하는가만 신경쓸 수도 있다. 그렇다면 다음과 같이 할 수도 있다:
%::
touch $@
이것은 (종속물로써) 필요한 모든 소스 파일들이 자동으로 생성되도록 한다.
이것 대신 전혀 규칙들이 없는, 심지어 명령들을 지정하지 않는 규칙의, 타겟들에 대해서 사용되는 명령들을 정의할 수 있다. 이렇게 하기 위해서 .DEFAULT 타겟에 대한 규칙을 작성하면 된다. 그런 규칙의 명령들은 명시된 규칙의 타겟들로 나타나지 않는, 어떤 묵시적 규칙도 적용되지 않는, 종속물들에 대해서 사용된다. 일반적으로 작성하지 않으면 .DEFAULT 은 없다.
다음과 같이 .DEFAULT 를 명령이나 종속물들이 없이 사용한다면:
.DEFAULT:
.DEFAULT 에 대해서 이전에 정의된 명령들이 삭제된다. 그러면 make 는 .DEFAULT 를 전혀 정의하지 않은 것처럼 작동할 것이다.
어떤 타겟이 임의의것과도 일치하는 패턴이나 .DEFAULT 으로부터 명령들을 얻기를 원하지 않지만, 또한 어떤 명령도 그런 타겟에 대해서 실행되는 것을 원하지 않는다면, 이것에게 빈 명령들을 줄 수 있다 (see section 빈 명령 사용하기(Using Empty Commands)).
마지미가 규칙을 사용해서 다른 makefile 의 일부를 오버라이드할 수 있다. See section 다른 Makefile의 일부를 오버라이딩(Overriding Part of Another Makefile).
구닥다리 접미사 규칙(Old-Fashioned Suffix Rules)
접미사 규칙(Suffix rules) 이란 make 에 대해서 묵시적 규칙들을 정의하는 오래된-스타일의 방법이다. 접미사 규칙들은 패턴 규칙들이 좀 더 일반적이고 좀 더 명료하기 때문에 사장되었다. 오래된 makefile 들과의 호환성을 위해서 GNU make 는 이것을 지원한다. 그들은 다음 두가지 종류가 있다: 더블-접미사(double-suffix) 와 단일-접미사(single-suffix).
더블-접미사 규칙은 두개의 접미사들로 정의된다: 타겟 접미사와 소스 접미사. 이것은 파일의 이름이 타겟 접미사로 끝나는 어떤 파일과도 일치한다. 대응하는 묵시적 종속물은 타겟 접미사를 소스 접미사로 바꿔서 만들어진다. 타겟과 소스 접미사들이 `.o' 와 `.c' 인 두-접미사 규칙 은 패턴 규칙 `%.o : %.c' 와 동일하다.
단일-접미사 규칙은 단일 접미사로 정의된다. 이것은 소스 접미사이다. 단일-접미사 규칙은 임의의 파일들과 일치하고 대응하는 묵시적 종속물 이름은 소스 접미사를 덧붙여서 만들어진다. 소스 접미삭 `.c' 인 단일-접시사 규칙은 패턴 규칙 `% : %.c' 와 동일하다.
접미사 규칙 정의들은 각 규칙의 타겟과, 정의된 (알려진) 접미사 리스트와 비교해서 인식된다. make 가 타겟이 알려진 접미사인 규칙을 보면 이 규칙은 단일-접미사 규칙으로 생각된다. make 가 타겟이 두개의 알려진 접미사들이 서로 붙은 형태인 규칙을 보면 이 규칙은 더블-접미사 규칙으로 취급된다.
예를 들어서 `.c' 와 `.o' 는 알려진 접미사 디폴트 리스트에 둘 다 있는 것이다. 그러므로 타겟이 `.c.o' 인 규칙을 정의하면 make 는 이것을 소스 접미사는 `.c' 이고 타겟 접미사는 `.o' 인 더블-접미사로 생각한다. 다음은 C 소스 파일을 컴파일하기 위한 규칙을 정의하는 오래된-스타일의 방법이다:
.c.o:
$(CC) -c $(CFLAGS) $(CPPFLAGS) -o $@ $<
접미사 규칙들은 그들 자신의 종속물을 전혀 가질수 없다. 그들이 있다면 그들은 접미사 규칙들로 생각되어지는 것이 아니라 이상 이름들을 가진 일반 파일들로 생각된다. 그래서 다음 규칙은:
.c.o: foo.h
$(CC) -c $(CFLAGS) $(CPPFLAGS) -o $@ $<
`.c.o' 를 종속 파일 `foo.h' 로부터 만드는 방법을 말하는 것이 되버리고, 전혀 다음과 같은 패턴 규칙이 아니게 되버린다:
%.o: %.c foo.h
$(CC) -c $(CFLAGS) $(CPPFLAGS) -o $@ $<
이것은 `.c' 파일들로부터 `.o' 파일들을 만드는 방법과 `foo.h' 에 의존하는 이 패턴 규칙을 사용해서 모든 `.o' 파일들을 만드는 방법을 말하는 것이다.
어떤 명령도 없는 접미사 규칙들도 또한 의미가 없다. 그들은 명령들을 가지지 않는 패턴 규칙들이 그러는 것처럼, 이전 규칙들을 지우지 않는다 (see section 묵시적 규칙 취소시키기(Canceling Implicit Rules)). 그들은 데이터베이스에 타겟으로 단순히 접미사나 합쳐친 한쌍의 접미사들을 넣는다.
알려진 접미사들은 단순하게 특수한 타겟 .SUFFIXES 의 종속물들의 이름이다. 사용자 자신의 접미사들을, 다음과 같이 더 많은 종속물들을 더하는 .SUFFIXES 규칙을 작성함으로써, 추가할 수 있다:
.SUFFIXES: .hack .win
이것은 `.hack' 과 `.win' 을 접미사 리스트 마지막에 더한다.
그것들에다 더하는 것 대신에 알려진 디폴트 접미사들을 제거하고자 한다면 종속물들이 전혀 없는 .SUFFIXES 를 작성하면 된다. 특수한 섭리에 의해서 이것은 .SUFFIXES의 모든 존재하는 종속물들을 제거한다. 그리고 난후 사용자가 원하는 접미사들을 더하기 위해서 다른 규칙을 작성할 수 있다. 예를 들어서,
.SUFFIXES: # Delete the default suffixes
.SUFFIXES: .c .o .h # Define our suffix list
`-r' 또는 `--no-builtin-rules' 플래그는 디폴트 접미사 리스트를 빈 것으로 만든다.
변수 SUFFIXES 는 make 가 임의의 makefile 들을 읽기 전에, 접미사 디폴트 리스트들이 정의된다. 특수 타겟 .SUFFIXES 에 대한 규칙으로 접미사들 리스트를 변경할 수 있지만 그것은 이 변수는 바꿀 수 없다.
묵시적 규칙 검색 알고리즘(Implicit Rule Search Algorithm)
다음은 make 가 어떤 타겟 t 에 대해서 묵시적 규칙을 검색하는데 사용하는 과정이다. 이 과정은 명령들이 없는 각 더블-콜론 규칙에 대해서, 명령이 없는 일반 규칙들의 각 타겟에 대해서, 그리고 어떤 규칙에도 타겟이 아닌 각 종속물에 대해서, 수행된다. 이것은 또한, 규칙들의 연쇄를 찾으면서 묵시적 규칙들로부터 오는 종속물들에 대해서, 재귀적으로 수행된다.
접미사 규칙들은 이 알고리즘에서 언급되지 않는다. 왜냐면 접미사 규칙들은 makefile 이 일단 읽히면 동일한 패턴 규칙들로 변환되기 때문이다.
`archive(member)' 형태의 아카이브 멤버 타겟에 대해서 다음 알고리즘이 두번 실행된다. 첫번째는 전체 타겟 이름 t 를 사용하고 두번째는 첫번째가 어떤 규칙도 찾지 못한다면 t 타겟으로써 `(member)' 를 사용한다.
1. t 를 디렉토리 부분(d 라고 부르자)과 그리고 나머지(n 이라고 부르자)로 분할한다. 예를 들어서 t 가 `src/foo.o' 이라면 d 는 `src/' 이고 n 은 `foo.o' 이다.
2. 모든 패턴 규칙들 리스트가, 타겟이 t 나 n 과 일치하는 규칙이 되도록 만든다. 타겟 패턴이 슬래쉬를 가지면 이것은 t 와 비교된다; 그렇지 않으면 n 과 비교된다.
3. 이 리스트에 있는 임의의 규칙이 임의의것과도 일치하는 규칙이 아니라면 모든 비-terminal 임의의것과도 일치하는 규칙들을 이 리스트에서 제거한다.
4. 리스트에서 명령들이 없는 모든 규칙들을 제거한다.
5. 리스트에 있는 각 패턴 규칙에 대해서:
1) 줄기 s 를 찾는다. 이것은 타겟 패턴에서 `%' 와 일치하는 t 나 n 의 빈 것이 아닌 부분이다.
2) s 를 `%' 에 대해서 대입함으로써 종속물들 이름을 계산한다; 타겟 패턴이 슬래쉬를 가지지 않는다면 d 를 각 종속물 이름 앞에다 덧붙인다.
3) 모든 종속물들이 존재하거나 존재해야 하는지 검사한다. (어떤 파일 이름이 makefile 에서 타겟으로써 또는 명시적인 종속물로써 언급되었다면 우리는 그것이 반드시 존재해야 하는 것으로 말한다.) 모든 종속물들이 존재하거나 존재해야 한다면, 또는 종속물들이 전혀 없다면, 이 규칙이 적용된다.
6. 어떤 패턴 규칙도 지금까지 찾지 못했다면 더 어렵게 시도한다. 이 리스트에 있는 각 패턴 규칙에 대해서:
1) 규칙이 terminal 이라면 이것을 무시하고 다음 규칙으로 간다.
2) 이전과 같이 종속물들 이름을 계산한다.
3) 모든 종속물들이 존재하거나 존재해야 하는지 검사한다.
4) 존재하지 않는 각 종속물에 대해서 다음 알고리즘을 재귀적으로 실행해서, 종속물이 묵시적 규칙에 의해서 찾아질 수 있는가 없는가를 본다.
5) 모든 종속물들이 존재하거나, 존재해야 하거나, 묵시적 규칙들에 의해서 만들어질 수 있다면, 이 규칙이 적용된다.
7. 어떤 묵시적 규칙도 적용되지 않는다면 .DEFAULT 에 대한 규칙이, 존재한다면, 적용된다. 이런 경우 t 에게 .DEFAULT가 가지는 동일한 명령들을 준다. 그렇지 않다면 t 에 대한 명령들은 없는 것이 된다.
일단 적용할 규칙이 찾아지면, t 또는 n 과 일치하는 것과 다른 그 규칙의 각 타겟 패턴에 대해서, 그 패턴에 있는 `%' 는 s 로 교체되고 결과 파일 이름은, 타겟 파일 t를 다시 만들기 위해서 명령들이 실행될 때까지, 저장된다. 이런 명령들이 실행된 후 이들 저장된 파일들 각각은 데이터베이스로 들어가고 갱신된 것으로 그리고 그 파일 t과 같은 갱신 상태를 가지는 것으로 마킹된다.
패턴 규칙의 명령들이 t 에 대해서 실행될 때 자동변수들이 타겟과 종속물들에 대응하여 서정된다. See section 자동 변수들(Automatic Variables).
아카이브 파일을 갱신하기 위해서 make 사용하기(Using make to Update Archive Files)
아카이브 파일(Archive files) 이란 members 라고 불리는 서브 파일들을 담고 있는 파일들이다; 이들은 프로그램 ar 에 의해서 관리되고 그들의 주요 사용은 링크를 위한 서브루틴 라이브러리이다.
타겟으로써 아카이브 멤버(Archive Members as Targets)
아카이브 파일의 개별 멤버는 make 에서 타겟이나 종속물로써 사용될 수 있다. archive 의 member 라는 이름의 멤버를 다음과 같이 지정한다:
archive(member)
이런 구조는 타겟과 종속물들에서만 가능하고 명령들에서는 불가능하다. 명령들 안에서 사용할 대부분의 프로그램들은 이런 문법을 지원하지 않고 아카이브 멤버들에 대해서 직접 액션을 취할 수 없다. 단지 ar 과 아카이브들에 대해서 작동하도록 특별히 고안된 다른 프로그램들이 그렇게 할 수 있다. 그러므로 아카이브 멤버 타겟을 갱신하는 유효한 명령들은 반드시 ar 을 사용해야 한다. 예를 들어서 다음 규칙은 파일 `hack.o'을 복사해서 `foolib' 아카이브 내 `hack.o' 멤버를 생성하도록 말하는 것이다:
foolib(hack.o) : hack.o
ar cr foolib hack.o
사실 거의 모든 아카이브 멤버 타겟들이 이런 방식으로 갱신되고 이것을 사용자 대신 해주는 묵시적 규칙이 하나 있다. 노트(Note): 그 아카이브 파일이 이미 존재하지 않는다면 ar 에게 `c' 플래그를 주어야 한다.
동일한 아카이브의 몇가지 멤버들을 지정하려면 괄호들 안에 모든 멤버 이름들을 쓸 수 있다. 예를 들어서:
foolib(hack.o kludge.o)
이것은 다음과 동일하다:
foolib(hack.o) foolib(kludge.o)
아카이브 멤버 참조에서 쉘-스타일 와일드카드들을 사용할수도 잇다. See section 파일 이름에 와일드카드 사용(Using Wildcard Characters in File Names). 예를 들어서 `foolib(*.o)' 는 그것의 이름이 `.o' 로 끝나는 `foolib' 아카이브의 모든 존재하는 멤버들로 확장된다; 아마 `foolib(hack.o) foolib(kludge.o)'.
아카이브 멤버 타겟들에 대한 묵시적 규칙(Implicit Rule for Archive Member Targets)
`o(m)' 와 같이 보이는 타겟은 아카이브 파일 o 의 m 이라는 이름의 멤버를 나타낸다는 것을 상기하자.
make 는 그런 타겟에 대한 묵시적 규칙을 찾는다. 특수 기능으로써 이것은 `(m)' 과 일치하는 묵시적 규칙들을 생각한다. 실제 타겟 `a(m)' 과 일치하는 것들과 함께.
이것은 타겟이 `(%)' 인 특수 규칙이 비교되도록 유발한다. 이 규칙은 파일 m 를 그 아카이브로 복사함으로써 타겟 `a(m)' 를 업데이트한다. 예를 들어서 이것은 파일 `bar.o' 를, `bar.o' 라는 이름의 멤버 로써 아카이브 파일 `foo.a' 안으로 복사함으로써, 아카이브 멤버 타겟 `foo.a(bar.o)' 를 갱신할 것이다.
이 규칙이 다른 것들과 연쇄된 것이면 그 결과는 아주 강력한 것이다. 그래서 `bar.c' 라는 파일이 있을 때, `make "foo.a(bar.o)"' (여기서 따옴표들은 `(' 과 `)' 가 쉘에 의해서 특수하게 해석되는 것을 막기 위해서 필요하다) 는, makefile 이 없다고 하더라도, 다음 명령들이 실행되도록 하기에 충분한 것이다:
cc -c bar.c -o bar.o
ar r foo.a bar.o
rm -f bar.o
여기서 make 는 중간 파일로써 `bar.o' 를 생각한다. See section 묵시적 규칙의 연쇄(Chains of Implicit Rules).
이것과 같은 묵시적 규칙들은 자동 변수 `$%' 를 사용해서 작성된다. See section 자동 변수들(Automatic Variables).
아카이브에 있는 아카이브 멤버 이름은 디렉토리 이름을 담을 수 없다. 그러나 makefile 안에서 이것이 그런것처럼 하는 것은 유용할 수 있다. `foo.a(dir/file.o)' 이라는 아카이브 멤버 타겟을 작성한다면 make 는 다음과 같은 명령으로 자동 갱신할 것이다:
ar r foo.a dir/file.o
이것은 `dir/file.o' 파일을 `file.o' 이라는 이름의 멤버로 복사하는 효과를 가진다. 그런 사용에 연결에서 %D 과 %F 는 유용할 수 있다.
아카이브 심벌 디렉토리 갱신(Updating Archive Symbol Directories)
라이브러리로써 사용되는 아카이브 파일은 보통 다른 모든 멤버들에 의해서 정의된 외부 심벌 이름들의 디렉토리(3)를 갖고 있는 `__.SYMDEF' 라는 이름의 특수 멤버를 담고 있다. 다른 멤버들을 갱신한 후 `__.SYMDEF' 를 갱신해서 이것이 다른 멤버들을 적절하게 요약할 수 있도록 해야 한다. 이것은 ranlib 프로그램을 실행함으로써 행해진다:
ranlib archivefile
일반적으로 이 명령을 그 아카이브 파일을 위한 규칙에 넣을 것이다. 그리고 그 아카이브의 모든 멤버들들이 그 규칙의 종속물들이 되도록 할 것이다. 예를 들어서,
libfoo.a: libfoo.a(x.o) libfoo.a(y.o) ...
ranlib libfoo.a
이것의 효과는 `x.o', `y.o' 등의 아카이브 멤버들을 갱신하는 것이고 ranlib 를 실행해서 `__.SYMDEF' 라는 심벌 디렉토리 멤버를 갱신하는 것이다. 멤버들을 갱신하는 규칙들은 여기에 나와있지 않다; 대부분의 사람들은, 이전 섹션에서 설명된 바와 같이, 그것들을 생략하고 아카이브로 파일들을 복사하는 묵시적 규칙을 사용할 수 있다.
이것은 `__.SYMDEF' 멤버를 자동으로 갱신하는, GNU ar 프로그램을 사용할 때, 반드시 필요한 것은 아니다.
아카이브를 사용할 때의 위험(Dangers When Using Archives)
병렬 처리(-j 옵션; see section 패러럴 실행(Parallel Execution))와 아카이브를 사용할 때 주의해야 한다. 이것은 아주 중요하다. 여러 ar 명령들이 동일한 아카이브 파일에 대해서 동시에 실행되면 그들은 각기 서로 다른 것들을 모를것이며 그래서 그 파일을 오염시킬것이다.
아마 make 의 미래 버전이 동일한 아카이브 파일에 대해서 작동하는 모든 명령들을 시리얼라이즈(일렬로 세우기)함으로써 이런 문제를 회피하는 메카니즘을 제공할 것이다. 그러나 현재의 경우 다른 방식으로 이런 문제를 회피하도록 makefile 들을 작성하거나 -j 를 사용해서는 안된다.
아카이브 파일의 접미사 규칙(Suffix Rules for Archive Files)
아카이브 파일들을 관리하는 특수한 종류의 접미사 규칙을 작성할 수 있다. 접미사 규칙들에 대한 완전한 설명을 보려면 See section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules). GNU make 에서는 아카이브 접미사 규칙들이 사장되었다. 왜냐면 아카이브를 위한 패턴 규칙이 좀 더 일반적인 메카니즘 (see section 아카이브 멤버 타겟들에 대한 묵시적 규칙(Implicit Rule for Archive Member Targets)) 이기 때문이다. 그러나 그들은 다른 make 들과의 호환성 때문에 기능은 남아 있다.
아카이브를 위한 접미사 규칙을 작성하기 위해서 타겟 접미사 `.a' (아카이브 파일들에 대한 일반적인 접미사) 를 사용하는 접미사 규칙을 작성하면 된다. 예를 들어서 다음은 C 소스 파일들로부터 라이브러리 아카이브를 갱신하는 오래된-스타일의 접미사 규칙이다:
.c.a:
$(CC) $(CFLAGS) $(CPPFLAGS) -c $< -o $*.o
$(AR) r $@ $*.o
$(RM) $*.o
이것은 다음과 같은 패턴 규칙과 비슷하게 작동한다:
(%.o): %.c
$(CC) $(CFLAGS) $(CPPFLAGS) -c $< -o $*.o
$(AR) r $@ $*.o
$(RM) $*.o
사실 이것은 make 가 `.o' 를 타겟 접미사로써 가지는 접미사 규칙을 하나 보았을 때 행하는 것 그자체이다. 임의의 더블-접미사 규칙 `.x.a' 은 타겟 패턴 `(%.o)' 과 종속물 패턴 `%.x' 를 가지는 패턴 규칙으로 변환된다.
어떤 다른 종류의 파일에 대한 접미사로써 `.a' 를 사용하려고 할런지 모르기 때문에, make 는 아카이브 접미사 규칙들을 일반적인 방법으로(see section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules)), 패턴 규칙들로 변환한다. 그래서 더블-접미사 규칙 `.x.a' 는 두가지 패턴 규칙들: `(%.o): %.x' 과 `%.a: %.x' 를 생성한다.
GNU make의 기능
다음은 다른 버전의 비교를 위해서, 그리고 감사를 드리기 위해서, GNU make의 기능 요약이다. 우리는 4.2 BSD 시스템들에 있는 make의 기능들을 베이스라인으로 생각한다. 포터블한 makefile을 작성하는 것에 관심이 있다면 여러분은 section 비호환성과 빠진 기능들(Incompatibilities and Missing Features)에서 또는 여기에서 나오지 않은 make의 기능들만 사용해야 한다.
많은 기능들이 make System V 버전으로부터 온 것이다.
● VPATH 변수와 이것의 특수한 의미. See section 종속물을 위한 디렉토리 검색(Searching Directories for Dependencies). 이 기능은 System V make 에 존재하지만 문서화되지 않았다. 이것은 4.3 BSD make 에 문서화되었다 (이것은 System V 의 VPATH 기능을 흉내낸 것이라고 말하고 있다).
● makefile 들을 포함하기 See section 다른 makefile 삽입(Including Other Makefiles). 단일 디렉티브로 다수의 파일들이 포함되는 것을 허용하는 것이 GNU 의 확장 기능이다.
● 환경으로부터 변수들이 읽히고 환경을 통해서 변수들이 통신된다. See section 환경으로부터의 변수들(Variables from the Environment).
● 재귀적인 make 호출들에 대해서, MAKEFLAGS 변수를 통해 옵션들이 전달된다. See section 서브-make에 대한 통신 옵션(Communicating Options to a Sub-make).
● 원자 변수 $% 가 아카이브 참조에서 멤버 이름으로 설정된다. See section 자동 변수들(Automatic Variables).
● 자동 변수들 $@, $*, $<, $%, 그리고 $? 가 $(@F) 와 $(@D) 과 같은 대응되는 형을 가진다. 이것을 명백한 확장으로써 $^ 로 일반화하였다. See section 자동 변수들(Automatic Variables).
● 대입 변수 참조. See section 변수 참조의 기본(Basics of Variable References).
● 명령행 옵션들 `-b' 와 `-m'. 이들은 받아들여지지만 무시된다. System V make 에서 이 옵션들은 실제로 무언가를 하는 것들이다.
● `-n', `-q' 또는 `-t' 옵션이 지정되었다 하더라도, MAKE 변수를 통해서 make 를 실행하는 재귀적 명령들의 실행. See section make의 재귀적 사용(Recursive Use of make).
● 접미사 규칙에서 `.a' 접미사에 대한 지원. See section 아카이브 파일의 접미사 규칙(Suffix Rules for Archive Files). 이 기능은 GNU make 에서 사장된 것이다. 왜냐면 규칙 연쇄 (see section 묵시적 규칙의 연쇄(Chains of Implicit Rules)) 의 일반적인 기능이 한 아카이브에 있는 멤버들을 설치하기 위해서 한 패턴 규칙이 충분하도록 허용하기 때문이다 (see section 아카이브 멤버 타겟들에 대한 묵시적 규칙(Implicit Rule for Archive Member Targets)).
● 명령에서 라인들과 역슬래쉬-개행 조합의 정렬은, 그 명령들이 인쇄될 때 유지되어 그들이 makefile 안에서 보이는 것처럼 보이게 한다. 초기 공백들을 제거하는 것은 제외.
다음 기능들은 다른 버전들의 make 로부터 도입된 것이다. 어떤 경우 어떤 버전들이 다른 것에 영감을 준 것인지 정확하지 않다.
● `%' 를 사용한 패턴 규칙들. 이것은 여러 make 의 버전들에서 구현된 바 있다. 이것을 맨처음 고안한 사람이 누구인지 모른다. 그러나 이것은 다소 널리 퍼진 것이다. See section 패턴 규칙을 정의하고 재정하기(Defining and Redefining Pattern Rules).
● 규칙 연쇄 및 묵시적 중간 파일들. 이것은 스튜 펠만(Stu Feldman)에 의해서 그의 AT&T Eighth Edition Research Unix 를 위한 make 버전에서 구현되었던 것이다. 그리고 나중에 AT&T 벨 연구소의 앤드류 흄(Andrew Hume)에 의해서 그의 mk 프로그램에서 (여기서 그는 이것을 "전이 닫힘(transitive closure)" 라고 불렀다) 구현되었던 것이다. 실제 이들 중 어떤 것으로부터 이것을 얻었는지 모르거나 이것이 동일한 시점에 우리도 그것을 가지고 있었다고 생각한다(thought it up ourselves at the same time). See section 묵시적 규칙의 연쇄(Chains of Implicit Rules).
● 현재 타겟의 모든 종속물들의 리스트를 담고 있는 자동 변수 $^. 우리는 이것을 발명하지 않았다. 그러나 누가 발명한 것인지도 모른다. See section 자동 변수들(Automatic Variables). 자동 변수 $+ 는 $^ 의 단순한 확장이다.
● "what if" 플래그 (GNU make 에서는 `-W') 는 (우리가 아는 한) 앤드류 흄의 mk 에서 고안되었다. See section 명령 실행 대신에...(Instead of Executing the Commands).
● 몇가지 일들을 동시에 하는 개념(병렬 처리)가 많은 make 과 비슷한 프로그램들의 구현에 존재한다. 비록 이것이 System V나 BSD 구현들에서는 없지만. See section 명령 실행(Command Execution).
● 패턴 대입을 사용한 변조된 변수 참조들이 SunOS 4 로부터 채용되었다. See section 변수 참조의 기본(Basics of Variable References). 이 기능은 GNU make 에서 patsubst 함수에 의해서, 대안 문법이 SunOS 4 와의 호환성을 위해서 구현되기전에, 제공되었다. 누가 누구에게 고무했는지 전혀 분명하지 않다. 왜냐면 GNU make 는 SunOS 4 가 릴리즈되기 전에 patsubst 를 갖고 있었기 때문이다.
● 명령 라인들 (see section 명령 실행 대신에...(Instead of Executing the Commands)) 앞에 붙은 `+' 의 특별한 의미는 IEEE Standard 1003.2-1992 (POSIX.2) 로 부터 위임된 것이다.
● 어떤 변수의 값에 덧붙이는 `+=' 문법은 SunOS 4 make 로부터 온 것이다. See section 변수에 텍스트를 덧붙이기(Appending More Text to Variables).
● 단일 아카이브 파일 안으로 다수의 멤버들 리스트를 넣는 `archive(mem1 mem2...)' 문법은 SunOS 4 make 로부터 온 것이다. See section 타겟으로써 아카이브 멤버(Archive Members as Targets0.
● 존재하지 않는 파일에 대해서 에러 없이 makefile 들을 포함하는 -include 지시어는 SunOS 4 make 로부터 온 것이다. (그러나 SunOS 4 make 는 단일 -include 지시어로 다수의 makefile 들이 지정되는 것을 허용하지 않는다.) 동일한 기능이 SGI make 에 있는 sinclude 라는 이름의 것으로 있다. 아마 다른 make 들도 있을 것이다.
다음 기능들은 GNU make에서 새로 발명된 것들이다:
● 버전과 저작권 정보를 출력하기 위해서 `-v' 나 `--version' 을 사용한다.
● make 의 옵션들을 요약한 `-h' 나 `--help' 옵션을 사용한다.
● 단순하게-확장되는 변수들. See section 변수의 두 취향(The Two Flavors of Variables).
● 명령-라인 변수 할당들을 재귀적 make 호출에게 변수 MAKE 를 통해서 전달한다. See section make의 재귀적 사용(Recursive Use of make).
● 디렉토리를 변경하기 위해서 `-C' 나 `--directory' 명령 옵션을 사용한다. See section 옵션들의 요약(Summary of Options).
● define 로 verbatim 변수 정의를 만든다. See section 축어 변수 정의(Defining Variables Verbatim).
● 특수 타겟 .PHONY 를 가지고 포니 타겟들을 선언한다. AT&T Bell Labs 의 앤드류 흄(Andrew Hume)이 mk 프로그램안에 다른 문법으로 비슷한 기능을 구현하였다. 이것은 동시 발견(parallel discovery) 의 경우인 것처럼 부인다. See section 가짜 목적물(Phony Targets).
● 함수들을 호출해서 텍스트를 조작. See section 텍스트 변환을 위한 함수(Functions for Transforming Text).
● 파일의 변조-시간(modification-time)이 오래된 것처럼 하는 `-o' 또는 `--old-file' 옵션을 사용. See section 어떤 파일들을 재컴파일하는 것을 피하기(Avoiding Recompilation of Some Files).
● 조건 실행. 이 기능은 많은 make 버전들에서 여러번 구현되어왔다; 이것은 C 선행처리기와 비슷한 매크로 언어들의 기능으로부터 유도된 자연스러운 확장으로 보이며 혁신적인 개념은 아니다. See section Makefile의 조건 부분(Conditional Parts of Makefiles).
● 포함된 makefile들에 대한 검색 경로를 지정. See section 다른 makefile 삽입(Including Other Makefiles).
● 환경 변수로 읽을 여분의 makefile들을 지정. See section MAKEFILES 변수(The Variable MAKEFILES).
● 파일 이름들로부터 앞에 있는 `./' 시퀀스들을 제거해서 `./file' 과 `file' 이 동일한 파일로 생각된다.
● `-lname' 형태로 쓰여진 라이브러리 종속물들에 대한 특수 검색 방법을 사용한다. See section 링크 라이브러리 디렉토리 검색(Directory Search for Link Libraries).
● 접미사 규칙들에 대한 접미사들이 (see section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules)) 임의의 문자들을 담고 있도록 허용한다. 다른 make 버전들에 있어서 그들은 반드시 `.' 로 시작하고 `/' 문자들을 담고 있어서는 안된다.
● MAKELEVEL 변수를 사용해서 make 재귀의 현재 깊이를 추적한다. See section make의 재귀적 사용(Recursive Use of make).
● 변수 MAKECMDGOALS 로, 명령행에서 주어진 임의의 목표(goal)들을 제공한다. See section goal을 지정하는 매개변수(Arguments to Specify the Goals).
● 정적 패턴 규칙을 지정. See section 정적 패턴 규칙(Static Pattern Rules).
● 선택적인 vpath 검색을 제공. See section 종속물을 위한 디렉토리 검색(Searching Directories for Dependencies).
● 계산된 변수 참조들을 제공. See section 변수 참조의 기본(Basics of Variable References).
● makefile 을 갱신하는 기능. See section Makefiles가 다시 만들어지는 과정(How Makefiles Are Remade). System V make 는 이런 기능에 대해서 아주 제한된 형태를 가지고 있다. 이것에서는 make 가 makefile들에 대해서 SCCS 파일들을 체크아웃할 것이다.
● 다양한 새로운 내장 묵시적 규칙들. See section 묵시적 규칙들의 카달로그(Catalogue of Implicit Rules).
● 내장 변수 `MAKE_VERSION' 는 make 의 버전 넘버를 제공한다.
비호환성과 빠진 기능들(Incompatibilities and Missing Features)
다른 다양한 시스템들에 있는 make 프로그램들은 GNU make 가 구현해놓지 않는 몇가지 기능들을 지원한다. POSIX.2 표준 (IEEE Standard 1003.2-1992) 에 의하면 이런 기능들 어떤 것도 make 는 필요하지 않다.
● `file((entry))' 형태의 타겟은 아카이브 파일 file 의 멤버를 표시한다. 이 멤버는 이름에 의해서가 아니라 링커 심벌 entry 을 정의한 오브젝트 파일이 되는 것에 의해서 선택된다. 이 기능은 GNU make 에 의해서 구현되지 않았다. 왜냐면 지식을 아카이브 심벌 테이블의 내부 포멧으로 make 에 넣는 것은 모듈성을 해치기 때문이다. See section 아카이브 심벌 디렉토리 갱신(Updating Archive Symbol Directories).
● `~' 라는 문자로 끝나는 접미사들(접미사 규칙들에서 사용되는)은 System V make 에서 특별한 의미를 가진다; 그들은 `~' 를 가지지 않는 파일에 대응하는 SCCS 파일을 가리킨다. 예를 들어서 접미사 규칙 `.c~.o' 는 `n.o' 라는 파일을 SCCS 파일 `s.n.c' 로부터 만들것이다. 완전한 적용범위를 위해서 그런 접미사 규칙들의 전체가 필요하다. See section 구닥다리 접미사 규칙(Old-Fashioned Suffix Rules). GNU make 에서 이런 경우들의 모든 것들은 SCCS 로부터 추출하는 두가지 패턴 규칙들에 의해서, 규칙 연쇄의 일반 기능들과 연동해서, 처리된다. See section 묵시적 규칙의 연쇄(Chains of Implicit Rules).
● System V make 에서 문자열 `$$@' 는, 다수의 타겟들을 가지는 규칙의 종속물들에서, 이것은 처리중인 특정 타겟을 나타낸다는, 이상한 의미를 가진다. 이것은 `$$' 가 항상 일반 `$' 를 나타내야 하므로 GNU make 에서 정의되지 않았다. 이런 기능을 정적 패턴 규칙들을 사용해서 얻는 것이 가능하다. (see section 정적 패턴 규칙(Static Pattern Rules)). System V make 의 다음과 같은 규칙은:
$(targets): $$@.o lib.a
다음과 같은 GNU make 정적 패턴 규칙으로 교체될 수 있다:
$(targets): %: %.o lib.a
● System V 와 4.3 BSD make 에서 VPATH 검색 (see section 종속물을 위한 디렉토리 검색(Searching Directories for Dependencies)) 으로 찾아진 파일들은 명령 문자열들 안에서 변경된 이름을 갖는다. 우리는 자동 변수들을 사용해서 이 기능을 사장시키는 것이 좀 더 명확하다고 느낀다.
● 어떤 유닉스 make들에서는, 어떤 규칙의 종속물들 안에서 나타난 자동 변수 $*는 그 규칙의 타겟의 전체 이름으로 확장되는 아주 이상한 "기능"을 가진다. 우리는 유닉스 make 개발자들이 이렇게 하기 위해서 마음속으로 무슨 생각을 하는지 알 수 없다; 이것은 $* 의 일반 정의와 완전히 다르다.
● 어떤 유닉스 make들에서는, 묵시적 규칙 검색 (see section 묵시적 규칙(Using Implicit Rules)) 이 명령들이 없는 것뿐만이 아니고 모든 타겟들에 대해서 수행된다. 이것은 다음과 같은 것을 할 수 있다는 것을 의미한다:
foo.o:
cc -c foo.c
그리고 유닉스 make 는 `foo.o' 이 `foo.c' 에 종속한다는 것을 알 것이다. 이런 사용이 잘못되었다고 우리는 생각한다. make 의 종속물 속성은 잘-정의되었으며(적어도 GNU make에 대해서), 그 모델에 맞지 않는 것을 수행한다.
● GNU make 는 EFL 프로그램들을 컴파일하거나 사전처리하는 내장 묵시적 규칙들을 포함하지 않는다. 우리는 EFL 을 사용하는 사람이 있다는 것을 듣게 된다면 기꺼이 이것들을 더할 것이다.
● SVR4 make 에서 나타난 것인데, 접미사 규칙은 명령들이 없이 지정될 수 있고 빈 명령들을 가진 것처럼 취급된다 (see section 빈 명령 사용하기(Using Empty Commands)). 예를 들어서:
.c.a:
내장 `.c.a' 접미사 규칙을 오버라이드할 것이다. 우리는 명령들이 없는 규칙이, 항상 그 타겟에 대해서 종속물 리스트를 단순하게 추가하는 것이 더 쉽다고 느낀다. 위의 예제는 GNU make 의 원하는 행동을 얻기 위해서 다음과 같이 쉽게 재작성될 수 있다:
.c.a: ;
● make 의 몇가지 변종 버전들은, `-k' (see section 프로그램의 컴파일 테스트(Testing the Compilation of a Program) 의 경우를 제외하고는, 쉘을 `-e' 플래그로 호출한다. `-e' 플래그는 쉘에게 임의의 프로그램이 0이 아닌 상태값을 리턴하면 즉시 종료하라고 말하는 것이다. 우리는 각 쉘 명령행을 홀로 있도록 쓰고 이런 특별한 취급을 요구하지 않도록 하는 것이 훨씬 더 쉽다고 느낀다.
makefile 관례(Makefile Conventions)
이 장은 GNU 프로그램들에 대한 makefile을 작성하는 관례를 설명한다.
makefile에 대한 일반 관례(General Conventions for Makefiles)
모든 makefile 은 다음과 같은 라인을 가져야 한다:
SHELL = /bin/sh
SHELL 변수가 환경으로부터 승게될수도 있는 시스템들에서 문제들을 피하기 위해서. (이것은 GNU make 의 문제가 절대로 아니다.)
다른 make 프로그램들은 비호환 접미사 리스트들과 묵시적 규칙들을 가지고 이것은 때때로 혼란과 잘못된 행동을 일으킨다. 그래서 특정한 makefile에서 필요로하는 접미사들로만 이루어진 접미사 리스트를 다음과 같이 설정하는 것은 좋은 생각이다:
.SUFFIXES:
.SUFFIXES: .c .o
첫번째 라인은 접미사 리스트를 청소한다. 두번째 라인은 이 makefile 에서 묵시적 규칙들에 종속적인 모든 접미사들을 도입한 것이다.
`.' 가 명령 실행을 위한 경로에 있을 것이라고 가정하지 말자. make 동안에 사용자의 팩키지 중에서 어떤 프로그램을 실행하고자 할 때, 그 프로그램이 make 의 일부이라면 이것이 `./' 를, 또는 그 파일이 소스 코드의 변경되지 않은 부분일 경우라면 `$(srcdir)/' 를 사용하는 것을 확인하기 바란다. 이런 접두어들 중의 하나가 없다면 현재 검색 경로가 사용된다.
`./' (빌드 디렉토리(build directory)) 와 `$(srcdir)/' (소스 디렉토리(source directory)) 사이의 차이는 사용자들이 `configure' 에 대해서 `--srcdir' 옵션을 사용하여 분리된 디렉토리 안에서 빌드할 수 있기 때문에 중요하다. 다음과 같은 형태의 규칙은:
foo.1 : foo.man sedscript
sed -e sedscript foo.man > foo.1
빌드 디렉토리가 소스 디렉토리가 아닐 때 실패할 것이다. 왜냐면 `foo.man' 와 `sedscript' 는 소스 디렉토리에 있기 때문이다.
GNU make 를 사용할 때 `VPATH' 에 의존해서 소스 파일을 찾는 것은 단일 종속 파일이 있는 경우에 작동할 것이다. 왜냐면 make 자동 변수 `$<' 는 소스 파일이 어디에 있던간에 그 소스 파일을 표현할 것이기 때문이다. (make 의 많은 버전들이 `$<' 를 묵시적 규칙들 안에서만 설정한다.) 다음과 같은 makefile 타겟은
foo.o : bar.c
$(CC) -I. -I$(srcdir) $(CFLAGS) -c bar.c -o foo.o
이것 대신에 다음과 같이 작성되어야 할 것이다.
foo.o : bar.c
$(CC) -I. -I$(srcdir) $(CFLAGS) -c $< -o $@
`VPATH' 가 제대로 작동하도록 하기 위해서 말이다. 타겟이 다수의 종속물들을 가진다면, 명시적인 `$(srcdir)' 를 사용하는 것이 규칙이 제대로 작동하도록 하는 가장 쉬운 방법이다. 예를 들어서 위에서 `foo.1' 를 위한 타겟은 다음과 같이 쓰는 것이 가장 좋은 것이다:
foo.1 : foo.man sedscript
sed -e $(srcdir)/sedscript $(srcdir)/foo.man > $@
GNU 배포판들은 보통 소스 파일들이 아닌 몇가지 파일들을 가지고 있다---예를 들어서, Info 파일, 그리고 Autoconf, Automake, Bison 또는 Flex 로부터 발생된 결과. 이런 파일들이 일반적으로 소스 디렉토리에 나타나기 때문에 그들은 항상 빌드 디렉토리가 아니라 소스 디렉토리에 있어야 한다. 그래서 이들을 갱신하는 Makefile 규칙들은 갱신 파일들을 소스 디렉토리에 넣어야 한다.
그러나 어떤 파일이 배포판에 없다면 Makefile 은 그것을 소스 디렉토리에 넣으면 안된다. 왜냐면 어떤 프로그램을 보통의 환경에서 빌드하는 것은 소스 디렉토리를 어떤 식으로든 변경해서는 안되기 때문이다.
타겟을 빌드하고 설치하는 것이, 적어도(그리고 모든 그들의 서브타겟들이) 병렬 make로도 정확하게 작동하게 만들려고 노력하자.
makefile 의 유틸리티(Utilities in Makefiles)
makefile 명령들(그리고 configure 와 같은 쉘 스크립트들)을 작성할 때 csh 가 아니라 sh 에서 실행하도록 작성하자. ksh 나 bash 의 특수 기능들을 사용하지 말자.
configure 스크립트와 makefile 의 빌드와 설치를 위한 규칙들은 다음과 같은 것들을 제외하고는 유틸리티들을 직접 사용해서는 안된다:
cat cmp cp diff echo egrep expr false grep install-info
ln ls mkdir mv pwd rm rmdir sed sleep sort tar test touch true
압축 프로그램 gzip 은 dist 규칙에서 사용될 수 있다.
이런 프로그램들에 대해서 일반적으로 지원되는 옵션들을 사용하자. 예를 들어서 대부분의 시스템들이 `mkdir -p' 를 지원하지 않기 때문에 이것이 편하더라도 이것을 사용하지 말자.
makefile 안에서 심볼릭 링크를 생성하지 않도록 하는 것은 좋은 생각이다. 왜냐면 소수의 시스템들이 심볼릭 링크를 지원하기 때문이다.
빌드와 설치를 위한 Makefile 규칙들은 컴파일러들과 관련된 프로그램들을 사용할 수 있지만 make 변수들을 통해서 그렇게 해서 사용자가 대안들을 대입할 수 있도록 해야 한다. 다음은 우리가 의미한 프로그램들 몇가지들이다:
ar bison cc flex install ld ldconfig lex
make makeinfo ranlib texi2dvi yacc
다음 make 변수들을 사용해서 이들 프로그램들을 사용하자:
$(AR) $(BISON) $(CC) $(FLEX) $(INSTALL) $(LD) $(LDCONFIG) $(LEX)
$(MAKE) $(MAKEINFO) $(RANLIB) $(TEXI2DVI) $(YACC)
ranlib 나 ldconfig 를 사용할 때 시스템이 문제의 프로그램을 가지고 있지 않다 하더라도 나쁜 일이 일어나지 않도록 해야 한다. 그 명령으로부터 나온 에러를 무시하도록 정렬하고 그 명령이 유저에게 무언가를 말하기 전에, 이 명령이 실제 문제가 아니라고 말하는 메시지를 출력해야 한다. (Autoconf `AC_PROG_RANLIB' 매크로가 이것을 도울 수 있다.)
심볼릭 링크들을 사용한다면 심볼릭 링크들을 가지지 않는 시스템들에 대한 대체물을 구비하여야 한다.
다음과 같은 추가의 유틸리티들이 Make 변수들을 통해서 사용될 수 있다:
chgrp chmod chown mknod
이런 유틸리티들이 존재한다고 알고 있는 특별한 시스템들에 대해서만 의도된 Makefile 일부(또는 스크립트) 안에서 그런 유틸리티들을 사용하는 것은 좋다.
명령을 지정하기 위한 변수(Variables for Specifying Commands)
makefile 은 어떤 명령들, 옵션들, 기타 등등을 오버라이드하기 위한 변수들을 제공해야 한다.
특별히 대부분의 유틸리티 프로그램들을 변수들을 통해서 실행해야 할 것이다. 그래서 Bison 을 사용한다면, 디폴트 값이 `BISON = bison' 로 설정된 BISON 이라는 이름의 변수를 가지고 있다면, Bison 을 사용하고자 할 때마다 그것을 $(BISON) 로 참조하자.
ln, rm, mv, 그리고 기타 등등과 같은 파일 관리 유틸리티들은 이런 식으로 변수들을 통해서 참조될 필요가 없다. 왜냐면 사용들이 그것들을 다른 프로그램들로 변경할 필요가 없기 때문이다.
각 프로그램-이름 변수는 그 프로그램에게 옵션들을 제공하는 데 사용되는 옵션 변수를 함께 가지고 있어야 한다. 프로그램-이름 변수 이름에다 옵션들 변수 이름을 얻기 위해서 `FLAGS' 를 덧붙인다---예를 들어서, BISONFLAGS. (C 컴파일러의 경우 CFLAGS, yacc 의 경우 YFLAGS, lex 의 경우 LFLAGS 이들은 이 규칙의 예외들이지만 그들이 표준이기 때문에 우리는 이들을 사용한다.) 선행처리기를 실행하는 임의의 컴파일 명령에 대해서는 CPPFLAGS 를 사용하고 ld 를 직접 쓰는 경우와 같이 링크를 하는 임의의 컴파일 명령에 대해서는 LDFLAGS 를 쓴다.
특정 파일들을 적절하게 컴파일하는 데 반드시 사용되는 C 컴파일러 옵션들이 있다면 그것들을 CFLAGS 에 넣지 말자. 사용자들은 CFLAGS 를 자유롭게 지정할 수 있을 것이라고 기대한다. 대신에 CFLAGS 와는 독립적으로 C 컴파일러에게 필요한 옵션들을 전달하도록 하자. 그들을 다음과 같이 컴파일 명령들 안에 명시적으로 써넣거나 아니면 묵시적 규칙을 하나 정의해서 말이다:
CFLAGS = -g
ALL_CFLAGS = -I. $(CFLAGS)
.c.o:
$(CC) -c $(CPPFLAGS) $(ALL_CFLAGS) $<
`-g' 옵션을 CFLAGS 안에 넣자. 왜냐면 그것이 적절한 컴파일에 대해서는 필요하지 않기 때문이다. 이것을 단지 권장일뿐인 디폴트로 생각할 수도 있다. 디폴트 값들로 GCC 를 이용해서 컴파일된 팩키지가 셋업될 것이라면 CFLAGS 의 디폴트 값에다 `-O' 도 함께 포함할 수도 있다.
CFLAGS 를 컴파일러 옵션들을 담고 있는 다른 변수들 뒤에, 사용자가 CFLAGS 를 사용해서 다른 것들을 오버라이드할 수 있도록, 컴파일 명령의 맨마지막에 넣자
CFLAGS 는 C 컴파일러의 모든 호출에서 사용되어야 한다. 컴파일하는 것과 링크를 하는 것 모두에서.
모든 Makefile 은 어떤 파일을 시스템으로 설치하는 기본 명령인 INSTALL 변수를 정의해야 한다.
모든 Makefile 은 INSTALL_PROGRAM 와 INSTALL_DATA 변수들을 또한 정의해야 한다. (이들 각각에 대한 디폴트는 $(INSTALL) 이어야 한다.) 그리고 이런 변수들을 실행 파일들과 비실행 파일들 각각을 위한 실제 설치를 위한 명령들로 사용해야 한다. 이런 변수들을 다음과 같이 사용하자:
$(INSTALL_PROGRAM) foo $(bindir)/foo
$(INSTALL_DATA) libfoo.a $(libdir)/libfoo.a
항상 설치 명령들의 두번째 매개변수로써 파일 이름을 사용하고 디렉토리 이름을 사용하지 말자. 설치되는 각 파일에 대해서 분리된 명령을 사용하자.
설치 디렉토리들을 위한 변수(Variables for Installation Directories)
설치 디렉토리들은 항상 변수들에 그 이름을 갖고 있어서 비표준 위치에 설치하는 것이 쉬워야 한다. 이런 변수들을 위한 표준 이름들이 아래에 설명될 것이다. 그들은 표준 파일 시스템 레이아웃에 기반한다: 이것이 변종들이 SVR4, 4.4BSD, Linux, Ultrix v4, 그리고 다른 현대 운영체제들에서 사용된다.
이런 두 변수들은 설치를 위한 루트 디렉토리를 설정한다. 모든 다른 설치 디렉토리들은 이들 중 하나의 서브디렉토리이어야 하고 어떤 것도 이런 두 디렉토리에 직접 설치되어서는 안된다.
`prefix' prefix 는 아래에 나온 변수들의 디폴트값들을 구축할 때 사용된다. prefix 의 디폴트 값은 `/usr/local' 이어야 한다. 완전한 GNU 시스템을 설치할 때, prefix 는 빈 것이 될 것이고 `/usr' 이 `/' 에 심볼릭 링크가 될 것이다. (Autoconf 를 사용한다면 이것을 `@prefix@' 에 써넣으면 된다.)
`exec_prefix'
아래에 나오는 변수들 몇가지의 디폴트 값들을 구축하는 데 사용되는 접두사. exec_prefix 의 디폴트 값은 $(prefix) 이어야 한다. (Autoconf 를 사용하고 있다면 이것을 `@exec_prefix@' 로 쓰자.) 일반적으로 $(exec_prefix) 는 기계-종속적인 파일들(실행 파일들과 서브루틴 라이브러리들과 같은)을 담고 있는 디렉토리들에 사용된다. 반면에 $(prefix) 는 다른 디렉토리들에 사용된다.
실행 프로그램들은 다음과 같은 디렉토리들 중의 하나에 설치된다.
`bindir'
사용자들이 실행할 수 있는 실행 프로그램들을 설치하기 위한 디렉토리. 이것은 일반적으로 `/usr/local/bin' 이지만 `$(exec_prefix)/bin' 로 작성하여야 한다. (Autoconf 를 사용하고 있다면 이것을 `@bindir@' 로 쓰자.)
`sbindir'
쉘로부터 실행 가능하지만 시스템 어드민들에게만 보통 유용한, 실행 프로그램들을 설치하기 위한 디렉토리. 이것은 보통 `/usr/local/sbin' 이지만 `$(exec_prefix)/sbin' 로 작성해야 한다. (Autoconf 를 사용하고 있다면 이것을 `@sbindir@' 로 작성하자.)
`libexecdir'
사용자들이 아니라 다른 프로그램들에 의해서 실행되는 실행가능 프로그램들을 설치하기 위한 디렉토리. 이 디렉토리는 보통 `/usr/local/libexec' 이지만 이것을 `$(exec_prefix)/libexec' 로 쓰자. (Autoconf 를 사용하고 있다면 이것을 `@libexecdir@' 로 쓰자.)
실행 동안 프로그램에 의해서 사용되는 데이터 파일들은 다음과 같은 두 가지 방법으로 분류될 수 있다.
● 어떤 파일들은 일반적으로 프로그램들에 의해서 변경된다; 다른 것들은 절대 보통은 변경되지 않는다(사용자가 이들 중 어떤 것을 편집할수도 있지만).
● 어떤 파일들은 아키텍쳐-독립적이고 한 장소에서 모든 기계들에 의해서 공유될 수 있다; 어떤 것들은 아키텍쳐-독립적이고 동일한 종류와 운영체제의 기계들에 의해서만 공유될 수 있다; 다른 것들은 두 기계들 간에 공유되지 않을 수 있다.
이것은 여섯가지 다른 가능성들을 만든다. 그러나 오브젝트 파일들과 라이브러리들을 제외하고, 아키텍쳐-종속적인 파일들을 사용하지 않기를 권하고 싶다. 데이터 파일들을 아키텍쳐-독립으로 만드는 것이 더 선명하다. 그리고 이렇게 하는 것은 일반적으로 그리 어렵지 않다.
그래서 Makefile 들이 디렉토리들을 지정하는 데 사용하여야 할 변수들을 다음에 놓았다:
`datadir'
읽기-전용 아키텍쳐 독립 데이터 파일들을 설치하는 디렉토리. 이것은 일반적으로 `/usr/local/share' 이어야 한다. 그러나 이것을 `$(prefix)/share' 로 쓴다. (Autoconf 사용자라면 이것을 `@datadir@' 으로 쓴다.) 특별한 예외로써 아래의 `$(infodir)' 과 `$(includedir)' 을 보자.
`sysconfdir'
단일 기계에 대해서(만) 관계된 읽기-전용 데이터 파일을 설치하기 위한 디렉토리--즉, 호스트를 설정하기 위한 파일들의 디렉토리. 메일러나 네트우거 설정 파일들, `/etc/passwd', 그리고 기타 등등이 여기에 해당된다. 이 디렉토리에 있는 모든 파일들은 일반 ASCII 텍스트 파일들이어야 한다. 이 디렉토리는 일반적으로 `/usr/local/etc' 이지만, 이것을 `$(prefix)/etc' 로 쓴다. (Autoconf 를 쓰고 있다면 이것을 `@sysconfdir@' 로 작성하다.) 실행파일들을 이런 디렉토리에 설치하지 말자(그들은 아마도
`$(libexecdir)' 나 `$(sbindir)' 에 속할 것이다). 또한 그들 사용(그것의 목적이 시스템의 설정을 배타적으로 변경하는 프로그램)의 일반저인 과정에서 파일이 변경되는 파일들은 설치하지 말자. 이들은 아마도 `$(localstatedir)'에 포함될 것이다.
`sharedstatedir'
프로그램들이 실행 중에 변경하는 아키텍쳐-독립 데이터 파일들을 설치하는 디렉토리. 이것은 일반적으로 `/usr/local/com' 이어야 하지만 이것을 `$(prefix)/com' 로 쓰자. (Autoconf 를 사용하고 있다면 이것을 `@sharedstatedir@' 로 쓰자.)
`localstatedir'
프로그램들이 실행 중에 변경하는 데이터 파일들을 설치하기 위한, 그리고 특정 기계에만 있는, 디렉토리. 사용자들은 팩키지의 작동을 설정하기 위해서 이 디렉토리에 있는 파일들을 변경할 필요가 전혀 없다; 그런 설정 정보는 독립 파일들 `$(datadir)' 나 `$(sysconfdir)' 에 넣도록 하자. `$(localstatedir)' 는 보통 `/usr/local/var' 이어야 하지만 이것을 `$(prefix)/var' 로 쓰자. (Autoconf 를 사용하고 있다면 이것을 `@localstatedir@' 로 쓰자.)
`libdir'
오브젝트 파일들과 오브젝트 코드의 라이브러리들을 위한 디렉토리. 실행 파일들을 이곳에 설치하지 말자. 그들은 아마도 `$(libexecdir)' 에 가게 될 것이다. libdir 는 보통 `/usr/local/lib' 이어야 하지만 이것을 `$(exec_prefix)/lib' 로 쓰자. (Autoconf 를 사용하고 있다면 이것을 `@libdir@' 로 쓰자.)
`infodir'
해당 팩키지를 위한 Info 파일들을 설치하기 위한 디렉토리. 디폴트로 이것은 `/usr/local/info' 이어야 하지만 `$(prefix)/info' 로 작성되저야 한다. (Autoconf 를 사용하고 있다면 `@infodir@' 로 작성하자.)
`lispdir'
이맥스 Lisp 파일들을 설치하기 위한 디렉토리. 디폴트로 이것은 `/usr/local/share/emacs/site-lisp' 이지만 `$(prefix)/share/emacs/site-lisp' 로 작성되어야 한다. Autoconf 를 사용하고 있다면 디폴트를 `@lispdir@' 로 작성한다. `@lispdir@' 가 작동하도록 만들려면 다음과 같은 라인들을 여러분의 `configure.in' 파일에 넣을 필요가 있다:
lispdir='${datadir}/emacs/site-lisp'
AC_SUBST(lispdir)
`includedir'
C 의 `#include' 선행처리 지시어로 사용자 프로그램에 의해서 포함될 헤더 파일들을 설치하기 위한 디렉토리. 이것은 보통 `/usr/local/include' 이어야 하지만 이것을 `$(prefix)/include' 로 쓰자. (Autoconf 를 사용하고 있다면 이것을 `@includedir@' 로 쓰자.) GCC 가 아닌 대부분의 컴파일러들은 헤더 파일들을 `/usr/local/include' 디렉토리에서 찾지 않는다. 그래서 헤더 파일들을 이런 식으로 설치하는 것은 GCC 의 경우에만 유용하다. 때때로 이것은 어떤 라이브러리들이 실제 GCC 와만 작동하게 끔 고안되었기 때문에 문제가 되지 않는다. 그러나 어떤 라이브러리들은 다른 컴파일러들과도 작동하게끔 고안된 것이 있을 수 있다. 그들은 그들의 헤더 파일들을 하나는 includedir 에 그리고 하나는 oldincludedir 에 설치함으로써 두 곳에 설치해야 한다.
`oldincludedir'
GCC 가 아닌 컴파일러들을 위한 `#include' 헤더 파일들을 설치하는 디렉토리. 이것은 보통 `/usr/include' 이어야 한다. (Autoconf 를 사용하고 있다면 여러분은 이것을 `@oldincludedir@' 로 쓰자.) Makefile 명령들은 oldincludedir 이 빈 값인가 아닌가를 체크해야 한다. 그렇다면 그들은 이것을 사용하려고 시도해서는 안된다; 그들은 헤더 파일들의 두번째설치를 취소 해야 할 것이다. 헤더가 동일한 팩키지로부터 온 것이 아니라면 이 디렉토리에 기존에 있던 헤더를 교체해서는 안된다. 그래서 Foo 라는 팩키지가 헤더 파일 `foo.h' 를 제공한다면, (1) `foo.h' 파일이 거기에 없거나 (2) `foo.h' 이 존재하지만 Foo 팩키지로부터 온 것이라면, oldincludedir 디렉토리에 그 헤더파일을 설치해야 한다. `foo.h' 이 Foo 팩키지로부터 온 것인가를 알아내려면 매직 문자열을 그 파일 안에 넣자---주석의 일부---그리고 그 문자열을 grep 한다.
유닉스-스타일 맨 페이지들은 다음과 같은 것 중의 하나로 설치된다:
`mandir'
맨 페이지들(존재한다면)을 설치하기 위한 톱-레벨 디렉토리. 이것은 보통 `/usr/local/man' 이어야 하지만 이것을 `$(prefix)/man' 로 써야 한다. (Autoconf 를 사용하고 있다면, 이것을 `@mandir@' 로 쓰자.)
`man1dir'
섹션 1 맨 페이지들을 설치하기 위한 디렉토리. 이것을 `$(mandir)/man1' 로 쓰자.
`man2dir'
섹션 2 맨 페이지들을 설치하기 위한 디렉토리. 이것을 `$(mandir)/man2' 로 쓰자.
`...'
GNU 소프트웨어에 대한 주 문서를 맨 페이지로 만들지 말자. 대신에 Texinfo 포멧으로 매뉴얼을 작성하자. 맨 페이지들은 GNU 소프트웨어를 Unix 에서 실행하는 사람들을 위한 것이다. 이것은 우선순위 두번째의 것일 뿐이다.
`manext'
설치된 맨 페이지에 대한 파일 이름 확장자. 이것은 소숫점과 적절한 숫자를 가지고 있어야 한다; 이것은 보통 `.1' 일 것이다.
`man1ext'
설치된 섹션 1 맨 페이지들을 위한 파일 이름 확장자.
`man2ext'
설치된 섹션 2 맨 페이지들을 위한 파일 이름 확장자.
`...'
팩키지가 맨 페이지들을 여러 섹션에 설치해야 한다면, 이런 이름들을 `manext' 대신에 사용하자.
그리고 마지막으로 다음과 같은 변수를 설정해야 할 것이다:
`srcdir'
컴파일되는 소스들을 위한 디렉토리. 이 변수의 값은 보통 configure 쉘 스크립트에 의해서 삽입된다. (Autoconf 를 사용하고 있다면 `srcdir = @srcdir@' 를 쓰자.)
예를 들어서:
# Common prefix for installation directories.
# NOTE: This directory must exist when you start the install.
prefix = /usr/local
exec_prefix = $(prefix)
# Where to put the executable for the command `gcc'.
bindir = $(exec_prefix)/bin
# Where to put the directories used by the compiler.
libexecdir = $(exec_prefix)/libexec
# Where to put the Info files.
infodir = $(prefix)/info
많은 개수의 파일들을 표준 사용자-지정 디렉토리들 중의 하나로 설치한다면 그것들을 그 프로그램만의 서브디렉토리로 묶어 주는 것이 유용할 것이다. 이렇게 한다면 이런 서브디렉토리들을 만들기 위한 install 규칙을 작성해야 할 것이다.
사용자가 위에 나온 변수들 중의 하나의 값으로 서브디렉토리 이름을 포함할 것이라고 기대하지 말자. 설치 디렉토리들을 위한 일관된 변수 이름들을 가질려는 생각은, 사용자가 여러 서로 다른 GNU 팩키지들에 대해서 정확히 동일 값들을 지정할 수 있게 하기 위해서이다. 이것이 유용하기 위해서는 사용자가 그렇게 할 때 모든 팩키지들이 현명하게 작동하도록 잘 설계되어야 한다.
사용자들을 위한 표준 타겟(Standard Targets for Users)
모든 GNU 프로그램들은 다음과 같은 타겟들을 그들의 makefile 안에 가져야 한다:
`all'
전체 프로그램을 컴파일한다. 이것은 디폴트 타겟이어야 한다. 이 타겟은 문서 파일들을 다시 빌드할 필요는 없다; Info 파일들은 일반적으로 배포판 안에 포함되어야 하고, DVI 파일들은 사용자에 의해서 명시적으로 요구될 때에만 만들어져야 한다. 디폴트로 Make 규칙들은 `-g' 옵션으로 컴파일하고 링크해서 그 실행 프로그램들이 디버깅 심벌들을 가지도록 해야 한다. 무력해지는 것에 신경쓰지 않는 사용자들은 그들이 원할 때 그 실행파일들을 strip 할 수 있다.
`install'
프로그램을 컴파일하고 실행 파일들과 라이브러리들, 기타 등등을 이들이 실제 사용을 위해서 위치해야 할 곳에 파일 이름들로 복사한다. 어떤 프로그램이 적절하게 설치되었는가를 검증하기 위한 단순한 테스트가 있다면 이 타겟은 그 테스트를 실행해야 한다. 실행파일들을 설치할 때 그들을 strip하지 말자. 아주 태평스러운 사용자들은 그렇게 하기 위해서 install-strip 를 사용할 수있다. 가능하다면 install 타겟 규칙이 프로그램이 빌드되는 디렉토리에서, `make all' 이 방금 수행되었다면, 아무것도 변경하지 않도록 작성하자. 이것은 프로그램을 한 유저가 빌드하고 그것을 다른 유저가 설치하는 경우에 좋다. 명령들은 파일들이 설치될 모든 디렉토리들을 그들이 앞서 존재하지 않는다면 생성해야 한다. 이것은 prefix 와 exec_prefix 변수들의 갑들로 지정된 디렉토리들과 필요한 모든 서브디렉토리들을 포함한다. 이렇게 하기 위한 한가지 방법은 아래에 설명된 installdirs 타겟을 사용하는 것이다. 맨 페이지를 설치하기 위한 임의의 명령 앞에다 `-' 를 사용해서 make 가 임의의 에러들을 무시하도록 하자. 이것은 설치된 유닉스 맨 페이지 문서 시스템을 가지지 않는 시스템들이 있는 경우를 위한 것이다. Info 파일들을 설치하는 방법은 이들을 `$(infodir)' 에다 $(INSTALL_DATA) 로 (see section 명령을 지정하기 위한 변수(Variables for Specifying Commands)) 복사하고 install-info 프로그램이 존재한다면 이것을 실행하는 것이다. install-info 는 Info `dir' 파일을 편집해서 주어진 Info 파일을 위한 메뉴 엔트리를 추가하거나 갱신하는 프로그램이다; 이것은 Texinfo 팩키지의 일부이다. 다음은 Info 파일을 설치하는 예제 규칙이다:
$(infodir)/foo.info: foo.info
$(POST_INSTALL)
# There may be a newer info file in . than in srcdir.
-if test -f foo.info; then d=.; \
else d=$(srcdir); fi; \
$(INSTALL_DATA) $$d/foo.info $@; \
# Run install-info only if it exists.
# Use `if' instead of just prepending `-' to the
# line so we notice real errors from install-info.
# We use `$(SHELL) -c' because some shells do not
# fail gracefully when there is an unknown command.
if $(SHELL) -c 'install-info --version' \
>/dev/null 2>&1; then \
install-info --dir-file=$(infodir)/dir \
$(infodir)/foo.info; \
else true; fi
install 타겟을 작성할 때, 모든 명령들을 다음과 같은 세 범주들로 분류해야 한다: 일반 명령, 설치-이전(pre-installation) 명령, 그리고 설치-이후(post-installation) 명령. See section 설치 명령 범주(Install Command Categories).
`uninstall' 모든 설치된 파일들을 삭제한다---`install' 타겟이 생성한 복사물들. 이 규칙은 컴파일이 수행된 디렉토리들을 변경해서는 안된다. 파일들이 설치된 디렉토리들만 변경해야 한다. 설치 제거 명령들은 설치 명령들과 같이 세개의 범주들로 나뉜다. See section 설치 명령 범주(Install Command Categories).
`install-strip'
install 와 같지만 실행 파일들을 설치할 때 이들의 심벌들을 제거한다. 많은 경우에 이 타겟의 정의는 다음처럼 아주 단순할 수 있다:
install-strip:
$(MAKE) INSTALL_PROGRAM='$(INSTALL_PROGRAM) -s' \
install
보통 프로그램이 버그가 없다는 것을 확신하지 못한다면 실행 파일의 심벌들을 제거하는 것을 권장하고 싶지 않다. 그러나 버그가 있을 경우를 대비해서 심벌들을 제거하지 않는 실행파일을 어딘가에 저장하고 실제 실행 파일은 심벌들을 제거해서 설치하는 것도 합리적일 수 있다.
`clean'
보통 프로그램을 빌드하면서 생성되는, 현재 디렉토리에 있는, 모든 파일들을 제거한다. 환경설정을 길고한 파일들은 지우
지 않는다. 또한 빌드에 의해서 생성될 수 있지만 보통은 만들어지지 않는 파일들을, 배포판이 그들을 담고 있기 때문에, 보
존한다. `.dvi' 파일들이 배포판의 일부가 아니라면 이들을 지워라.
`distclean'
현재 디렉토리로부터 환경 설정과 프로그램 빌드 과정에 의해서 생성된 모든 파일들을 지운다. 소스를 unpack 했고 그 프로그램을 다른 파일들을 생성하지 않고서 빌드했다면 `make distclean' 는 배포판에 있었던 파일들만을 지울 것이다.
`mostlyclean'
`clean' 과 비슷하지만 사람들이 보통 재컴파일하고자 하지 않는 몇가지 파일들을 삭제하지 않을 수 있다. 에를 들어서 GCC를 위한 `mostlyclean' 타겟은 `libgcc.a' 를 삭제하지 않는다. 왜냐면 이것을 재컴파일하는 것은 거의 필요가 없고 시간만 많이 걸리기 때문이다.
`maintainer-clean'
현재 디렉토리로부터, Makefile 로 다시 만들어질 수 있는 거의 모든 것을 삭제한다. 이것은 전형적으로 distclean 로 삭제되는 모든 것과 그 외의 것들을 포함한다: Bison 에 의해서 만들어진 C 소스 파일, 태그 테이블, Info 파일들, 기타 등등. 우리가 "거의 모든것" 이라고 말한 이유는 명령 `make maintainer-clean' 를 실행하는 것은 `configure' 가 Makefile 의 한 규칙을 사용해서 만들어질 수 있다고 하더라도, `configure' 를 지우지 않을 것이기 때문이다. 좀 더 일반적으로 `make maintainer-clean' 는 `configure' 를 실행하기 위해서 존재해야 하는 어떤 것도 지우지 않고 프로그램을 빌드하기 시작하는 어떤 것도 지우지 않는다. 이것은 유일한 예외이다; maintainer-clean 는 다시 빌드될 수 없는 다른 모든 것들을 삭제할 것이다. `maintainer-clean'
타겟은 일반 사용자들에 의해서가 아니라 팩키지의 관리자에 의해서 사용될 것으로 고안된 것이다. `make maintainer-clean' 가 삭제한 파일들 몇가지를 재건축하려면 특수한 툴들이 필요할 수 있다. 이런 파일들은 일반적으로 배포판 안에 포함되기 때문에 우리는 그들이 다시 만들어지기 쉽도록 신경쓰지 않는다. 전체 배포판을 다시 unpack 하는 것이 필요하다고 생각되더라도 우리를 원망하지 말라. 사용자들이 이런 것을 알도록 하기 위해서 특수 maintainer-clean 타겟의 명령들은 다음과 같은 두 라인으로 시작해야 한다.
@echo 'This command is intended for maintainers to use; it'
@echo 'deletes files that may need special tools to rebuild.'
`TAGS'
이것은 프로그램에 대한 태그 테이블을 갱신한다.
`info'
필요한 임의의 Info 파일들을 생성한다. 규칙을 작성하는 가장 좋은 방법은 다음과 같은 것이다:
info: foo.info
foo.info: foo.texi chap1.texi chap2.texi
$(MAKEINFO) $(srcdir)/foo.texi
변수 MAKEINFO 는 반드시 Makefile 안에서 정의해야 한다. 이것은 makeinfo 프로그램을 실행해야 하며, 이것은 Texinfo 배포판의 일부이다. 일반적으로 GNU 배포판은 Info 파일들이 따라 온다. 즉 Info 파일들이 소스 디렉토리에 존재한다는 것을 의미한다. 그러므로 info 파일을 위한 Make 규칙은 그것을 소스 디렉토리에서 갱신해야 할 것이다. 사용자가 팩키지를 빌드 할 때 일반적으로 Make 는 Info 파일들을 갱신하지 않을것이다. 왜냐면 그들이 이미 갱신되었을 것이기 때문이다.
`dvi'
모든 Texinfo 문서들에 대해서 DVI 파일들을 생성한다. 예를 들어서:
dvi: foo.dvi
foo.dvi: foo.texi chap1.texi chap2.texi
$(TEXI2DVI) $(srcdir)/foo.texi
반드시 Makefile 안에 TEXI2DVI 변수를 정의해야 한다. 이것은 texi2dvi 를 반드시 실행해야 한다. 이것은 Texinfo 배포판의 일부 (texi2dvi는 TeX 를 사용해서 포멧팅의 실제 작업을 수행한다. TeX 는 Texinfo 와 함께 배포되지 않는다) 이다. 또는, 단지 종속물들만 써서 GNU make 가 그 명령을 제공하도록 하자.
`dist'
이 프로그램에 대한 배포판 tar 파일을 생성한다. tar 파일은 tar 파일안의 파일 이름들이 팩키지가 배포되는, 그리고 팩키지의 이름인, 서브디렉토리 이름으로 시작하게끔 설정되어야 한다. 이 이름은 버전 이름을 포함할 수 있다. 예를 들어서 GCC 버전 1.40 의 배포판 tar 파일은 `gcc-1.40' 라는 이름의 서브디렉토리로 압축이 풀린다. 이렇게 하기 위한 가장 쉬운 방법은 적절하게 이름을 붙인 서브디렉토리를 생성하고 ln 이나 cp 를 사용해서 적절한 파일들을 그 디렉토리 안으로 설치하고, 그리고 나서 그 서브디렉토리를 tar 하는 것이다. 그 tar 파일을 gzip 으로 압축하자. 예를 들어서 GCC 버전 1.40 을 위한 실제 배포판 파일은 `gcc-1.40.tar.gz' 이 될 것이다. dist 타겟은, 배포판에서 그들이 갱신된 것이라는 것을 확실하게 하기 위해서, 반드시 명시적으로 배포판에 있는 모든 소스가 아닌 파일들에 의존해야 한다. See section `Making Releases' in GNU Coding Standards.
`check'
자체-테스트(만일 있다면)를 수행한다. 사용자는 테스트를 수행하기 전에 반드시 프로그램을 빌드해야 한다. 그러나 그 프로그램을 설치할 필요는 없다; 그 프로그램이 빌드되었지만 인스톨되지 않았더라도 잘 작동하도록 자체-테스트들을 작성 해야 한다.
다음 타겟들은 관례적인 이름들로 제안된 것이다.
installcheck
설치 테스트(만일 있다면)를 수행한다. 사용자는 이 테스트를 수행하기 전에 반드시 빌드해야 하고 설치해야 한다. `$(bindir)' 디렉토리가 검색 경로에 있을 것이라고 가정해서는 안된다.
installdirs
파일들이 설치되는 디렉토리들과 그들의 부모 디렉토리들을 생성하기 위한 `installdirs' 라는 이름의 타겟을 추가하는 것이 유용하다. 이런 것에 편리한 `mkinstalldirs' 라고 불리는 스크립트가 존재한다; 이것은 Texinfo 팩키지에서 찾을 수 있다. 여러분은 다음과 같은 규칙을 사용할 수 있다:
# Make sure all installation directories (e.g. $(bindir))
# actually exist by making them if necessary.
installdirs: mkinstalldirs
$(srcdir)/mkinstalldirs $(bindir) $(datadir) \
$(libdir) $(infodir) \
$(mandir)
이 규칙은 컴파일이 수행된 디렉토리들을 변경해서는 안된다. 이것은 설치 디렉토리들을 생성하는 일만 해야 한다.
설치 명령 범주(Install Command Categories)
install 타겟을 작성할 때, 모든 명령들을 다음과 같은 세가지 범주로 분류해야 한다: 정규적인 것, 설치-이전(pre-installation) 명령어들, 그리고 설치-이후(post-installation) 명령어들.
정규 명령어들은 파일들을 그들의 적절한 위치에 옮기고, 그들의 모드를 설정한다. 그들은 이들이 속한 팩키지로부터 전체적으로 오는 것들을 제외하고는 어떤 파일들도 변경하지 않는다.
설치-이전과 설치-이후 명령들은 다른 파일들을 변경할 수도 있다; 특별히 그들은 글로벌 설정 파일들이나 데이터 베이스들을 편집할 수 있다.
설치-이전 명령어들은 전형적으로 정규 명령들 이전에 실행되고, 설치-이후 명령어들은 전형적으로 정규 명령어들 이후에 실행된다.
설치-후 명령에 대한 대부분의 일반적인 사용은 install-info 를 실행하는 것이다. 이것은 일반적인 명령으로 실행될 수 없다. 왜냐면 이것은 설치중인 팩키지로부터 완전히 그리고 이것으로부터만 온 것이 아닌 파일(Info 디렉토리)을 변경하기 때문이다. 팩키지의 Info 파일들을 설치하는 일반 명령 뒤에 수행되어야 하기 때문에 이것은 설치-이후 명령이다.
대부분의 프로그램들은 어떤 설치-이전 명령들을 필요로하지 않는다. 그러나 필요할 때를 대비해서 그 기능을 가지고 있다.
install 규칙에 있는 명령들을 이런 세가지 범주들로 구분하기 위해서 그들 사이에 범주 라인(category lines) 를 삽입하자. 범주 라인은 그 뒤에 오는 명령들에 대한 범주를 지정한다.
범주 라인은 하나의 탭과 특정 Make 변수에 대한 참조, 그리고 마지막에 옵션인 주석으로 이루어져 있다. 사용할 수 있는 변수들은 세개 있으며 이들 각각은 각 범주를 위한 것이다; 변수 이름이 범주를 지정한다. 범주 라인들은 일반적인 실행에서는 아무런 작동도 하지 않는다. 왜냐면 이런 세 Make 변수들은 일반적으로 정의되지 않기 때문이다(그리고 여러분은 그것들을 makefile 안에서 정의해서는 안된다).
다음은 가능한 세가지 범주 라인들이며 이들 각각은 그것이 의미하는 바를 설명하는 주석을 달고 있다:
$(PRE_INSTALL) # Pre-install commands follow.
$(POST_INSTALL) # Post-install commands follow.
$(NORMAL_INSTALL) # Normal commands follow.
install 규칙의 처음에 범주 라인을 쓰지 않는다면 모든 명령들은 첫번째 범주 라인 이전까지 일반으로 구분된다. 범주 라인들을 전혀 사용하지 않는다면 모든 명령들이 일반으로 구분된다.
다음이 uninstall 에 대한 범주 라인들이다:
$(PRE_UNINSTALL) # Pre-uninstall commands follow.
$(POST_UNINSTALL) # Post-uninstall commands follow.
$(NORMAL_UNINSTALL) # Normal commands follow.
전형적으로 설치-이전 명령은 Info 디렉토리로부터 항목들을 지우는 일을 하는 데 사용된다.
install 또는 uninstall 타겟이 설치의 서브루틴들처럼 작동하는 종속물들을 가지고 있다면 각 종속물의 명령들을 범주 라인으로 시작해야 하고 메인 타겟의 명령들도 범주 라인으로 시작해야 한다. 이런식으로 어떤 종속물들이 실제로 실행되든지 상관없이, 정확한 범주안에 놓여 있다는 것을 보장할 수 있다.
설치-이전 및 설치-이후 명령들은 다음과 같은 것들을 제외한 프로그램들을 실행해서는 안될것이다:
[ basename bash cat chgrp chmod chown cmp cp dd diff echo
egrep expand expr false fgrep find getopt grep gunzip gzip
hostname install install-info kill ldconfig ln ls md5sum
mkdir mkfifo mknod mv printenv pwd rm rmdir sed sort tee
test touch true uname xargs yes
이런식으로 명령들을 구분하는 이유는 바이너리 팩키지를 만들기 위해서이다. 전형적으로 바이너리 팩키지는 모든 실행파일들과 설치에 필요한 다른 파일들을 담고 있고, 이 설치에 필요한 파일들을 설치하는 자신의 방법을 갖고 있다---그래서 이것은 일반적인 설치 명령들이 필요없다. 그러나 바이너리 팩키지를 설치하는 것은 설치-이전과 설치-이후 명령들을 실행할 필요가 있다.
바이너리 팩키지들을 빌드하는 프로그램들은 설치-이전 및 설치-이후 명령들을 추출함으로써 작동한다. 다음은 설치-이전 명령들을 추출하는 한가지 방법이다:
make -n install -o all \
PRE_INSTALL=pre-install \
POST_INSTALL=post-install \
NORMAL_INSTALL=normal-install \
| gawk -f pre-install.awk
여기에서 `pre-install.awk' 는 다음과 같은 것을 담고 있을 것이다:
$0 ~ /^\t[ \t]*(normal_install|post_install)[ \t]*$/ {on = 0}
on {print $0}
$0 ~ /^\t[ \t]*pre_install[ \t]*$/ {on = 1}
설치-이전 명령들의 결과 파일은, 바이너리 팩키지를 설치하는 일부인 쉘 스크립트로써 실행된다.
빠른 레퍼런스(Quick Reference)
이 부록은 GNU make 가 이해하는 지시어, 텍스트 조작 함수, 그리고 특수 변수들에 대해서 요약한 것이다. 다른 요약들을 보고자 한다면 See section 특수 내장 타겟 이름(Special Built-in Target Names), section 묵시적 규칙들의 카달로그(Catalogue of Implicit Rules), and section 옵션들의 요약(Summary of Options).
다음은 GNU make 가 인식하는 지시어들을 요약한 것이다:
define variable
endef
멀티-라인, 재귀적으로 확장되는 변수 하나를 정의한다.
See section 명령들을 묶어서 정의하기(Defining Canned Command Sequences).
ifdef variable
ifndef variable
ifeq (a,b)
ifeq "a" "b"
ifeq 'a' 'b'
ifneq (a,b)
ifneq "a" "b"
ifneq 'a' 'b'
else
endif
makefile 의 조건 평가 부분.
See section Makefile의 조건 부분(Conditional Parts of Makefiles).
include file
다른 makefile 을 포함한다.
See section 다른 makefile 삽입(Including Other Makefiles).
override variable = value
override variable := value
override variable += value
override define variable
endef
변수 하나를 정의하고 이전의 정의를 오버라이드하다. 심지어 명령행에서의 정의까지 오버라이드한다.
See section override 지시어.
export
make 에게 차일드 프로세스들에게 디폴트로 모든 변수들을 익스포트하도록 지시.
See section 서브-make에 대한 통신 변수(Communicating Variables to a Sub-make).
export variable
export variable = value
export variable := value
export variable += value
unexport variable
make 에게 특정한 변수를 차일드 프로세스들에게 익스포트할 것인가 아닌가를 지시한다.
See section 서브-make에 대한 통신 변수(Communicating Variables to a Sub-make).
vpath pattern path
`%' 패턴과 일치하는 파일들에 대해서 검색 경로를 지정.
See section vpath 지시어.
vpath pattern
pattern 로 사전에 지정된 모든 검색 경로들을 제거.
vpath
vpath 지시어에 의해서 사전에 지정된 모든 검색 경로들을 제거.
다음은 텍스트 조작 함수들의 요약이다 (see section 텍스트 변환을 위한 함수(Functions for Transforming Text)): Here is a summary of the text manipulation functions (see section 텍스트 변환을 위한 함수(Functions for Transforming Text)):
$(subst from,to,text)
text 에서 from 를 to 로 교체.
See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
$(patsubst pattern,replacement,text)
text 에서 pattern 과 일치하는 것을 replacement 로 교체.
See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
$(strip string)
string 로부터 여분의 공백 문자들을 제거.
See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
$(findstring find,text)
text 에서 find 를 찾음(locate).
See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
$(filter pattern...,text)
pattern 단어들중의 하나와 일치하는 text 내의 단어들을 선택.
See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
$(filter-out pattern...,text)
pattern 단어들중의 하나와 일치하지 않는 단어들을 text에서 선택.
See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
$(sort list)
list 에 있는 단어들을 사전식으로 소팅하고 중복된 것들을 제거.
See section 문자 대입과 분석을 위한 함수들(Functions for String Substitution and Analysis).
$(dir names...)
각 파일 이름에서 디렉토리 부분을 추출.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(notdir names...)
각 파일 이름에서 비-디렉토리 부분을 추출.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(suffix names...)
각 파일 이름의 확장자(마지막 `.'과 다음 문자들)를 추출.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(basename names...)
각 파일 이름의 몸체 이름(확장자를 뺀 이름)을 추출.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(addsuffix suffix,names...)
names 에 있는 각 단어의 뒤에다 suffix 를 붙인다.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(addprefix prefix,names...)
prefix 를 names 에 있는 각 단어 앞에다 붙인다.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(join list1,list2)
두 단어들의 병렬 리스트를 묶는다.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(word n,text)
text 에서 n번째 단어(시작은 1)를 추출한다.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(words text)
text 에서 단어들의 개수를 계산한다.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(firstword names...)
names 의 첫번째 단어를 추출한다.
See section 파일 이름들을 위한 함수(Functions for File Names).
$(wildcard pattern...)
쉘 파일 이름 패턴 (`%' 패턴이 아님) 과 일치하는 파일 이름들을 찾는다.
See section wildcard 함수(The Function wildcard).
$(shell command)
쉘 명령을 실행하고 그것의 결과를 리턴.
See section shell 함수(The shell Function).
$(origin variable)
make 변수 variable 가 정의된 방법을 설명하는 문자열을 리턴.
See section origin 함수(The origin Function).
$(foreach var,words,text)
words 에 있는 각 단어를 가리키는 var 로 text 를 평가하고 그 결과를 서로 붙인다.
See section foreach 함수(The foreach Function).
다음은 완전한 정보를 대신할 자동 변수들See section 자동 변수들(Automatic Variables)의 요약이다.
$@
타겟의 파일 이름.
$%
타겟이 아카이브 멤버일 때, 타겟의 멤버 이름.
$<
첫번째 종속물의 이름.
$?
타겟보다 더 새로운 모든 종속물들의 이름. 이들 사이는 스페이스들로 구분된다. 아카이브 멤버들인 종속물들의 경우 이름 있는 멤버들만이 사용된다 (see section 아카이브 파일을 갱신하기 위해서 make 사용하기(Using make to Update Archive Files)).
$^
$+
모든 종속물들의 이름. 이들 사이는 공백으로 구분된다. 아카이브 멤버들인 종속물들의 경우 이름있는 멤버만이 사용된다 (see section 아카이브 파일을 갱신하기 위해서 make 사용하기(Using make to Update Archive Files)). $^의 값은 중복된 종속물들을 생략한다. 반면에 $+는 그들을 그대로 가지고 그들의 순서를 유지한다.
$*
묵시적인 규칙이 매치된 줄기 (see section 패턴 비교 방법(How Patterns Match)).
$(@D)
$(@F)
$@의 디렉토리-안에 있는-파일 부분과 디렉토리 부분.
$(*D)
$(*F)
$*의 디렉토리-안에 있는-파일 부분과 디렉토리 부분.
$(%D)
$(%F)
$%의 디렉토리-안에 있는-파일 부분과 디렉토리 부분.
$(<D)
$(<F)
$<의 디렉토리-안에 있는-파일 부분과 디렉토리 부분.
$(^D)
$(^F)
$^의 디렉토리-안에 있는-파일 부분과 디렉토리 부분.
$(+D)
$(+F)
$+의 디렉토리-안에 있는-파일 부분과 디렉토리 부분.
$(?D)
$(?F)
$?의 디렉토리-안에 있는-파일 부분과 디렉토리 부분.
다음 변수들은 GNU make에 의해서 특별하게 사용된다:
MAKEFILES
make 의 모든 실행때마다 읽히는 makefile들. See section MAKEFILES 변수(The Variable MAKEFILES).
VPATH
현재 디렉토리에서 찾을 수 없는 파일들에 대한 디렉토리 검색 경로. See section VPATH: 모든 종속물에 대한 검색 패스(Search Path for All Dependencies).
SHELL
시스템의 디폴트 명령 해석기의 이름. 일반적으로 `/bin/sh'. 명령들을 실행하는 데 사용되는 쉘을 변경하기 위해서 makefile에서 SHELL 을 설정할 수 있다. See section 명령 실행(Command Execution).
MAKESHELL
MS-DOS 에서만 사용되며 make 에 의해서 사용되는 명령 해석기의 이름. 이 값은 SHELL 의 값보다 우선한다. See section 명령 실행(Command Execution).
MAKE
make 가 호출된 이름. 이 변수를 명령에서 사용하는 것은 특수한 의미가 있다. See section MAKE 변수가 작동하는 방법(How the MAKE Variable Works).
MAKELEVEL
재귀적 진입의 단계 번호 (서브-make들의). See section 서브-make에 대한 통신 변수(Communicating Variables to a Sub-make).
MAKEFLAGS
make 에 주어진 플래그들. 플래그들을 설정하기 위해서 환경에서나 makefile 안에서 이것을 설정할 수 있다. See section 서브-make에 대한 통신 옵션(Communicating Options to a Sub-make).
MAKECMDGOALS
make 에 대해서 명령행에서 주어진 타겟. 이 변수를 설정하는 것은 make 의 작업에 어떤 영향도 미치지 않는다. See section goal을 지정하는 매개변수(Arguments to Specify the Goals).
CURDIR
현재 작업 디렉토리(모든 -C 옵션들이, 있다면 처리된 후)의 경로명으로 설정된다. 이 변수를 설정하는 것은 make 의 작업에 어떤 영향도 미치지 않는다. See section make의 재귀적 사용(Recursive Use of make).
SUFFIXES
make 가 makefile 들을 읽기 전의 접미사들의 디폴트 리스트.
make 의 에러(Errors Generated by Make)
다음은 make 에 의해서 생성될 수 있는 가장 일반적인 에러들의 리스트이며 그것들이 의미하는 바와 그것들을 고치는 방법에 대한 정보이다.
때때로 make 에러들은, 특별히 명령 스크립트 라인에서 - 접두사가 있을 때나 명령 라인 옵션으로써 -k 가 있을 때, 치명적인 것이 아니다. 치명적인 에러들은 *** 문자열이 그 앞에 붙는다.
에러 메시지들은 모두 프로그램(보통 `make')의 이름이 앞에 붙거나, 에러가 makefile 안에 있는 것이라면 문제를 담고 있는 파일과 라인넘버가 앞에 붙는다.
아래 테이블에서 이런 공통 접두사들이 빠져있다.
`[foo] Error NN'
`[foo] signal description'
이런 에러들은 실제로 make 에러들이 전혀 아니다. 그들은 make 가 명령 스크립트의 일부로써 호출한 프로그램이, make 가 실패로 해석하는 0이 아닌 에러 코드 (`Error NN') 를 리턴하거나 다른 이상한 스타일로(어떤 종류의 시그널과 함께) 종료하였다는 것을 의미한다. *** 가 메시지에 붙어 있지 않으면 서브프로세스가 실패했지만 makefile 의 그 규칙이 특수 문자 - 를 앞에 달고 있어서 make 가 그 에러를 무시한 것이다.
`missing separator. Stop.'
이것은 make 의 일반적인 "Huh?" 에러 메시지이다. 이것은 make 가 makefile 의 이 라이을 파싱하면서 완벽하게 성공하지 못했다는 것을 의미한다. 이것은 기본적으로 "문법 에러(syntax error)" 를 의미한다. 이런 메시지가 나오는 가장 일반적인 이유들 중의 하나는 여러분이 (또는 많은 MS-Windows 에디터들의 경우와 비슷하게, 여러분의 에디터가) TAB 문자 대신에 공백들로 명령 스크립트들을 들여쓰기하려고 하는 것이다. 명령 스크립트에 있는 모든 라인은 반드시 TAB 문자로 시작하는 것을 기억하자. 8개의 공백은 의미가 없다.
`commands commence before first target. Stop.'
`missing rule before commands. Stop.'
이것은 makefile 에서 처음으로 나오는 것이 명령 스크립트의 일부분인 것처럼 보인다는 것을 의미한다: 이것은 TAB 문자로 시작하고 합법적인 make 명령(변수 할당과 같은)처럼 보이지 않는다. 명령 스크립트들은 항상 어떤 타겟과 연결되어 있어야 한다. 두번째 형태는 그 라인이 첫번째 공백문자가 아닌 문자로써 세미콜론을 가진다면 생성된다; make 는 이것을, 어떤 규칙의 "target: dependency" 섹션을 그냥 떠났다는 것으로 해석한다.
`No rule to make target `xxx'.'
`No rule to make target `xxx', needed by `yyy'.'
이것은 make 가 타겟을 빌드할 필요가 있다고 판단했지만 makefile 안에서 그렇게 하는 것에 대한, 명시적 또는 묵시적(디폴트 규칙 데이터베이스를 포함해서) 규칙들(instructions)도 찾을 수 없다는 것을 의미한다. 그 파일이 빌드되기를 원한다면 그 타겟이 빌드되는 방법을 설명하는 규칙을 추가할 필요가 있다. 이 문제의 다른 가능성은 makefile 을 오자(그 파일 이름이 잘못되었다)했거나 소스 트리가 잘못된 경우이다(그 파일이 빌드될 것으로 생각된 것이 아니고 단지 종속물이다).
`No targets specified and no makefile found. Stop.'
`No targets. Stop.'
전자는 명령행에서 빌드될 타겟을 하나도 제공하지 않았고 make 가 읽어들일 makefile 들을 찾을수 없다는 것을 의미한다. 후자는 어떤 makefile 들이 찾아졌으나 디폴트 타겟이 없고 어떤 것도 명령행에서 주어지지 않았다는 것을 의미한다. 이들 경우에 GNU make 는 아무것도 하지 않는다.
`Makefile `xxx' was not found.'
`Included makefile `xxx' was not found.'
명령행에서 주어진 makefile (첫번째 형태) 또는 포함된 makefile (두번째 형태) 가 없다.
`warning: overriding commands for target `xxx''
`warning: ignoring old commands for target `xxx''
GNU make 는 타겟 하나에 대해서 단 한번만 명령들이 지정되는 것을 허락한다(더블-콜론 규칙들을 제외하고). 이미 명령들을 가지도록 정의된 타겟에 대해서 명령들을 다시 주면 이 경고가 발행되고 두번째 명령들은 첫번째 것을 오버라이드할 것이다.
`Circular xxx <- yyy dependency dropped.'
make 가 종속성 그래프에서 루프를 발견했다는 것을 의미한다: 타겟 xxx 의 종속물 yyy, 그리고 이것의 종속물들 등등 을 추적한 후 그들중 하나가 xxx 에 다시 종속한다는 의미이다.
`Recursive variable `xxx' references itself (eventually). Stop.'
이것은 확장될 때 자기자신(xxx)을 참조할 일반 (재귀적인) make 변수 xxx 를 정의했다는 것을 의미한다. 이것은 허용되지 않는다; 단순-확장 변수 (:=) 를 사용하든지 아니면 추가 연산자 (+=) 를 사용하자.
`Unterminated variable reference. Stop.'
이것은, 변수나 함수 참조에서 적절하게 닫는 괄호나 중괄호를 제공하는 것을 잊었다는 것을 의미한다.
`insufficient arguments to function `xxx'. Stop.'
이것은 이 함수에 대해서 필요한 개수의 매개변수들을 제공하지 않았다는 것을 의미한다. 매개변수들의 설명에 대해서는 그 함수의 문서를 보자.
`missing target pattern. Stop.'
`multiple target patterns. Stop.'
`target pattern contains no `%'. Stop.'
이들은 잘못된 정적 패턴 규칙들에 대해서 생성된다. 첫번째는 규칙의 타겟 섹션에 어떤 패턴도 없다는 것을 의미하고, 두번째는 타겟 섹션에 다수의 패턴들이 있다는 것을 의미하며, 세번째는 타겟이 패턴 문자 (%) 를 담고 있지 않다는 것을 의미한다.
복잡한 makefile 예제(Complex Makefile Example)
다음은 GNU tar 프로그램에 대한 makefile 이다. 이것은 적당히 복잡한 makefile 이다.
`all' 이 첫번째 타겟이기 때문에 디폴트 목표(goal) 은 이것이 된다. 이 makefile 의 흥미로운 기능은, `testpad.h' 라는 파일이 `testpad.c' 으로부터 컴파일되는 testpad 프로그램에 의해서 자동으로 생성된 소스 파일이다는 것이다.
`make' 나 `make all' 를 입력하면 make 는 `tar' 실행 파일, 원격 테입 억세스를 제공하는 `rmt' 데몬, `tar.info' Info 파일 등을 생성한다.
`make install' 라고 입력하면 make 는 `tar', `rmt', 그리고 `tar.info' 를 생성할 뿐만이 아니고 그것들을 설치한다.
`make clean' 라고 입력한다면 make 는 `.o' 파일을 모두 제거하고 `tar', `rmt', `testpad', `testpad.h', 그리고 `core' 파일들을 모두 제거한다.
`make distclean' 라고 입력하면 make 는 `make clean' 과 동일한 파일들 뿐만이 아니고 `TAGS', `Makefile', 그리고 `config.status' 파일들도 삭제한다. (비록 명백하지 않다 하더라도, 이 makefile (그리고 `config.status') 는 사용자에 의해서, tar 배포판에서 제공되는 configure 프로그램에 의해서 생성되었을 것이다. 그러나 이것은 여기에 설명되지 않았다.)
`make realclean' 라고 입력한다면 make 는 `make distclean' 이 한 것과 동일한 파일들을 제거하고 `tar.texinfo' 로부터 생성된 Info 파일들도 제거한다.
배포판 킷을 생성하는 shar 와 dist 타겟들이 있다.
# configure 에 의해서 Makefile.in 으로부터 자동으로 생성됨.
# GNU tar 프로그램을 위한 Un*x Makefile.
# Copyright (C) 1991 Free Software Foundation, Inc.
# This program is free software; you can redistribute
# it and/or modify it under the terms of the GNU
# General Public License ...
...
...
SHELL = /bin/sh
#### Start of system configuration section. ####
srcdir = .
# If you use gcc, you should either run the
# fixincludes script that comes with it or else use
# gcc with the -traditional option. Otherwise ioctl
# calls will be compiled incorrectly on some systems.
CC = gcc -O
YACC = bison -y
INSTALL = /usr/local/bin/install -c
INSTALLDATA = /usr/local/bin/install -c -m 644
# Things you might add to DEFS:
# -DSTDC_HEADERS If you have ANSI C headers and
# libraries.
# -DPOSIX If you have POSIX.1 headers and
# libraries.
# -DBSD42 If you have sys/dir.h (unless
# you use -DPOSIX), sys/file.h,
# and st_blocks in `struct stat'.
# -DUSG If you have System V/ANSI C
# string and memory functions
# and headers, sys/sysmacros.h,
# fcntl.h, getcwd, no valloc,
# and ndir.h (unless
# you use -DDIRENT).
# -DNO_MEMORY_H If USG or STDC_HEADERS but do not
# include memory.h.
# -DDIRENT If USG and you have dirent.h
# instead of ndir.h.
# -DSIGTYPE=int If your signal handlers
# return int, not void.
# -DNO_MTIO If you lack sys/mtio.h
# (magtape ioctls).
# -DNO_REMOTE If you do not have a remote shell
# or rexec.
# -DUSE_REXEC To use rexec for remote tape
# operations instead of
# forking rsh or remsh.
# -DVPRINTF_MISSING If you lack vprintf function
# (but have _doprnt).
# -DDOPRNT_MISSING If you lack _doprnt function.
# Also need to define
# -DVPRINTF_MISSING.
# -DFTIME_MISSING If you lack ftime system call.
# -DSTRSTR_MISSING If you lack strstr function.
# -DVALLOC_MISSING If you lack valloc function.
# -DMKDIR_MISSING If you lack mkdir and
# rmdir system calls.
# -DRENAME_MISSING If you lack rename system call.
# -DFTRUNCATE_MISSING If you lack ftruncate
# system call.
# -DV7 On Version 7 Unix (not
# tested in a long time).
# -DEMUL_OPEN3 If you lack a 3-argument version
# of open, and want to emulate it
# with system calls you do have.
# -DNO_OPEN3 If you lack the 3-argument open
# and want to disable the tar -k
# option instead of emulating open.
# -DXENIX If you have sys/inode.h
# and need it 94 to be included.
DEFS = -DSIGTYPE=int -DDIRENT -DSTRSTR_MISSING \
-DVPRINTF_MISSING -DBSD42
# Set this to rtapelib.o unless you defined NO_REMOTE,
# in which case make it empty.
RTAPELIB = rtapelib.o
LIBS =
DEF_AR_FILE = /dev/rmt8
DEFBLOCKING = 20
CDEBUG = -g
CFLAGS = $(CDEBUG) -I. -I$(srcdir) $(DEFS) \
-DDEF_AR_FILE=\"$(DEF_AR_FILE)\" \
-DDEFBLOCKING=$(DEFBLOCKING)
LDFLAGS = -g
prefix = /usr/local
# Prefix for each installed program,
# normally empty or `g'.
binprefix =
# The directory to install tar in.
bindir = $(prefix)/bin
# The directory to install the info files in.
infodir = $(prefix)/info
#### End of system configuration section. ####
SRC1 = tar.c create.c extract.c buffer.c \
getoldopt.c update.c gnu.c mangle.c
SRC2 = version.c list.c names.c diffarch.c \
port.c wildmat.c getopt.c
SRC3 = getopt1.c regex.c getdate.y
SRCS = $(SRC1) $(SRC2) $(SRC3)
OBJ1 = tar.o create.o extract.o buffer.o \
getoldopt.o update.o gnu.o mangle.o
OBJ2 = version.o list.o names.o diffarch.o \
port.o wildmat.o getopt.o
OBJ3 = getopt1.o regex.o getdate.o $(RTAPELIB)
OBJS = $(OBJ1) $(OBJ2) $(OBJ3)
AUX = README COPYING ChangeLog Makefile.in \
makefile.pc configure configure.in \
tar.texinfo tar.info* texinfo.tex \
tar.h port.h open3.h getopt.h regex.h \
rmt.h rmt.c rtapelib.c alloca.c \
msd_dir.h msd_dir.c tcexparg.c \
level-0 level-1 backup-specs testpad.c
all: tar rmt tar.info
tar: $(OBJS)
$(CC) $(LDFLAGS) -o $@ $(OBJS) $(LIBS)
rmt: rmt.c
$(CC) $(CFLAGS) $(LDFLAGS) -o $@ rmt.c
tar.info: tar.texinfo
makeinfo tar.texinfo
install: all
$(INSTALL) tar $(bindir)/$(binprefix)tar
-test ! -f rmt || $(INSTALL) rmt /etc/rmt
$(INSTALLDATA) $(srcdir)/tar.info* $(infodir)
$(OBJS): tar.h port.h testpad.h
regex.o buffer.o tar.o: regex.h
# getdate.y has 8 shift/reduce conflicts.
testpad.h: testpad
./testpad
testpad: testpad.o
$(CC) -o $@ testpad.o
TAGS: $(SRCS)
etags $(SRCS)
clean:
rm -f *.o tar rmt testpad testpad.h core
distclean: clean
rm -f TAGS Makefile config.status
realclean: distclean
rm -f tar.info*
shar: $(SRCS) $(AUX)
shar $(SRCS) $(AUX) | compress \
> tar-`sed -e '/version_string/!d' \
-e 's/[^0-9.]*\([0-9.]*\).*/\1/' \
-e q
version.c`.shar.Z
dist: $(SRCS) $(AUX)
echo tar-`sed \
-e '/version_string/!d' \
-e 's/[^0-9.]*\([0-9.]*\).*/\1/' \
-e q
version.c` > .fname
-rm -rf `cat .fname`
mkdir `cat .fname`
ln $(SRCS) $(AUX) `cat .fname`
-rm -rf `cat .fname` .fname
tar chZf `cat .fname`.tar.Z `cat .fname`
tar.zoo: $(SRCS) $(AUX)
-rm -rf tmp.dir
-mkdir tmp.dir
-rm tar.zoo
for X in $(SRCS) $(AUX) ; do \
echo $$X ; \
sed 's/$$/^M/' $$X \
> tmp.dir/$$X ; done
cd tmp.dir ; zoo aM ../tar.zoo *
-rm -rf tmp.dir
Index of Concepts
http://www.viper.pe.kr/docs/make-ko/make-ko_18.html
Index of Functions, Variables, & Directives
http://www.viper.pe.kr/docs/make-ko/make-ko_19.html
'Computer_language > Linux' 카테고리의 다른 글
| 리눅스 커널 스터디 참고자료 (0) | 2009.01.12 |
|---|---|
| 초보자를 위한 리눅스 커널의 메모리 관리 (0) | 2009.01.12 |
| MAKE를 이용한 프로젝트 관리 (Managing Projects with make) (0) | 2009.01.12 |
| 우분투 사용 총집합서 (0) | 2009.01.12 |
| 우분투에서 수도 (sudo) 사용자 추가방법, sudoers (0) | 2009.01.12 |
하나의 프로젝트에서 여러 파일을 다루고 다른 사람들과 함께 작업해 나가는 것은 개발자에게는 당연한 과정이며 꼭 필요한 부분이다. 그런 점에서 make를 사용하는 방법을 배우는 것은 상당히 중요한 일이라 할 수 있다.
make는 명령을 생성하는 유틸리티이다. 이들 명령은 주로 소프트웨어 개발 프로젝트를 수행하면서 작성되는 여러 파일들을 관리하는 것과 관련이 있다. 여기서 말하는 '파일 관리'란 상태를 보고하고 임시 파일을 제거하는데서부터 복잡한 프로그램 그룹의 최종 실행 파일을 만드는데 이르기까지 일련의 작업을 가리킨다.
콜론(:)을 포함하는 종속행과 탭 문자로 시작하는 하나 이상의 명령 행이 있다. 종속행에서 콜론 왼쪽은 target(program)이며, 콜론 오른쪽은 target의 필요 항목(prerequisite)이다. 탭 문자로 시작하는 명령 행은 필요 항목을 가지고 target을 작성하는 방법을 제시한다.
file.o : file.c --> 종속행(target : dependencies) (프로그램 : 필요 항목)
cc -c file.c --> 명령행(필요 항목을 가지고 target을 작성하는 방법을 제시)
탭 문자
make에서 가장 중요한 구문 규칙은 모든 명령들은 탭 문자로 시작한다는 것이다.
긴 행
행이 길어질 경우, 끝에 역슬래시(\)를 추가하여 계속 이어갈 수 있다. 역슬래시 뒤에는 어떤 여백 문자도 두어서는 안된다. 행을 계속 이어가기 위해 역슬래시를 사용하는 경우, make는 이를 하나의 공백 문자로 치환한다.
변수(매크로) 정의
변수(variable)란 텍스트 문자열(변수 값)을 표현하기 위해서 makefile에 정의된 이름이다. make의 어떤 버전에서는 변수를 매크로(macro)라고 부른다. 변수 정의는 등호를 포함하는 하나의 문장(행)이다. 문자열은 작은 따옴표('')나 큰 따옴표("")로 구분해서는 안된다. 변수 이름은 대소문자를 구분하므로 'foo', 'FOO', 'Foo'는 모두 서로 다른 변수가 된다. 변수 값 앞에 있는 공백은 변수 할당에서 무시된다. 변수 이름에 대해서 대문자 알파뱃을 사용하는 것이 전통적이지만 makefile 안에서 내부적인 목적으로 사용되는 변수 이름은 소문자 알파벳을 사용한다.
name = text string
변수를 참조할 때, 즉 make가 변수를 그 정의로 치환토록 할 때는 변수를 괄호(())나 중괄호({})로 둘러싸고, 그 앞에 달러 표시($)를 붙인다. $의 특별한 의미 때문에 단일 달러 기호의 효과를 가지기 위해서는 반드시 '$$'를 써야 한다.
$(name) 또는 ${name}
문자 하나로 이루어진 변수 이름에는 괄호나 중괄호를 사용할 필요가 없다.
A = XYZ
$A와 $(A) 그리고 ${A}는 모두 동일하다.
변수를 정의하지 않고 참조할 경우, make는 그것을 널 문자열로 치환한다. 따라서 정의하지 않은 변수를 사용해도 오류 메세지는 생기지 않는다. 변수는 반드시 사용할 항목보다 먼저 정의해야 한다.
다양한 소스에서, 한 변수에 서로 다른 정의를 내린 경우, 다음과 같은 우선 순위를 매겨 사용한다.
1. make 명령 입력시 make 명령 다음에 입력한 변수
2. 기술 파일의 변수 정의
3. 현재 셸 환경 변수
4. make의 내부(기본) 정의
변수의 특징
= 다른 변수에 대해 재귀적으로 확장
:= 단순 확장
+= 기존 변수에 값 추가
컴파일에 필요한 경로는 변수로 설정할 수 있다. 이를 통해 설치가 변경되더라도 쉽게 수정할 수 있다. 변수에는 두 가지 종류가 있다. 재귀적으로 확장되는 변수(Recursively expanded variable)와 간단히 확장되는 변수(Simply expanded variable)가 그것이다. 이 두 변수는 그것이 확장될 때 무엇을 하는가와 정의된 방법에 따라 구분된다.
재귀적으로 확장되는 변수(Recursively expanded variables)
재귀적으로 확장되는 변수는 이름과 값 사이에 '='를 사용하고 변수가 필요할 때 그 값이 결정된다. 이 변수는 재귀적으로 정의 될 수 없다. 왜냐하면 무한 루프에 빠지게 되기 때문이다. 이 변수가 다른 변수에 대한 참조를 담고 있다면 이런 참조는 그 변수가 대입될 때마다 확장된다. 이것이 일어날 때 이것을 recursive expansion이라고 부른다.
● OK: class_example_d = $(class_d)/example
(정의문에서 다른 변수를 참조한 경우)
● Not OK: class_d = $(class_d)/example
(재귀적 정의: 정의문에서 자신을 참조한 경우)
예를 들어,
foo = $(bar)
bar = $(ugh)
ugh = Huh?
all :
@echo $(foo)
이것은 'Huh?'를 에코한다: '$(foo)'는 '$(bar)'로 확장된다. 그리고 이것은 '$(ugh)'로 확장된다.
이것의 장점은 다음과 같다:
CFLAGS = $(include_dirs) -O
include_dirs = -lfoo -lbar
이것은 'CFLAGS'가 명령행에서 의도된대로 '-lfoo -lbar -O'로 확장될 것이다. 그러나 가장 큰 단점은 변수의 마지막에 무언가를 덧 붙일 수 없다는 것이다. 다음과 같이:
CFLAGS = $(CFLAGS) -O
이것은 변수 확장 과정에서 무한 루프를 발생시킨다(실제로 make는 무한 루프를 검출하고 에러를 보고한다).
단순하게 확장되는 변수(Simply expanded variables)
단순하게 확장되는 변수는 이름과 값 사이에 ':='를 사용해서 정의하고 make가 이 변수를 만날 때 바로 값이 평가된다. 즉, 변수가 정의될 때 다른 변수와 함수에 대한 참조를 확장하면서 단 한번만 스캔된다. 재귀적 정의도 가능하며, 이때 오른쪽에 있는 변수 값은 이 변수의 이전 값이 된다. 단순하게 확장되는 변수는 GNU make의 고유한 기능이며 다른 버전의 make에는 존재하지 않을 수도 있다.
● OK: class_example_d := $(class_d)/example
● OK: class := $(class)/example
(이전에 class가 정의되어 있다면 OK)
예를 들어,
x := foo
y := $(x) bar
x := later
all :
@echo $(y)
@echo $(x)
는 다음과 같다:
y := foo bar
x := later
단순하게 확장된 변수가 참조될 때 그것의 값은 있는 그대로 대입된다. 이것은 일반적으로 복잡한 makefile 프로그래밍을 좀 더 예측 가능하도록 만든다.
조건 변수 할당 연산자(Conditional variable assignment operator)
변수가 아직 정의되지 않았을 경우에만 효력을 가진다.
FOO ?= bar
다음과 정확하게 동일하다:
ifeq ($(origin FOO), undefined)
FOO = bar
else
endif
변수에 텍스트를 덧 붙이기
이미 정의된 변수의 값에다 텍스트를 추가할 때, 다음과 같이 '+='을 사용한다.
object += another.o
이것은 objects 변수의 값을 취해서 텍스트 'another.o'를 그것에 더한다(앞에 하나의 공백을 붙인다). 그래서:
objects = main.o foo.o bar.o utils.o
objects += another.o
이것은 objects를 'main.o foo.o bar.o utils.o another.o'로 설정한다.
'+='을 사용하는 것은 다음과 비슷하다:
objects = main.o foo.o bar.o utils.o
objects := $(objects) another.o
변수 대입 참조(Substitution References)
대입 참조는 한 변수의 값을 지정하는 다른 값으로 대입한다. '$(var:a=b)' (또는 '${var:a=b}' 형식이며, 이것의 의미는 변수 var의 값을 취해서 한 단어의 뒤에 있는 각각의 a를 각각의 b로 교체하고 결과 문자열을 대입한다는 것을 의미한다.
"한 단어의 뒤에 있는"이라고 말할 때, a가 대체되기 위해서는 이것이 공백 문자가 뒤에 있도록 또는 그 값이 마지막에 있도록 나타나야 한다는 것을 의미한다. 그 값안에서 다른 위치에 있는 a는 변경되지 않을 것이다.
예를 들어:
foo := a.o b.o c.o
bar := $(foo:.o=.c)
이것은 'bar'를 'a.c b.c c.c'로 설정한다.
아래는 또한 같은 결과를 나타낸다.
foo := a.o b.o c.o
bar := $(foo:%.o=%.c)
이것은 'bar'를 'a.c b.c c.c'로 설정한다.
변수 문자열 치환
SRCS = def.c redraw.c calc.c
FINAL_OBJS = ${SRCS:.c=.o}
DEBUG_OBJS = ${SRCS:.c=_dbg.o}
위 예제의 경우, make는 {SRCS}를 평가하고 콜론 바로 뒤에 오는 문자열을 찾은 다음, 등호 기호 뒤의 문자열로 치환한다. 이 기능을 이용하면 마지막에 첨부된 문자만 다른 여러 파일로 이뤄진 그룹을 쉽게 관리할 수 있다. 따라서 나중에 소스 파일을 추가하거나 제거해도, SRCS 변수 정의만 바꿔주면 된다.
${FINAL_OBJS} --> def.o redraw.o calc.o
${DEBUG_OBJS} --> def_dbg.o redraw_dbg.o calc_dbg.o
단순히 ${DEBUG_OBJS}의 항목들만 이용하여 실행 파일을 작성할 경우, 항목을 다음과 같이 사용하면 된다.
plot_debug: ${DEBUG_OBJS}
${CC} -o plot_debug ${DEBUG_OBJS}
문자열 치환은 매우 엄격하게 제한된다. 즉 변수의 마지막 부분이나 공백 문자 바로 앞까지만 적용된다.
LETTER = xyz xyzabc abcxyz
...
echo ${LETTERS:xyz=DEF}
--> DEF xyzabc abcDEF
이는 abc가 xyz의 존재를 숨기기 때문이다.
치환에서 두 번째 문자열은 널 문자열이 될 수 있지만, 첫 번째 문자열은 불가능하다.
SOURCES = src1.c src2.c glob.c
EXEC = $(SOURECS:.c=)
echo ${EXEC}
--> src1 src2 glob
필요 항목과 target용 내부 변수
$@ 현재 target의 전체 이름(명령행에서만). 일반 기술 파일 항목과 확장자 규칙에서 사용할 수 있다.
OBJS = basic.o prompt.o
plot_prompt : basic.o prompt.o
cc -o $@ ${OBJS} --> cc -o plot_prompt basic.o prompt.o
주의! cc 명령은 반드시 프로그램을 구성하는 모든 오브젝트 모듈을 링크해야 한다.
위 $@ 예제에서 ${OBJS} 대신 $?를 사용하면 안된다.
$?는 target보다 나중에 수정된 필요한 파일들만 표시할 뿐이다.
$? 현재 target보다 최근에 변경된 필요 항목들의 리스트(명령행에서만). 일반 기술 파일 항목에서만 사용할 수 있다.
libops : interact.o sched.o gen.o
ar r $@ $? --> ar r libops sched.o (나중에 sched.o 만 갱신되었다고 가정)
$$@ 현재 target의 이름(종속행의 필요 항목에서만). 하나의 소스 파일을 갖는 실행 파일들의 수가 많을 때
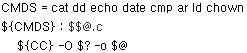 --> cc -O dd.c -o dd (나중에 dd.c 만 갱신되었다고 가정)
--> cc -O dd.c -o dd (나중에 dd.c 만 갱신되었다고 가정)
$< 현재 target보다 최근에 변경된 필요 항목의 전체 이름. 확장자 규칙과 .DEFAULT 항목에서만 사용될 수 있다는 점을 제외하면 $?와 유사하다.
$* 현재 target보다 최근에 변경된 필요 항목의 확장자를 제외한 이름. 확장자 규칙에서만 사용할 수 있다.
$% 현재 target이 라이브러리 모듈일 때 .o 파일에 대응되는 이름. 일반 기술 파일 항목과 확장자 규칙에서 사용할 수 있다.
$^ 모든 필요 항목의 리스트. 디렉토리 이름을 포함하고 이들 사이는 공백으로 구분된다. 일반 기술 파일 항목에서 사용할 수 있다.
또한 한 문자로 구성된 변수의 구문 규칙을 적용할 수도 있다. 즉, $@을 $(@)나 ${@}으로 쓸 수 있는 것이다.
확장자 규칙
미리 정의해 놓은 일반화한 기술 파일 항목. 필요 항목이 몇몇 확장자 가운데 하나를 갖거나, 사용자가 제공한 그 어떤 명시적인 명령도 가지고 있지 않을 경우, make는 적절한 확장자 규칙을 찾게 된다. 즉, program이 만들어지기 전에 필요 항목 파일 가운데 어떤 파일이 만들어져야 하는지 확인한다.
.SUFFIXES : .o .c .s
.SUFFIXES 행은 make가 중요하게 여길 확장자를 나타낸다.
.c :
$(CC) $(CFLAGS) $(LDFLAGS) $< -o $@
.c 확장자의 파일로부터 널 확장자의 파일(실행 프로그램)을 만드는 방법을 설명한다.(널 확장자가 .c와 콜론 사이에 있다고 생각) 이 규칙은 하나의 소스 파일에서 작성할 때 오브젝트 파일을 다루지 않도록 해준다.
.c.o :
$(CC) $(CFLAGS) -c $<
이 규칙은 .c에서 .o파일을 만드는 방법을 설명하고 있다.
OBJS = main.o iodat.o dorun.o lo.o
LIB = /usr/proj/lib/crtn.a
program : ${OBJS} ${LIB}
${CC} -o $@ ${OBJS} ${LIB}
$ make program --> cc -o program main.o iodat.o dorun.o io.o /usr/proj/crtn.a
어떤 확장자에 대해 확장자 규칙이 정의되어 있더라도 .SUFFIXES 리스트에도 함께 정의되어야 효력이 있다. make는 .SUFFIXES 리스트의 확장자 순서에 따라 파일을 검색한다.
make는 현재의 작성에서 사용한 모든 변수와 확장자 규칙, 그리고 target을 출력하는 유용한 -p 옵션을 제공한다.
명령옵션
CFLAGS와 ASFLAGS 변수는 명령에 대한 플래그 옵션을 전달한다.
make program CFLAGS=-g --> cc -g -c main.c
make의 명령 행에서 단일 변수에 여러 옵션들을 주려면, 전체 정의에 큰따옴표("")를 쳐주면 된다.
make program "CFLAGS=-g -DTRACE" --> cc -g -DTRACE main.c
기본으로 정의된 CFLAGS는 무효화한다.
주의! 기술 파일 항목에서 라이브러리 옵션들을 변경한 다음, target들에 대해 make를 실행하면, 최신 버전의 target들이 이미 존재할 경우, make는 그것을 다시 작성하지는 않는다. make는 무엇보다도 파일 이름과 변경 시간에서만 정보를 얻는다.
라이브러리
각 오브젝트 파일을 갱신한다.
libops : interact.o sched.o gen.o
ar r $@ $?
사용자들이 라이브러리 내에서 각 파일을 지정할 수 있다.
libops(interact.o), ${LIB}(interact.o)
괄호를 중복 사용하여 라이브러리 내의 특정 모듈을 참조할 수 있다.
libops((_parse))
구문 내에서는 여백 문자를 사용해서는 안된다.
확장자 규칙은 또한 라이브러리를 다시 생성하는 것도 지원한다. 다음은 C 소스 파일이 변경되었을 때 라이브러리를 갱신하는 기본 규칙을 보여준다.
.c.a :
$(CC) -c $(CFLAGS) $<
ar rv $@ $*.o
rm -f $*.o
특정 파일에 의존 관계들을 지정해주기만 하면 된다.
prog : libops(interact.o) libops(sched.o) prog_call.o
${CC} -o $@ prog_call.o libops
파일을 정확히 알지 못하더라도 다음과 같이 모듈을 지정할 수 있다.
prog : libops((_parse)) libops((_waitloop)) prog_call.o
${CC} -o $@ prog_call.o libops
이처럼 모듈을 지정하는 것은 make에 해당 파일을 가리켜 줄 뿐, 해당 모듈이 변경되었는지 여부를 점검토록 해주지는 않는다. interact.c 내에 있는 어떤 모듈 하나라도 바뀐 경우, _parse에만 관심이 있더라도 make는 libops(interact.o) 파일 전체를 다시 작성해야 한다.
libops가 마지막으로 작성된 이후 interact.c가 변경되었다고 가정해보자. 처음 세 명령은 .c.a 규칙에 의해 실행되었으며, 마지막 명령은 기술 파일에 명시되어 있다(ar 명령 다음 줄은 ar 명령이 라이브러리에서 interact.o를 치환할 때 표시하는 메세지이다).
$ make prog
cc -c -O interact.c
ar rv libops interact.o
r - interact.o
rm -f interact.o
cc -o prog prog_call.o libops
.c.a 규칙에 따라 libops를 작성하는 동안, make는 처음에는 내부 변수들을 아래와 같이 설정한다.
$@ = libops
$< = interact.c
$* = interact
공통된 정의(문장)의 사용
대형 프로젝트에서 기술 파일이 여러 군데서 사용되면 프로젝트 팀에서는 변수 정의와 확장자 규칙을 한 곳에 모으는 것에 대해 생각해 보아야만 한다. 이것을 지원하기 위해 make는 include문을 제공한다.
include file
여기서 include라는 단어는 반드시 줄의 처음에서 시작해야 하며 다음에 공백 문자나 탭이 따라와야 한다. 'file'의 모든 행을 현재의 기술 파일로 옮겨 적는 것과 동일하다.
include 파일에 의존 항목 행을 둔다면, 변수를 참조하는 의존 항목 행 이전에 해당 변수가 정의되어 있어야만 한다. 정의는 다음 중 하나의 위치에 있어야만 한다.
1. include 파일 내에 의존 항목 행 이전
2. 사용자 기술 파일에서 include문 이전
3. make 명령 행
4. 사용자의 환경 변수
에코
일반적으로 make는 각 명령 라인이 실행되기 전에 디스플레이한다. 이것을 echoing이라고 부른다.
어떤 라인이 '@'으로 시작할 때, 그 라인의 에코는 나타나지 않는다. '@'는 명령이 셸에 전달되기 전에 버려진다. Makefile을 통해서 진행되는 상황을 표시하기 위해서 echo와 같은 명령을 사용한다.
@echo About to make distribution files
make는 '-n' 또는 '--just-print' 플래그를 받으면 실행없이 에코만 한다. 이런 경우에는 '@'으로 시작하는 명령들 조차도 출력된다. make는 '- s' 또는 '-- silent' 플래그를 받으면 모든 명령이 마치 '@'으로 시작하는 것처럼 모든 에코를 금지시킨다.
와일드 카드
하나의 파일 이름을 wildcard character를 사용해서 많은 파일을 지정할 수 있다. make에서 와일드 카드 문자는 '*', '?', '[...]'이다. 예를 들어, '*.c'는 이름이 '.c'로 끝나는 모든 파일(현재 작업 디렉토리 안에서)의 리스트를 지정한다.
와일드 카드 문자의 특별한 용도는 그 앞에 역슬래시를 붙임으로써 없어진다.
다음은 의도한 바대로 작동하지 않는 와일드 카드 확장을 사용하는 간단한 예제이다. 실행 파일 'foo'가 모든 오브젝트 파일들로 부터 만들어지도록 하기 위해 다음과 같이 작성했다고 가정하자:
objects = *.o
foo : $(objects)
cc -o foo $(CFLAGS) $(objects)
objects의 값은 실제 문자열 '*.o'이다. 와일드 카드 확장은 'foo'를 위한 규칙에서 일어난다. 그래서 각 현존하는 '.o' 파일은 'foo'의 필요 항목이 되고 필요하면 재컴파일 될 것이다. 그런데 모든 '.o' 파일이 지워져 버렸다면 어떻게 될 것인가. 와일드 카드가 어떤 파일과도 매치되지 않으면 이것은 있는 그대로 남게 된다. 그래서 'foo'는 이상한 이름의 파일 '*.o'에 의존하게 될 것이다. 이런 파일은 존재하지 않을 것이기 때문에 make는 '*.o'를 만드는 방법을 알 수가 없다는 에러를 낼 것이다. 이것은 의도하는 바가 아니다.
$(wildcard pattern...)
이 문자열은 makefile 안의 어떤 곳에서도 사용된다. 주어진 파일 이름 패턴들 중에서 하나와 매치되는 현존하는 파일 이름들을 공백으로 분리된 리스트로 만들어 대체한다. 어떤 파일 이름도 패턴과 매치되는 것이 없으면 그 패턴은 wildcard 함수의 결과로부터 제거된다.
wildcard 함수의 한가지 사용법은 한 디렉토리에 있는 모든 C 소스 파일들의 리스트를 획득하는 것이다. 다음과 같이:
$(wildcard *.c)
C 소스 파일들의 리스트를 가지고 `.c' 접미사를 `.o'로 변경해서 오브젝트 파일들의 리스트로 변경할 수 있다. 다음과 같이:
$(patsubst %.c, %.o, $(wildcard *.c))
그래서 한 디렉토리에 있는 모든 C 파일을 컴파일하고 이들을 모두 모아서 링크하려고 하는 makefile은 다음과 같이 작성될 수 있다:
objects := $(patsubst %.c, %.o, $(wildcard *.c))
foo : $(objects)
cc -o foo $(objects)
텍스트 변환을 위한 함수(Functions for Transforming Text)
$(subst from, to, text)
text에 대해서 from을 to로 바꾼다. 예를 들어서
$(subst ee, EE, feet on the street)
의 결과는 'fEEt on the strEEt'이다.
$(patsubst pattern, replacement, text)
text 안에서 공백 문자로 분리된 단어 중에서 pattern과 매치되는 단어를 찾아 그것들을 replacement로 변경한다.
여기서 pattern은 와일드 카드 역활을 하는 '%'를 가질 수 있는데, 이것은 어떤 단어 내에 있는 임의 개수의 문자들과 매치된다.
replacement도 역시 '%'를 가질 수 있는데 '%'는 pattern 안에서 '%'와 매치된 텍스트로 대치된다.
$(findstring find, in)
in에서 find를 찾아 있다면 값은 find가 되고, 없다면 빈 값이 된다. 이 함수를 조건에서 사용하면 주어진 문자열 안에서 특정 문자열의 존재 여부를 검사할 수 있다. 그래서 다음과 같은 두 예제들은:
$(findstring a, a b c)
$(findstring a, b c)
'a'와 ''(빈 문자열) 각각을 만든다.
$(filter pattern...,text)
pattern 단어들 중의 임의의 것과 일치하지 않는, text 내의 공백 문자로 분리된 단어들을 모두 제거하고 일치하는 단어들만을 리턴한다. 패턴은, 위의 patsubst 함수에서 사용된 패턴과 마찬가지로, `%'을 사용하여 작성된다. filter 함수는 한 변수 안에서 (파일 이름과 같은) 다른 타입의 문자열들을 분리 제거하는데 사용될 수 있다. 예를 들어서:
sources := foo.c bar.c baz.s ugh.h
foo: $(sources)
cc $(filter %.c %.s,$(sources)) -o foo
는 `foo'가 `foo.c', `bar.c', `baz.s' 그리고 `ugh.h' 에 의존하지만 `foo.c', `bar.c' 그리고 `baz.s' 만이 명령안에서 컴파일러에 대해 지정되어야 한다는 것을 말한다.
$(origin variable)
variable은 질의하고 있는 변수의 이름으로 그 변수를 참조하는 것은 아니다. 그러므로 '$'나 괄호를 쓰지 않는다. 이 함수의 결과는 변수 variable이 정의된 방법을 말하는 문자열을 가진다:
'undefined'
변수 variable이 전혀 정의된 바가 없다면 이 값을 가진다.
'default'
변수 variable이 CC나 기타 등등처럼 디폴트 정의를 갖고 있다면 이 값을 가진다.
'environment'
variable이 환경 변수로써 정의된 것이고 '-e' 옵션이 켜진 것이 아니라면 이 값을 가진다.
'environment override'
variable가 환경 변수로 정의되었고 '-e' 옵션이 켜졌다면 이 값을 가진다.
'file'
variable가 makefile에서 정의된 것이라면 이 값을 가진다.
'command line'
variable가 명령행에서 정의된 것이라면 이 값을 가진다.
'override'
variable가 override 지시어로 makefile에서 정의된 것이라면 이 값을 가진다.
'automatic'
variable가 각 규칙의 명령의 실행에 대해서 정의된 자동 변수라면 이 값을 가진다.
헤더 파일(필요 항목을 자동으로 생성하기)
make는 숨겨진 의존 관계를 살펴보기 위해 파일 내부를 들여다 볼 수 없다. 따라서 어떠한 #include 지시자가 파일 내에 있는지 알지 못하며, 헤더 파일이 변경된 것을 확인하여 오브젝트 파일을 다시 작성할 수 없다. 이런 문제를 해결하기 위해 대부분의 기술 파일은 의존 관계를 직접 지정한다.
main.o: defs.h
make가 'defs.h'가 변할 때마다 'main.o'를 반드시 다시 만들어야 한다는 것을 알게 하기 위해 이 규칙이 필요하다. 어떤 커다란 프로그램에 대해서는 makefile 안에 그런 규칙 수십 개를 작성해야 할 것이다. 그리고 #include를 더하거나 제거할 때마다 makefile을 조심스럽게 업데이트 해야 한다.
대부분의 현대 C 컴파일러는 소스 파일에서 #include를 찾아 기술 파일에 포함하기 적합한 의존 파일 리스트를 만들어 내는 '-M' 옵션을 포함하고 있다. 예를 들어서 다음 명령은:
cc -M main.c
다음과 같은 출력을 생성한다:
main.o: main.c defs.h
이것은 .o가 종속하고 있는 모든 소스와 헤더 파일을 .o에 종속하도록 만든다. GNU C 컴파일러는 '-M' 플래그 대신 '-MM'을 사용하여 시스템 헤더 파일에 대해서는 종속물을 생략하도록 한다. 의존 파일 리스트를 만들었다면 그것을 모두 읽어 들이기 위해 include 지시어를 사용한다. 예를 들어:
include depend
.c.o :
$(CC) $(CFLAGS) -c $<
depend : Makefile
$(CC) -MM $(CFLAGS) $(wildcard *.c) > $@
명령에서 에러(Errors in Commands)
각 쉘 명령이 리턴한 후, make는 그것의 종료 상태 값을 조사한다. 그 명령이 성공적으로 종료하면 다음 명령 라인이 새로운 쉘에서 실행된다; 마지막 명령 라인이 종료된 후 그 규칙은 종료한다.
에러가 있으면(종료 상태 값이 0이 아니면), make는 현재 규칙을 그리고 아마도 모든 규칙들을, 포기한다.
때때로 어떤 명령의 실패가 문제를 가리키는 것은 아니다. 예를 들어서 mkdir 명령을 사용해서 어떤 디렉토리의 존재 유무를 검사할 수도 있다. 그런 디렉토리가 이미 존재한다면 mkdir은 에러를 보고할 것이다. 그러나 여러분은 아마도 make가 그것을 신경쓰지 않고 계속하기를 원할 것이다.
명령 라인에서 에러들을 무시하기 위해서 그 라인 텍스트의 시작부분(초기 탭 문자 뒤에)에 `-' 하나를 넣는다. `-'는 명령이 실행을 위해서 쉘로 전달되기 전에 무시된다.
예를 들어서,
clean:
-rm -f *.o
이것은 rm이 어떤 파일을 제거할 수 없다하더라도 계속하도록 한다.
여러분이 make를 `-i'나 `--ignore-errors' 플래그를 써서 실행할 때 에러들이 모든 규칙의 모든 명령들에서 무시된다. makefile에 있는 특수 타겟 .IGNORE에 대한 규칙은, 종속물들이 없을 때, 동일한 효과를 낸다. 에러를 무시하는 이런 방법들은 `-'가 좀 더 유연하기 때문에 구식이 되버렸다.
에러들이 무시되어야 할 때, `-'나 `-i' 플래그 때문에, make는 에러 리턴을 성공처럼 취급한다. 단, 여러분에 그 명령이 exit한 상태 코드를 말해주는 메시지를 출력하고 에러가 무시되었다는 것을 말하는 것외는 그렇다.
출처: Managing Projects with make, O'REILLY 발췌
http://www.viper.pe.kr/docs/make-ko/make-ko_toc.html
%: force
@$(MAKE) -f Makefile $@
force: ;
이것이 작동하는 방법은 패턴 규칙이 `%'와 같은 패턴을 가지고 있어서 임의의 타겟 어떤 것이든 매치된다는 것이다. 이 규칙은 `force'라는 종속물을 가지고 있도록 지정하고 있으며 이것은 타겟 파일이 이미 존재하더라도 명령들이 실행되도록 보장하기 위한 것이다. 우리는 make가 `force' 타겟을 빌드하기 위한 묵시적 규칙을 찾지 못하도록 금지하는, 빈 명령들을 주었다---그렇게 하지 않으면 `force' 자신에다 동일한 match-anything 규칙을 적용해서 종속물 루프를 만들것이다.
'Computer_language > Linux' 카테고리의 다른 글
| 초보자를 위한 리눅스 커널의 메모리 관리 (0) | 2009.01.12 |
|---|---|
| GNU Make: 재컴파일을 지휘하는 프로그램(A Program for Directing Recompilation) (0) | 2009.01.12 |
| 우분투 사용 총집합서 (0) | 2009.01.12 |
| 우분투에서 수도 (sudo) 사용자 추가방법, sudoers (0) | 2009.01.12 |
| 우분투에 메신저를 설치하다 (네이트온,MSN 등) (0) | 2009.01.12 |
[공식사이트]
http://www.ubuntu.com/
[한글사이트]
http://www.ubuntu.or.kr/wiki.php
[버젼고르기]
데스크탑: 원도우처럼 사용해 보고싶은분
서버:리눅스 서버 운영이나 공부 하실분
우분투 패키징 안내서
[다운로드]
공식사이트 : http://www.ubuntu.com/getubuntu/download
우분투 새로운 미러사이트.
우분투(ubuntu) CD
우분투 CD 신청 노하우.
데스크탑버전:공식사이트 : http://www.ubuntu.com/getubuntu/download
서버버젼:공식사이트 : http://www.ubuntu.com/getubuntu/download
onload_post += "var blog_extend_6=new blogInstance.WebExtend('blog_extend_6',{thumbImage : [['http://blogthumb3.naver.net/data20/2007/4/17/258/1_1-uranusk.jpg','http://blog.naver.com/uranusk?Redirect=Log&logNo=140036844717'], ['http://blogthumb3.naver.net/data17/2007/4/17/82/2_1-uranusk.jpg','http://blog.naver.com/uranusk?Redirect=Log&logNo=140036844717'], ['http://blogthumb3.naver.net/data17/2007/4/17/275/3_1-uranusk.jpg','http://blog.naver.com/uranusk?Redirect=Log&logNo=140036844717'], ['http://blogthumb3.naver.net/data19/2007/4/17/293/4_1-uranusk.jpg','http://blog.naver.com/uranusk?Redirect=Log&logNo=140036844717'], ['http://blogthumb3.naver.net/data20/2007/4/17/143/8_1-uranusk.jpg','http://blog.naver.com/uranusk?Redirect=Log&logNo=140036844717'] ]},blog_extend_CR_6,'bcl','bcr');"; function blog_extend_CR_6(){ var e = arguments[0]; e.target="_blank"; return goCR(e, 'rd', 'u='+urlencode('http://blog.naver.com/uranusk?Redirect=Log&logNo=140036844717')+'&a=blg.img&r=6&i=uranusk.140036844717'); }
[주의사항]
우분투 live cd로 Win XP 데이타 백업
Ubuntu is available for PC, 64-Bit and Mac architectures.
CDs require at least 256 MB of RAM.
Install requires at least 2 GB of disk space.
[설치하기]
설치가이드 : 우분투 대퍼 설치 가이드
더블 클릭으로 설치하는 유분투 리눅스
우분투 서버 설치
우분투 데스크탑 설치기
[Ubuntu] Hoary - 우분투 리눅스 설치 가이드
우분투 리눅스 설치 가이드
하드 하나에 우분투 ubuntu 리눅스 linux와 윈도우즈 windows 서버 같이 깔기
우분투 설치하기(그림 첨부)
kt vdsl+ati X850 에서 우분투 제대로 설치하기
컴팩v3026au에 우분투설치
우분투에서 Grub 부트로더 설치 실패기..ㅡㅡ;;;;
[설치후]
onload_post += "var blog_extend_10=new blogInstance.WebExtend('blog_extend_10',{thumbImage : [['http://blogthumb3.naver.net/data20/2007/1/7/115/1.jpg-psknoid4u.jpg','http://blog.naver.com/psknoid4u?Redirect=Log&logNo=10012721131'] ]},blog_extend_CR_10,'bcl','bcr');"; function blog_extend_CR_10(){ var e = arguments[0]; e.target="_blank"; return goCR(e, 'rd', 'u='+urlencode('http://blog.naver.com/psknoid4u?Redirect=Log&logNo=10012721131')+'&a=blg.img&r=10&i=psknoid4u.10012721131'); }
오늘의 삽질 "우분투 & XGL & Veryl & Etc..."
usb로 우분투 설치 성공기.
우분투 CD로 부팅
[jwmx]윈도즈 기반의 우분투 사용 및 설치기
우분투와 Vista..
우분투 설치 한후 해야할 것들..
우분투 (Ubuntu) 사용하기
[펌] 데스크탑 OS로의 우분투 간단 사용기
윈도우쟁이가 리눅스 우분투 1달 반 사용기를 남겨봅니다.
우분투 사용기 1 - 멀티 부팅~~!!
우분투 테마를 바꿔보았습니다..
우분투 쓰면서 느낀 장, 단점들
우분투 쓸때 제일 짜증나는 것!
우분투(Ubuntu) 6.10 "Edgy" 베타의 간단한 사용기
우분투 대퍼 사용소감!!!
[명령어]
우분투 유용한 명령어 모음
서버버젼 설치 하신분 (초보용) 명령어
종료 명령어
$sudo init 0
재부팅
$sudo init 6
[업그레이드]
우분투 7.04 업그레이드
[설정하기]
유분투(Ubuntu)리눅스 root유저로 로그인하기..
초급 - 우분투와 윈도우의 삼바를 이용한 폴더공유
우분투 MIDI 세팅
[펌] 우분투에서 Agere Systems의 ET131x 랜카드 인식 시키기
우분투에서 한영키사용하기
우분투 서버 - 네트워크 설정
우분투에서 RPM 패키지 설치하기.
초급 - 우분투 Raid 잡기
우분투 feisty 한글 글꼴 문제
우분투에서 사운드가 안나올 때
우분투 EUC-KR 설치하기
우분투 breezy 설치.
우분투(ubuntu)한영키 설정
우분투 내장랜카드(Marvell Yucon) 설치하기
우분투에서 jre 환경 바꿔주기.
초급 - 우분투 Beryl + Nvidia
우분투 사용시.... 기본 설정들~
우분투 소스 리스트
[펌]우분투에 한글 입력기 설치 리눅스
우분투에서 tftpd-hpa 설정
우분투에서의 한글설정과 바탕화면에 휴지통 등 나타내기
[펌] 우분투 완전 초보 기본설정법
[우분투] 윈도우 글꼴 사용하기
우분투X60 밝기 조절 Fn+Home, Fn+End
우분투에서 무선 인터넷 설정 밥법입니다..
우분투, ssh에서 한글 깨짐 문제 해결하기
[설치] VMware에 우분투 설치 후 VMware Tools 설치하기
우분투 한글 설정 (nabi)
우분투 캠 사용하기
우분투 공유 폴더(윈도우)
우분투 - 한글입력기 nabi 설치
우분투 엣지 SCIM 설정과 vim 깔기, 그리고 gcc 헤더파일 설치
우분투에서 nvidia의 twinview (dual monitor) 셋팅
[활용하기]
우분투에서 한글2005 설치하기
우분투에서 ipod 사용하기
우분투 7.04 3D Desktop 환경 구성 성공!
우분투 Edgy Eft 설치.
우분투에서 윈도우 접근하기
우분투에서 와콤 타블렛 사용하기
우분투 7.04 에 vmware-server 깔기..
우분투에 XGL을 이용한 Beryl 를 설치하기 위한 문서
우분투 (Ubuntu Feisty) 에서 escript 사용하기
우분투에서 MP3 듣기.......
우분투 서버 - DNS 구축 (bind 설치)
우분투 설치 및 타블렛 설정
리눅스(우분투 7.04) 에서 네이트온 설치하기...
우분투에 XGL을 이용한 Beryl 를 설치하기 위한 문서
[우분투] 동영상 감상하기
데비안 우분투 OS와 서버(APM) 설치
우분투 서버 - APM, FTP 설치 도우미
우분투 NFS 서버 설치
우분투 엣지 + nvidia-glx + 베릴
우분투 - root 권한 얻기
우분투 서버 - 호스트네임(hostname) 설정
[우분투] 읽기권한 주고 ntfs 시스템 mount 하기
비스타가 부럽잖은 우분투+XGL+Beryl 3총사
우분투에 포스트픽스(postfix) 설치
[펌]우분투, Apache+Tomcat+Mysql+php
우분투 네스팟 접속기(dapper drake)
우분투 부트로더 복구 방법
우분투에서 AVR 환경 구성하기... part 1.
우분투에서 동영상 코덱 설치
우분투에서 소스 컴파일 방법..
우분투에서 GRUB 부트로더가 지워졌을 때
우분투에서 SUN JAVA JVM 사용하기
우분투에서 방화벽(IPTABLES)설정을 통한 인터넷 공유
우분투 코덱 설치 프로그램
우분투(ubuntu) BIND - DNS 도메인 등록
우분투에서 telnetd 설치가 안될경우?
우분투 postgresql 설정 - ubuntu 5.10
'Computer_language > Linux' 카테고리의 다른 글
| GNU Make: 재컴파일을 지휘하는 프로그램(A Program for Directing Recompilation) (0) | 2009.01.12 |
|---|---|
| MAKE를 이용한 프로젝트 관리 (Managing Projects with make) (0) | 2009.01.12 |
| 우분투에서 수도 (sudo) 사용자 추가방법, sudoers (0) | 2009.01.12 |
| 우분투에 메신저를 설치하다 (네이트온,MSN 등) (0) | 2009.01.12 |
| swap 메모리를 설치후에도 설정할수 있나요? (0) | 2009.01.12 |
그러면 리눅스 박스를 2사람 이상이 공동으로 관리하고자 할 때 sudo 사용자를 추가해 줄 수 있는 방법은 무엇이 있을까? 리눅스 박스에서 일반사용자들의 경우 su 명령이나 sudo 명령을 거의 사용하지 않을 것이다. 따라서 이런 이유에서 수도사용자를 추가하는 방법이 몇가지 존재한다. 모로 가도 서울만 가면 된다는 말이 있듯이 해결방법은 다양한 듯 하다.
첫째, 우분투에서 사용자 추가시 새로 발급하는 계정(account)을 admin 그룹으로 넣어주는 것이다.
# sudo passwd user1
passwd:
위의 과정을 설명하면
-n : 새로운 계정을 추가하는 옵션
-d : 해당계정의 디렉토리를 만들어 주는 옵션
-G : 해당 그룹에 속하도록 하는 옵션
user1 : 발급하고자 하는 계정(account)
이렇게 하면 user1 계정은 sudo 명령을 root 권한으로 사용할 수 있게 된다.
둘째, 일반사용자를 추가한 후 /etc/group 파일을 편집하여 해당 계정 사용자의 구룹을 admin에 추가해 준다.
# sudo passwd user1
passwd :
# sudo vi /etc/group
...
(중략)
admin:x:115:isjang,user1
(중략)
....
:wq
admin 그룹의 id 는 115번이며 isjang은 우분투 설치시 생성해서 root 권한을 실행할 수 있는 이미 발급되어진 계정이다. user1 은 isjang옆에 코마(,) 로 추가해 준다.
그리고 나서 user1 으로 로긴하면 sudo 명령을 사용할 수 있게 된다.
셋째, 우분투 이외의 일반적인 리눅스 시스템에서 su 나 sudo 의 경우는 관리자 외의 일반계정 사용자들이 사용할 필요가 없는 것들이다. 그런데 그룹사용자 외에는 위 명령 자체를 실행하지 못하도록 하려면 해당 화일의 그룹을 wheel 로 변경한 다음 wheel 그룹에 사용자들을 넣어주고 그 외의 계정 사용자들은 명령어 접근 자체를 제한 시켜 시스템 보안을 높일 수 있다.
이것은 wheel 그룹을 생성하여 추가해 주는 방법인데 이때는 역시 해당되는 그룹을 추가해 넣기 위하여 visudo 명령어를 이용하여 /etc/sudoers 파일을 직접 편집하는 것이다. 이때 주의할 점은 편집시 조심해야 한다는 것이다. 잘못 편집하여 내용이 조금이라도 틀릴 경우가 발생하면 sudo를 아예 사용할 수 없는 불상사가 발생할 수 있을지도 모르기 때문이다. ^^;;
# visudo 하여 편집모드로 들어간 다음
맨 하단 부분에
%wheel ALL=(ALL) ALL 를 추가한 다음 빠져나온다.
# whoami
root
# chgrp wheel /bin/su /usr/bin/sudo // 만일 우분투에서 sudo 를 이용하여 이 행을 실행하면 setuid 가 사라지므로 root 비밀번호를 주지 않았을 경우에는 실행하면 안된다.
# chmod o-rwx /bin/su /usr/bin/sudo
# vi /etc/group
...
wheel:x:1001:user2,user3
...
:wq
# This file MUST be edited with the 'visudo' command as root.
#
# See the man page for details on how to write a sudoers file.
#
Defaults env_reset
# Host alias specification
# User alias specification
# Cmnd alias specification
# User privilege specification
root ALL=(ALL) ALL
# Uncomment to allow members of group sudo to not need a password
# (Note that later entries override this, so you might need to move
# it further down)
# %sudo ALL=NOPASSWD: ALL
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
혹시 우분투에서 위와 같이 세번 방법으로 구지 따라하다가 낭패를 보신 분들은 싱글모드로 부팅하여 root 비밀번호를 획득해야 하거나 root 비밀번호를 잃어버렸을 경우 최악의 경우 시스템을 재설치해야 할 수도 있다.
우분투 또는 리눅스에서 Grub 을 이용하여 멀티부팅을 할 경우 해당 리눅스라벨을 선택한 후 싱글모드로 부팅하기 위해서는
kernel 을 커서에 맞추고 다시 e 를 한번 더 누른다음
맨 끝줄에 single 을 타이핑 한 후 엔터키를 친다. 그리고 마지막으로
b 를 누르면 되는데 b 는 booting 의 약어다.
출처 - http://www.kernel-panic.org/wiki/GroupWheel
그룹 (Wheel)
휠그룹은 무엇을 위한 것인가? 대부분 오랫동안 사용되어오면서 모호한 표현이라 생각한다. 이것은 사용자 권한을 나누기 위해 사용된다. root, 휠그룹, 그밖의 사용자로 3개의 계층으로 분류되어 있다.
보통 휠그룹은 그에 속한 그룹 사용자들만 su root 를 사용할 수 있도록 하는 기능이다. FSF(자유소프트웨어 재단) 그룹은 이 원칙에 별로 따르지 않는데 왜냐하면 그것이 수학적 알고리즘이 아니기 때문이다.
사용자를 최소로 구분하는 것은 sudo 에 의한다. 가장 많은 sudo 권한을 위한 자격으로 휠그룹 멤버쉽이라 불리는 것이 있다.
역사적으로 말하면 그것은 초기 BSD중의 하나에서 시작되었다 생각한다.
휠그룹을 만들므로써 휠의 기능을 쉽게 다시 만들 수 있으며 그리고 su 와 sudo (둘다 setuid 프로그램이다.)를 wheel 그룹으로 만들고 나서 다른 사용자에 대해서는 사용권한을 제거한다.
# chgrp wheel /bin/su /bin/sudo
# chown o-rwx /bin/su /bin/sudo
물론 이것은 실제적으로 정상적인 사용자들에게 su와 sudo 를 사용할 수 없게 만든다. 문제는 서버에 어떤 정상적인 사용자들이 있는가이다.
'Computer_language > Linux' 카테고리의 다른 글
| MAKE를 이용한 프로젝트 관리 (Managing Projects with make) (0) | 2009.01.12 |
|---|---|
| 우분투 사용 총집합서 (0) | 2009.01.12 |
| 우분투에 메신저를 설치하다 (네이트온,MSN 등) (0) | 2009.01.12 |
| swap 메모리를 설치후에도 설정할수 있나요? (0) | 2009.01.12 |
| SSH 터널링 - putty의 plink 사용예esniper (0) | 2009.01.12 |
현재 내가 사용하고 있는 우분투 버젼은 8.04.1 (Hardy) 이므로 아래와 같이 메신저가 들어있는 소스가 들어 있는 링크를 넣어주어야 한다.
# sudo vi /etc/apt/sources.list 하여 맨 하단 부분에 아래 두 줄을 추가해 넣는다.
deb http://ppa.launchpad.net/pidgin-nateon/ubuntu hardy main
deb-src http://ppa.launchpad.net/pidgin-nateon/ubuntu hardy main
: wq
한 다음 닫고서
# sudo apt-get update
# sudo apt-get install pidgin-nateon
하여 네이트온을 설치한다. 프로그램 리스트에서 Pidgin 인터넷 메신저를 실행시키면 아래와 같이 나타난다.
여기서 추가 버튼을 누른 후 사용하고 싶은 메신저를 선택한 후 해당하는 아이디와 비밀번호를 넣어주면 된다.
위와 같이 설정되었다. 네이트온을 맨 처음 추가한 후 두번째로 MSN을 추가하였다. 마지막으로 구글토크계정을 추가하니 상당히 많은 리스트가 존재한다.
인스턴트 메신저가 한창 편리할 때는 긴급한 일을 처리할 때 요청자의 입장에서는 무척 편리하다. 해외에 있을 경우 도움 요청하기도 물론 쉽다. 그렇지만 때때로 일을 할 때 방해받고 싶지 않으므로 종종 자신을 숨기기도 한다.
국부론을 출간한 아담 스미스의 보이지 않는 시장에 의해 세계 경제질서가 흘러가고 있다고 믿고 있었던 수많은 가리워진 진실의 실체를 서서히 깨닫는다. 신자유주의의 허상이다. 영국이 자유무역을 실행할 수 있었던 것은 이미 타국에 비해 월등한 경쟁력을 갖춘 상태에서 시작된다. 물론 타국 미국을 비롯한 독일,프랑스,일본도 마찬가지였다. 우리나라는 대표적인 보호무역과 관세로부터 국가주도형 산업을 키운 덕에 발전해 나간 대표적인 나라중 하나였다. 그런데 지금 우리나라의 경쟁력있는 부분이 얼마나 될까? 신자유주의체제안에서 전세계와 경쟁해서 이길 수 있다고 자신하는 허상을 믿고 있는 현 제도권 안의 정치인들이 무섭다. 결국 잘사는 사람들은 일부가 될 것이고 종국에는 사회 양극화를 극대화 시킬 수 있는 정책들만 쏟아져 나온다. 무역장벽을 허물면 사라지는 관세수입과 부자들의 세금에서 떼어냈던 종합부동산세의 줄어든 세 수입은 어떻게 만회할까?
결국 지난 대선에서 경제대통령으로 선택했던 그 분께 일반 서민들은 더 많은 세금을 내도록 보이지 않는 장치를 만들어 가고 있을 음지에서 활동하는 그들의 횡포를 언제까지 참아주고 기다려야 할지 모른다.
"과거에 어떤 일이 이루어졌는지를 알지 못한다면 항상 어린아이처럼 지내는 셈이다. 과거의 노력을 무시한다면 세계는 늘 지식의 유아기에 머물러 있을 것이다 (키케로)"
장하준은 나쁜 사마리아인들이라는 책에서 어린아이의 성장을 예로 들어 보호무역과 자유무역의 예를 적나라하게 보여준다. 우리 자녀를 6세부터 경쟁할 수 있도록 완전한 경쟁 체제안으로 내보낼 것인지 아니면 자신이 경쟁력을 갖출 수 있는 성인이 될 때까지 돌봐 주어야 하는지에 대한 멋진 비유를 들었다. 우리는 6세때부터(유아기) 돈벌고 경쟁력을 갖고 생존해 나갈 수 있는 기반이 마련되어 있다고 자신하다가 현재처럼 우스운 꼴을 맞이하게 되었다. 제2의 환난사태와 경제침체의 나락으로 달려가고 있다. 현재를 돌아보면서 모두가 함께 잘 살 수 있는 세상은 결코 부의 축적이 가져다 주지 않는다는 단순한 진리를 깨달아야 할 것 같다.
아직 우리는 부자나라가 아니다. 부자나라라고 착각하며 가입했던 클럽 OECD 그런데 환율 급등으로 가까스로 유지했던 1인당 국민소득 20,000 달러에서 15,000 달러대로 떨어지는 것도 시간 문제다. 지금처럼 무단 질주해 가다보면....-_-;;
'Computer_language > Linux' 카테고리의 다른 글
| 우분투 사용 총집합서 (0) | 2009.01.12 |
|---|---|
| 우분투에서 수도 (sudo) 사용자 추가방법, sudoers (0) | 2009.01.12 |
| swap 메모리를 설치후에도 설정할수 있나요? (0) | 2009.01.12 |
| SSH 터널링 - putty의 plink 사용예esniper (0) | 2009.01.12 |
| ubuntu souce list update (0) | 2009.01.12 |
1. Gparted 같은 유틸리티를 사용해서 파티션을 조절 하시던가
2. 스왑 파일을 만들어 두는 겁니다. 파티션을 건드리기가 꺼림직하시면 이쪽이 더 간편할겁니다. 터미널에서:
dd if=/dev/zero of=/swapfile bs=1024k count=[메가바이트]
mkswap /swapfile
swapon /swapfile
이렇게 입력하세요. 원하는 크기의 파일을 임시로 만들어서 그걸 스왑 파일로 정의하고 스왑을 사용하게 하라는 의미입니다.
* 저 [메가바이트] 를 원하는 스왑 크기 (메가바이트 단위)로 대체하세요. 예를 들어 1기가바이트를 주려면 1024를 입력하면 되겠죠
이대로는 부팅마다 swapon /swapfile을 입력해 줘야 하니:
을 입력하시고 열린 파일에 이걸 추가하세요.
정상적으로 적용되었는지는 터미널에서
를 입력해 보면 됩니다.
출처: http://ubuntuforums.org/archive/index.php/t-265051.html
'Computer_language > Linux' 카테고리의 다른 글
| 우분투 사용 총집합서 (0) | 2009.01.12 |
|---|---|
| 우분투에서 수도 (sudo) 사용자 추가방법, sudoers (0) | 2009.01.12 |
| 우분투에 메신저를 설치하다 (네이트온,MSN 등) (0) | 2009.01.12 |
| SSH 터널링 - putty의 plink 사용예esniper (0) | 2009.01.12 |
| ubuntu souce list update (0) | 2009.01.12 |
Contents
1 이 문서가 필요한 곳
2 필요한 것
3 방법
3.1 ssh -R 에 대해
3.2 ssh -L 에 대해
3.3 접속
4 실제의 예 1 (ssh서비스 이용하기)
4.1 my_office_pc 에서
4.2 my_home_adsl_pc 에서
5 실제의 예 2 (터미널 서비스 이용하기)
5.1 my_office_pc 에서
5.2 my_home_adsl_pc 에서
6 맺는 말
7 질문과 답변
8 토론
작성 : 김원일
[edit]1 이 문서가 필요한 곳 ¶
회사나 가정에서 작업하던 환경을 그대로 쓰고 싶지만 vpn 이나 firewall 등의 제한으로 외부에서 접근하기가 쉽지 않은 경우가 있다. proxy 가 있거나 vpn 이라면 별 다른 문제가 없을 수도 있겠으나 firewall 같은 경우 넷웍 관리자에게 요청하지 않는 이상, 또는 요청한다고 해도 그다지 쉽게 허가를 얻지 못할 것이다. vpn 이라고 해도 외부의 누군가에게 잠깐 내부의 자원을 이용하게 하기위해 자신의 vpn 접속 방법을 가르쳐 주는 것도 양심상, 보안상 그다지 권장하고 싶은 일은 아니다. 이 문서는 그러한 경우 외부에서 접근 가능한 ssh계정을 이용해 터널을 만들어 vpn, firewall 외부에서 그 안쪽으로 접근을 가능하게 하는 방법이다.
[edit]2 필요한 것 ¶
OpenSSH (ssh protcol 2 이상을 가정)
vpn 및 firewall 외부에 ssh 로 접속이 가능한 계정
임은재님이 작성하신 ssh Howto, ssh + mini proxy 등을 미리 읽어 두는 것이 도움이 된다.
[edit]3 방법 ¶
[edit]3.1 ssh -R 에 대해 ¶
ssh -R 은 원격서버의 특정 포트를 자신이 접근 가능한 서버 및 포트 (이문서에서는 vpn 안쪽의 자신의 서버 또는 작업을 하려는 서버)로 포워딩 하는 것이다. ssh -L 의 역이라고 봐도 무방하다 (ssh -L 에 대해서는 ssh mini proxy 문서를 참조하자)
vpn 또는 firewall 안쪽의 PC 에서
ssh -R port:host:hostport ssh_user@ssh_server
와 같은 명령을 사용한다.
ssh_server서버에 ssh_user라는 계정으로 접속하되 port로 지정한 포트로 들어오는 패킷을 host의 hostport로 포워딩한다는 것이다. 언뜻 알기 어렵지만 차근 차근 이해해 보자.
port : ssh_server에서 열 포트 번호다. (여기서 ssh_user가 ssh_server의 루트가 아니라면 1024번 이상의 포트번호를 지정해야 한다)
host : vpn 및 firewall 안쪽에 있는 우리가 바깥에서 사용할 서버의 ip 또는 이름이다. (꼭 안쪽에 있을 필요는 없다. ssh -R ... 명령을 내리는 자신의 컴퓨터에서 접근 가능해야 한다)
hostport : 위의 host 에서 우리가 이용하려는 서비스가 열려있는 포트 번호다. (역시 접근 가능해야 한다)
이상과 같이 하면 hostname의 loopback 주소(127.0.0.1)에서 port를 리스닝하게 된다. nestat -nl 로 확인해보라. loopback 주소로만 listening하는 것은 sshd 설정상 기본이다.
[edit]3.2 ssh -L 에 대해 ¶
이제 우리가 원하는 우회로의 반은 열린 셈이다. 나머지 반을 열어보자.
ssh -L localport:localhost:port ssh_user@ssh_server
이 명령은 vpn 또는 firewall 바깥의 환경에서 쓰이게 된다. 즉 집이나 외부업체의 회의실 또는 외딴 섬마을 학교의 pc실에서 쓰인다는 것이다.
localport : 현재 작업 중인 컴퓨터에서 열릴 포트이다. (netstat -nl 에서 Listen 중인 것으로 나타날 것이다)
localhost : 말 그대로 localhost라고 적는 것이다. 127.0.0.1 도 무방하다. 여기서 localhost 는 ssh_server의 루프백 주소를 가리킨다.
port : ssh -R 에서의 port 와 같다.
이제 모든 우회로가 열렸다!
[edit]3.3 접속 ¶
우회로를 이용하는 건 다음과 같다.
telnet localhost localport (telnet 서비스를 우회해서 접속할 경우)
http://localhost:localport/ (http 서비스의 경우)
ssh -p localport localhost (ssh 서비스의 경우)
smbclient -p localport localhost (삼바 서비스의 경우)
즉 모든 접속은 localhost로 ssh -L 에서 지정한 localport를 이용하게 된다.
[edit]4 실제의 예 1 (ssh서비스 이용하기) ¶
여기서는 실제로 명령어를 다루는 예를 들겠다. 다음과 같은 컴퓨터들이 등장한다.
my_office_pc (IP : 224.20.X.22 under Firewall)
ssh_server (IP : 210.32.X.221)
my_home_adsl_pc (IP: 61.78.X.226)
지금 시각은 오후 5:32분, 내일 오전까지 끝내야할 작업이 거의 다 끝나가지만 잔업은 하기 싫다. 집에서 작업하고 싶지만 방화벽 때문에 외부에서는 접속할 수가 없는 처지다.
[edit]4.1 my_office_pc 에서 ¶
my_office_pc ~$ ssh -R 22:localhost:22 210.32.X.221
myaccout@210.32.X.221's password: _ <-- ssh_server 패스워드 입력
ssh_server ~$ _
이제 짐을 싸고 정리한 후 퇴근한다!
[edit]4.2 my_home_adsl_pc 에서 ¶
my_home_adsl_pc ~$ ssh -L 2222:localhost:22 210.32.X.221
myaccout@210.32.X.221's password: _ <-- ssh_server 패스워드 입력
ssh_server ~$ _
다른 터미널을 열고
my_home_adsl_pc ~$ ssh -p 2222 localhost
myaccout@localhost`s password: _ <-- my_office_pc 의 패스워드 입력
my_office_pc $ _ <--- 사무실에 ssh 로 연결 되었다!!!
마무리 작업을 하고 맥주 한잔!
[edit]5 실제의 예 2 (터미널 서비스 이용하기) ¶
여기서는 실제로 명령어를 다루는 예를 들겠다. 다음과 같은 컴퓨터들이 등장한다.
my_office_pc (IP : 224.20.X.22 under Firewall,Windows XP)
ssh_server (IP : 210.32.X.221)
my_home_adsl_pc (IP: 61.78.X.226)
지금 시각은 오후 5:45분, 내일 오전까지 끝내야할 작업이 거의 다 끝나가지만 잔업은 진짜!! 하기 싫다. 집에서 작업하고 싶지만 방화벽 때문에 외부에서는 접속할 수가 없는 처지다.
[edit]5.1 my_office_pc 에서 ¶
지금의 사무실의 컴퓨터는 윈도우 환경이다. 윈도우에서는 별도의 ssh 프로그램이 필요하다.
putty (터널링이 가능한 최신 버젼)
plink (putty 의 자매 프로그램, windows console 에서 사용 가능하다. plink -R 또는 plink -L 로 unix 에서와 유사하게 사용한다.
ssh (cygwin 환경에서 사용가능)
plink 를 사용해보기로 하자.
> plink -R 3389:localhost:3389 210.32.X.221
myaccout@210.32.X.221's password: _ <-- ssh_server 패스워드 입력
ssh_server ~$ _
이제 짐을 싸고 정리한 후 퇴근한다!
[edit]5.2 my_home_adsl_pc 에서 ¶
집의 PC는 linux 또는 rdesktop 을 사용해야 한다. 이유는 MS에서 제공하는 windows용 terminal client는 별도로 IP를 확인하기 때문에 인증이 이루어지고도 사용은 불가능하다.
my_home_adsl_pc ~$ ssh -L 3389:localhost:3389 210.32.X.221
myaccout@210.32.X.221's password: _ <-- ssh_server 패스워드 입력
ssh_server ~$ _
다른 터미널을 열고
my_home_adsl_pc ~$ rdesktop localhost:3389 (포트번호는 생략가능)
//rdektop에서 my_office_pc의 윈도우 계정 패스워드 입력
//rdesktop이 시작된다.
마무리 작업을 하고 맥주 한잔!
[edit]6 맺는 말 ¶
원래는 친구 회사의 PC에서 작업을 하기 위해서 이런 방법을 생각해 보았다(어디까지나 친구 본인의 요청에 의해서). 꽤 귀찮아 보이지만 어쩔 수 없는 상황에서는 유용하리라고 생각한다. 외부에 ssh계정이 있어야 하는 단점이 있긴 하지만 그런 경우에는 각자의 집에 ssh 서비스를 이용하는 방법도 있으므로 큰 문제는 없으리라 생각한다.
[edit]7 질문과 답변 ¶
Q: IP 공유기를 사용하고 있습니다. 사설망 IP로도 접근 가능한 방법이 있나요?
A: 네. 공유기 아래의 사설망으로도 위 방법을 사용하면 가능합니다. 하지만 공유기라면 DMZ 설정이나 port forwarding이 더욱 간단하겠지요. 이 문서는 공유기나 방화벽, vpn 설정을 고칠 수 없는 일반 유저를 위한 내용입니다.
Q: 잘 사용한 후, 열어둔 터널을 닫고 싶습니다. 어떻게 해야 하나요?
A: 아~. ssh -R/-L 로 열어둔 터미널에서 나오면 되는군요.
'Computer_language > Linux' 카테고리의 다른 글
| 우분투 사용 총집합서 (0) | 2009.01.12 |
|---|---|
| 우분투에서 수도 (sudo) 사용자 추가방법, sudoers (0) | 2009.01.12 |
| 우분투에 메신저를 설치하다 (네이트온,MSN 등) (0) | 2009.01.12 |
| swap 메모리를 설치후에도 설정할수 있나요? (0) | 2009.01.12 |
| ubuntu souce list update (0) | 2009.01.12 |
deb-src http://kr.archive.ubuntu.com/ubuntu/ feisty main restricted
deb http://kr.archive.ubuntu.com/ubuntu/ feisty-updates main restricted universe
deb-src http://kr.archive.ubuntu.com/ubuntu/ feisty-updates main restricted
deb http://kr.archive.ubuntu.com/ubuntu/ feisty multiverse
deb-src http://kr.archive.ubuntu.com/ubuntu/ feisty multiverse
deb http://security.ubuntu.com/ubuntu feisty-security main restricted universe
deb-src http://security.ubuntu.com/ubuntu feisty-security main restricted
deb http://security.ubuntu.com/ubuntu feisty-security multiverse
deb-src http://security.ubuntu.com/ubuntu feisty-security multiverse
deb http://packages.ubuntu-eee.com intrepid main
deb http://ppa.launchpad.net/netbook-remix-team/ubuntu intrepid main
deb http://www.array.org/ubuntu intrepid eeepc
deb http://ppa.launchpad.net/openoffice-pkgs/ubuntu intrepid main
##--------------------
## UBUNTU REPOSITORIES
## -------------------
deb http://my.archive.ubuntu.com/ubuntu/ hardy main restricted
deb-src http://my.archive.ubuntu.com/ubuntu/ hardy main restricted
deb http://my.archive.ubuntu.com/ubuntu/ hardy-updates main restricted
deb-src http://my.archive.ubuntu.com/ubuntu/ hardy-updates main restricted
deb http://my.archive.ubuntu.com/ubuntu/ hardy universe
deb-src http://my.archive.ubuntu.com/ubuntu/ hardy universe
deb http://my.archive.ubuntu.com/ubuntu/ hardy-updates universe
deb-src http://my.archive.ubuntu.com/ubuntu/ hardy-updates universe
deb http://my.archive.ubuntu.com/ubuntu/ hardy multiverse
deb-src http://my.archive.ubuntu.com/ubuntu/ hardy multiverse
deb http://my.archive.ubuntu.com/ubuntu/ hardy-updates multiverse
deb-src http://my.archive.ubuntu.com/ubuntu/ hardy-updates multiverse
deb http://my.archive.ubuntu.com/ubuntu/ hardy-backports main restricted universe multiverse
deb-src http://my.archive.ubuntu.com/ubuntu/ hardy-backports main restricted universe multiverse
deb http://archive.canonical.com/ubuntu hardy partner
deb-src http://archive.canonical.com/ubuntu hardy partner
deb http://security.ubuntu.com/ubuntu hardy-security main restricted
deb-src http://security.ubuntu.com/ubuntu hardy-security main restricted
deb http://security.ubuntu.com/ubuntu hardy-security universe
deb-src http://security.ubuntu.com/ubuntu hardy-security universe
deb http://security.ubuntu.com/ubuntu hardy-security multiverse
deb http://my.archive.ubuntu.com/ubuntu/ hardy-proposed restricted main multiverse universe
deb-src http://security.ubuntu.com/ubuntu hardy-security multiverse
deb http://ppa.launchpad.net/ubuntume.team/ubuntu hardy main # Ubuntu Muslim Edition
deb-src http://ppa.launchpad.net/ubuntume.team/ubuntu hardy main # Ubuntu Muslim Edition
deb http://www.linuxmint.com/repository romeo/
deb http://tskariah.000webhost.com/ubuntu ubuntu main
deb http://ppa.launchpad.net/kubuntu-members-kde4/ubu...gutsy main
## +++ Backports & Proposed (Ubuntu Unstable) +++
deb http://archive.ubuntu.com/ubuntu/ hardy-backports main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu/ hardy-proposed main restricted universe multiverse
## +++ Source Repositories +++
deb-src http://archive.ubuntu.com/ubuntu/ hardy main restricted universe multiverse
deb-src http://archive.ubuntu.com/ubuntu/ hardy-updates main restricted universe multiverse
deb-src http://security.ubuntu.com/ubuntu/ hardy-security main restricted universe multiverse
deb-src http://archive.ubuntu.com/ubuntu/ hardy-backports main restricted universe multiverse
deb http://ppa.launchpad.net/kubuntu-members-kde4/ubu...hardy main
deb http://us.archive.ubuntu.com/ubuntu/ hardy main restricted
deb-src http://us.archive.ubuntu.com/ubuntu/ gutsy main restricted
deb http://us.archive.ubuntu.com/ubuntu/ hardy-updates main restricted
deb-src http://us.archive.ubuntu.com/ubuntu/ hardy-updates main restricted
##Universe
deb http://us.archive.ubuntu.com/ubuntu/ hardy universe
deb-src http://us.archive.ubuntu.com/ubuntu/ hardy universe
deb http://us.archive.ubuntu.com/ubuntu/ hardy-updates universe
deb-src http://us.archive.ubuntu.com/ubuntu/ hardy-updates universe
## Multiverse
deb http://us.archive.ubuntu.com/ubuntu/ hardy multiverse
deb-src http://us.archive.ubuntu.com/ubuntu/ hardy multiverse
deb http://us.archive.ubuntu.com/ubuntu/ hardy-updates multiverse
deb-src http://us.archive.ubuntu.com/ubuntu/ hardy-updates multiverse
## Backports
deb http://us.archive.ubuntu.com/ubuntu/ hardy-backports main restricted universe multiverse
deb-src http://us.archive.ubuntu.com/ubuntu/ hardy-backports main restricted universe multiverse
## Canonical Partner Repository
deb http://archive.canonical.com/ubuntu hardy partner
deb-src http://archive.canonical.com/ubuntu hardy partner
deb http://security.ubuntu.com/ubuntu hardy-security main restricted
deb-src http://security.ubuntu.com/ubuntu hardy-security main restricted
deb http://security.ubuntu.com/ubuntu hardy-security universe
deb-src http://security.ubuntu.com/ubuntu hardy-security universe
deb http://security.ubuntu.com/ubuntu hardy-security multiverse
deb-src http://security.ubuntu.com/ubuntu hardy-security multiverse
## PLF REPOSITORY
deb http://packages.medibuntu.org/ gutsy free non-free
deb http://ppa.launchpad.net/reacocard-awn/ubuntu gutsy main
## +++ Medibuntu +++
deb http://packages.medibuntu.org/ hardy free non-free
deb http://packages.medibuntu.org/ feisty free non-free
deb http://ppa.launchpad.net/kubuntu-members-kde4/ubu...hardy main
deb http://playonlinux.botux.net/ hardy main
'Computer_language > Linux' 카테고리의 다른 글
| 우분투 사용 총집합서 (0) | 2009.01.12 |
|---|---|
| 우분투에서 수도 (sudo) 사용자 추가방법, sudoers (0) | 2009.01.12 |
| 우분투에 메신저를 설치하다 (네이트온,MSN 등) (0) | 2009.01.12 |
| swap 메모리를 설치후에도 설정할수 있나요? (0) | 2009.01.12 |
| SSH 터널링 - putty의 plink 사용예esniper (0) | 2009.01.12 |
다음의 기사는 월간 프로그램 세계 1997년 6월호 특집기사로 실렸던 것입니다. 특집기사는 총 3부로 이루어져 있는데, 1부는 Perl의 소개, 2부는 Perl의 문법, 3부는 Perl을 이용한 CGI 예제 프로그램 작성으로 구성되어 있습니다. 제가 맡은 부분은 2부였고 총 분량의 절반에 해당합니다. 1부와 3부는 김대신(웹데이타뱅크)씨가 맡으셨습니다. 다음의 글은 제가 초안으로 작성한 텍스트 파일을 HTML문서로 약간 손을 본 것입니다.
차례
- 소개
- Perl의 문법
- 변수(Variable)
- 수치(number)
- 문자열(string)
- scalar variable
- vector variable
- 특수한 변수(Special variable)
- 레퍼런스(reference)
- 배열의 배열, 해시의 배열, 배열의 해시
- 수치(number)
- 식(Expression)
- 기본 연산자
- 추가 연산자
- 기본 입출력 연산자
- 비교 연산자
- 기본 연산자
- Control Structure(제어 구조)
- if
- unless
- while/until
- for
- foreach
- do/while, do/until
- goto
- next, last, redo
- if
- 서브루틴(Subroutine)
- 정의와 사용
- my와 local
- 정의와 사용
- 패턴 매칭(Pattern Matching)
- 정규 표현식(regular expression)
- match, substitute, translate
- 문자열 pattern 조작
- 정규 표현식(regular expression)
- 변수(Variable)
펄은 임의의 텍스트 파일들을 검색하고 그 파일에서 정보를 추출하며, 그 정보에 따라 보고서를 작성하는데 최적화된 언어이다. 또한 많은 시스템 관리 작업에 좋은 언어이다. 이 언어는 실용적일 수 있도록 만들어졌기 때문에 크기가 아주 작거나 아름답게 만들어지지지 는 않았지만 사용하기 쉽고 효율적이며 완벽하다고 말할 수 있다. 펄은 C와 sed와 awk와 sh 등의 사람들이 친숙하게 생각하는 언어들의 장점을 모아서 만든 것이기 때문에 배우기 어렵지 않다. 표현식은 거의 C와 비슷하며, 다른 유닉스 유틸리티와는 달리 용량 등의 제한이 없다. 주로 text를 처리하는데 뛰어난 능력을 보여주지만, 바이너리 자료를 다루는데 있어서도 데이터베이스를 만드는 기능이 있을 정도이다. sed나 awk를 사용하는데 문제가 발생한다면 C로 짜는 대신에 펄로 작성하면 스크립트를 거의 바꾸지 않아도 된다.
2부. 펄의 문법
Perl의 저자, Larry Wall이 말했던 것처럼 Perl은 한 가지 일을 하기 위해 10가지 방법을 제시하는 언어이다. 어떻게(how) 할 것인지가 중요한 게 아니라 무엇을(what) 할 것인지를 먼저 생각하고 프로그래밍을 해야 할 것이다. 그러나 다양한 표현 방식들을 많이 익히면 익힐수록 프로그래머에게 더 많은 가능성이 열리는 셈이다. 다음의 글은 독자들이 기본적인 C프로그래밍을 이해할 수 있고 유닉스의 shell기반의 작업들에 무지하지 않음을 가정하고 쓰여진 것이다. 그러나 가능하면 초보자들도 이해할 수 있도록 쉬운 표현과 예제를 이용하였다. 다음의 설명은 Perl 5를 기준으로 쓰여졌으나, Perl 4에서도 무난하게 사용 가능할 것이다.
1. 변수(Variable)
기본적으로 Perl은 변수에 대해, C와 같이 강력한 type checking을 하지 않는다. 다시 말해서 '값이 어떤 방식으로 저장되어있는가'는 '어떻게 사용할 것인가'와는 별개의 문제라는 것이다. C프로그래밍에 익숙한 사용자라면 int c = 'x'; 으로 정의된 변수 c가 문자형으로도 정수형으로도 사용 가능한 것을 떠올릴 수 있을 것이다. 그런 것을 확장해서 생각해보면 Perl의 변수들은 여러 형태로 사용할 수 있다. 그것은 Perl 인터프리터(interpreter;해석기)가 내부적으로 자동 변환해 주기 때문에 가능한 것이다.
1) 수치(number)
Perl에는 정수형 수치는 존재하지 않는다. 모든 수치는 double-precision floating point형 수치로 존재한다. 다음과 같은 형태의 수치는 float literal(소수형 상수)이다.
111.25
23.25e91
-12.5e29
-12e-34
3.2E-23
다음과 같은 형태의 수치는 integer-literal(정수형 상수)이다. 숫자 앞에 0이나 0x를 붙여쓰게 되면 각각 8진수와 16진수를 의미하게 된다.
342
-2423
0377
-0xf0
2) 문자열(string)
문자열은 이름이 뜻하듯이 연속된 문자들의 순열이다. 일반적인 ASCII 문자는 128개로 표현이 되지만, Perl에서는 특수문자가 표현되어야 하기 때문에 extended ASCII를 지원하여 문자열 내부의 각각의 글자는 0에서 255까지의 ASCII값을 가지게 된다. 문자열은 여러 형태의 두 quotation mark로 감싸서 표현할 수 있는데, 대표적인 케이스는 ''(single-quote)와 ""(double-quote), ``(back-quote)이다. single-quote사이에 들어가는 문자열은 interpolation을 하지 않고, double-quote사이에 들어가는 문자열은 interpolation을 하게 되는 차이점이 있다. 그러면 interpolation이란 무엇인가 예를 보면서 이해하도록 하자.
$str1 = 'hello\n\neveryone';
$str2 = "hello\n\neveryone";
print $str1 . "\n";
print $str2 . "\n";
두 문장은 quotation mark가 다르다는 점을 제외하고는 차이점이 없다. 그런데 출력결과는 다음과 같이 다르게 된다.
hello\n\neveryone # 이것은 str1의 출력 결과이다.
hello # 이것은 str2의 출력 결과이다.
everyone
위와 같은 escape character뿐만 아니라 이미 정의되어진 변수들을 문자열 안에서 사용하는 경우에도 interpolation의 가능 여부에 따라 그 변수가 해석되기도 하고 그렇지 않기도 한다.
$str0 = "I'm a boy.";
$str1 = 'hello $str0';
$str2 = "hello $str0";
print $str1 . "\n";
print $str2 . "\n";
결과는 다음과 같다.
hello $str0 # str1의 출력 결과
hello I'm a boy. # str2의 출력 결과
single-quote 문자열에서 single-quote(')를 표현하는 방법은 backslash뒤에 single-quote를 쓰는 것이다.
print 'I\'m a boy.'; # 출력 결과 I'm a boy.
다음은 double-quote안에서 특별한 효과를 가지는 escape character의 종류와 그 의미에 관한 표이다.
| \n | newline 다음 줄로 |
| \r | return 줄의 맨 앞으로 |
| \t | tab 탭 |
| \f | formfeed |
| \b | backspace |
| \v | vertical tab |
| \a | alarm bell |
| \e | ESC |
| \073 | octal value 8진수(여기서는 73(8) = 7*8+3(10) = 59(10)) |
| \x7f | hexadecimal value 16진수(여기서는 7f(16) = 7*16+15(10) = 127(10)) |
| \cC | 제어문자 C |
| \\ | backslash |
| \" | double-quote |
| \l | 다음 글자를 대문자로 |
| \L | 다음 글자를 소문자로 |
| \u | 뒤에 오는 모든 글자를 대문자로 |
| \U | 뒤에 오는 모든 글자를 소문자로 |
| \Q | 뒤에 오는 모든 특수문자에(non-alphanumeric) \를 붙여서 |
| \E | \U, \L, \Q의 끝을 표시 |
마지막으로 back-quote가 있는데, 이것은 문자열이라기보다는 문자열을 shell에서 실행한 결과 값을 저장하게 된다. back-quote는 back-tick이라고 부르기도 한다.
$time_of_today = `date`;
print $time_of_today; # 출력 결과 Mon Apr 27 20:59:04 KST 1998
위와 같은 코드에서는 Perl이 date라는 프로그램을 실행하여 나오는 값이 변수에 저장되게 된다. back-quote문자열에서는 double-quote문자열에서와 마찬가지로 interpolation이 되어진다. 다음 코드는 shell에서 "ls | grep doc"를 실행한 것과 같은 결과를 출력하는 것이다.
$keyword = 'doc';
print `ls | grep $keyword`;
출력결과
jdbcprog.doc
vi.doc
xprog.doc
다음의 표는 quotation의 여러 가지 방법에 대해 정리한 것이다.
| 관습적 사용 | 일반적 사용 | 의미 | interpolation여부 |
| '' | q// | 문자열상수 | x |
| "" | qq// | 문자열상수 | o |
| `` | qx// | 실행명령 | o |
| () | qw// | list | x |
| // | m// | pattern match | o |
| s/// | s/// | substitution | o |
| y/// | tr/// | translation | x |
일반적 사용에서 q 다음에 나와있는 backslash(/)는 다른 문자로 바꾸어 사용할 수 있다. 자세한 것은 뒤에 나오는 소단원을 참고하도록 하고 간단한 예제를 통해 그 사용법을 알아보도록 하자.
$abc = q$I'm a boy. You're a girl.$;
$def = qq#Hello,\neveryone#;
$ghi = q&
while (test != 0) {
i++;
printf("%d", i);
}
&;
변수 abc는 $를 single-quote(') 대신으로 사용하였고, def는 #을 double-quote(") 대신으로 사용하였다. ghi의 경우, multi-line string을 지정하는데, single-quote(') 대신에 &기호를 사용하였다.
3) scalar variable
scalar variable은 하나의 값을 가지는 변수를 뜻하고 다음에서 살펴 볼 vector variable과는 상대되는 표현이다. scalar variable은 앞에서 보았던 수치나 문자열과 같은 값을 오로지 하나만 가지는 값이다. 일반적으로 scalar variable은 $기호를 변수 이름 앞에 붙여 vector variable과 구분한다. Perl에서는 C에서와 마찬가지로 변수의 이름은 대소문자가 달라지면 전혀 다른 변수로 인식된다. 다음의 변수들은 모두 다르게 구분되는 scalar 변수들이다.
$abc
$ABC
$account_number_of_bank1
$account_number_of_bank2
$xyz001
scalar variable에 대해서 산술 연산자 등의 일반적인 연산자를 수행할 수 있다.
4) vector variable
vector variable은 크게 세 가지 종류로 나눌 수 있는데, array와 associative array가 그것이다. Perl에서는 array는 list라는 이름으로, associative array는 hash라는 이름으로 일컬어지기도 한다.
list는 변수 이름 앞에 @표시를 하여 구분하고, hash는 %기호를 사용한다. 다음의 변수들은 각각 list와 hash의 예이다.
@certain_list = ("abc", "def", "123");
@quoted_list = qw(
1, 2, 3,
4, 5, 6,
7, 8,
);
%a_special_hash = (('test', "hello"), ('verify', 123));
%list_like_hash = ("red", 0xf00, "green", 0x0f0, "blue", 0x00f);
%another_special_hash = (
red => 0xf00,
green => 0xf00,
blue => 0xf00,
);
vector variable은 다른 vector 형태의 variable을 포함하여 지정할 수 있다.
@next_list = ("abc", "def", "123", @previous_list);
%general_hash = (%a_special_hash, %list_like_hash);
vector variable은 scalar variable과는 달리 주의해서 사용해야 한다. quotation을 하는 경우와 아닌 경우가 다르고, 그 변수를 vector차원에서 다루는 경우와 그의 원소인 scalar차원에서 다루는 경우가 다르다. 다음 예제를 참고하여 차이점을 알아보도록 하자.
print "@certain_list";
print @certain_list;
두 문장의 출력 결과는 다음과 같다. print는 첫 번째의 경우를 list를 quotation한 것으로 간주하여 space를 출력해주고, 두 번째의 경우를 list로 간주하여 space없이 붙여서 출력해준다.
abc def 123
abcdef123
다음의 hash에 관련된 코드는 list와 같을까?
print "%a_special_hash";
print %a_special_hash;
list와는 달리 hash의 경우 interpolation이 일어나지 않음을 알 수 있다.
testhelloverify123
%a_special_hash
일반적인 의미에서의 "hash"란 두개의 값을 한 쌍으로 하여 저장하는 방식을 의미하는데, 여기서도 마찬가지로 hash는 key와 value를 구분하여 사용하게 된다. 앞에서 제시한 예에서는 "test"와 "verify", "red", "green", "blue"등이 key가 되고, "hello", 123, 0xf00, 0x0f0, 0x00f등이 그 key로 찾을 수 있는 value가 된다.
print $a_special_hash{'test'};
$key = 'verify';
print $a_special_hash{$key};
list의 경우에는 각각의 value를 처리하기 위해 index(subscript)를 사용한다. 이런 경우에는 list 중의 하나의 scalar variable에 대한 연산이 된다. C에서의 index와는 달리 Perl에서는 ..를 이용해서 range(범위)에 대한 연산도 가능하다.
print $colors[0];
$id_list[3]++;
print @month[8..11]; # @month[8..11]는 @month[8, 9, 10, 11]과 같다.
$b = $namelist[$number];
list 단위의 연산도 가능하다. 대표적인 것으로 list assignment가 있다.
($a, $b, $c) = (3, 4, 5);
@array = ('a', 'b', 'c', 'd');
vector variable 중에는 어떤 값도 가지지 않는 변수가 존재할 수 있는데, 이런 것을 null list라고 하며 ()로 표현한다.
@a = ();
특히 null list는 0, "0"과 함께 조건문에서 false expression을 의미하는 것으로 사용된다.
list의 마지막 인덱스를 알기 위해서는 $#기호를 변수이름 앞에 붙이면 된다. list 중에 포함되어 있는 원소의 개수를 알기 위해서는 scalar()함수를 사용한다. 인덱스는 0부터 매겨지기 때문에 일반적으로 $#list + 1 == scalar(@list)가 성립한다.
5) 특수한 변수(Special variable)
a) Regular expression variable
우선 $*라는 특수변수가 multi-line mode를 위해 Perl 4까지 사용되었는데, Perl 5부터는 regular expression을 사용할 때 modifier를 사용하는 방식으로 바뀌면서 더 이상 사용되지 않게 되었다. 이것은 패턴 매칭의 regular expression부분을 참고하도록 한다.
special variable들은 기억하기 쉽도록 mnemonic name을 가지고 있는데, 그러한 기능을 사용하려면 Perl 프로그램의 앞부분에서
use English;
로 지정해주어야 한다. 다음은 각각의 special variable과 그 역할에 대해 정리해놓은 표이다. pattern match와 관련된 변수들은 지역변수(local special variable)임을 기억하도록 하자.
| $digit | $1, $2, $3, ... | 패턴 바깥에서, 매치(match)가 일어난 괄호 안의 substring을 지정할 때 사용되는 변수로 왼쪽 괄호'('의 순서대로 digit위치에 숫자가 사용된다. |
| \digit | \1, \2, \3, ... | 패턴 안에서 사용되는 $digit형 변수와 같은 역할을 한다. |
| $& | $MATCH | 가장 마지막에 매치가 일어난 substring을 지정하는 변수 |
| $` | $PREMATCH | $MATCH 앞쪽의 substring을 지정하는 변수 |
| $' | $POSTMATCH | $MATCH 뒤쪽의 substring을 지정하는 변수 |
| $+ | $LAST_PAREN_MATCH | 패턴 내의 가장 뒤쪽에 위치한 괄호 안의 substring을 지정하는 변수로 alternative matching 사용시 편리하다. |
| $* | $MULTILINE_MATCHING | default로 0의 값을 가지면서 single-line matching mode를 지정하고, 1의 값을 가지게 되면 multi-line matching mode를 지정한다. |
여기서 제시된 여러 special variable 중에서 $*만이 값을 바꿀 수 있는 변수이고, 나머지 변수들은 모두 read-only의 속성을 가지는 변수이다.
다음은 local special variable을 사용한 예제로서, default input variable인 $_에서 pattern matching을 수행하고 match가 일어난 부분과 바로 앞부분, 바로 뒷부분이 $`, $&, $'에 저장됨을 보여준다.
$_ = 'abcdefghi';
/def/;
print "$`:$&:$'\n";
출력결과는 abc:def:ghi 이다.
다음은 위치상으로 가장 뒤쪽에서 매치가 일어나는 부분은 Revision: 뒤쪽의 문자열이며, 이 문자열은 $+에 저장됨을 알 수 있는 예제이다. pattern matching이 성공적으로 수행되면(match가 일어나면) $rev에 revision값을 저장하게 된다.
/Version: (.*)|Revision: (.*)/ && ($rev = $+);
b) Per-Filehandle variable
Filehanle이란 사용자가 작성한 Perl program과 외부에 존재하는 파일사이의 I/O 연결을 위한 Perl program의 이름이다. Unix의 표준 file-descriptor를 지원하기 위한 filehandle로는 STDIN(표준입력)와 STDOUT(표준출력), STDERR(표준에러출력)가 있다. 이외에도 사용자가 특정한 파일을 다루기 위해 filehandle을 지정할 수 있다. 자세한 내용은 파일조작에 관련된 절을 참고하도록 하자.
method HANDLE EXPR 또는 HANDLE->method(EXPR)과 같은 형식으로 지정한 다음에 다음과 같은 코드를 사용하여 다음의 변수들을 지정 또는 변경할 수 있다. HANDLE위치에는 사용할 filehandle의 이름을 지정하면 되고, EXPR위치에는 현재 filehandle의 속성의 값을 지정할 수 있다. 사용가능한 method는 아래 정리되어 있다.
use FileHandle;
| $| | $OUTPUT_FLUSH_NUMBER | autoflush HANDLE EXPR | 값을 0이 아닌 값으로 지정하면, write또는 print문장 후에 fflush(3)함수를 호출하여 현재 선택된 output channel로 출력을 강제한다. |
| $% | $FORMAT_PAGE_NUMBER | format_page_nubmer HANDLE EXPR | 현재 선택된 output channel의 현재 page 번호이다. |
| $= | $FORMAT_LINES_PER_PAGE | format_lines_per_page HANDLE EXPR | 현재 선택된 output channel의 현재 page 길이(프린트 가능한 line의 수)이다. |
| $- | $FORMAT_LINES_LEFT | format_lines_left HANDLE EXPR | 현재 선택된 output channel의 남아있는 line의 수이다. |
| $~ | $FORMAT_NAME | format_name HANDLE EXPR | 현재 선택된 output channel의 현재 report format의 이름이다. |
| $~ | $FORMAT_TOP_NAME | format_top_name HANDLE EXPR | 현재 선택된 output channel의 현재 top-of-page format의 이름이다. |
다음은 관련된 특수한 변수들의 사용 예제이다.
use FileHandle;
use English;
print '$| = '."$|\n";
print '$% = '."$%\n";
print '$- = '."$-\n";
print '$~ = '."$~\n";
print '$^ = '."$^ \n";
print '$= = '."$=\n";<
print '$= = '."$FORMAT_LINES_PER_PAGE\n";
format_lines_per_page STDOUT 30;
print '$= = '."$FORMAT_LINES_PER_PAGE\n";
print '$= = '."$=\n";
특정 filehandle인 HANDLE에 per-filehandle special variable을 지정해주는 예제는 다음과 같다.
select((select(HANDLE), $| = 1, $^ = 'mytop')[0]);
c) Global Special variable
| $_ | $ARG | default input string, standard input이나 첫 번째 argument로 넘겨진 파일을 읽을 때 넘겨져 오는 string을 의미한다. |
| $. | $INPUT_LINE_NUMBER $NR | 마지막으로 읽힌 filehandle의 현재 input line number이다. 여러 argument로 넘겨진 파일들을 구분하지 않으므로, 다른 파일로 바뀌더라도 line number가 계속 증가하게 된다. |
| $/ | $INPUT_RECORD_SEPARATOR $RS | input record를 구분해주는 string을 의미하며 default값은 newline character이다. |
| $, | $OUTPUT_FIELD_SEPARATOR $OFS | output field를 구분해주는 string이며, print 연산자에서 사용된다. 일반적으로는 comma(,)가 separator로 사용된다. |
| $\ | $OUTPUT_RECORD_SEPARATOR $ORS | output record를 구분해주는 string으로서 보통은 print 연산자가 record뒤에 newline내지는 record separator을 찍어주지 않기 때문에 필요할 경우, 지정하여야 한다. |
| $" | $LIST_SEPARATOR | list의 구분자로 사용되는 string을 지정하는 변수이다. 기본 값으로 space가 지정되어 있다. |
| $; | $SUBSCRIPT_SEPARATOR $SUBSEP | 다차원 배열을 만들기 위해 list내에서 변수들을 나열할 경우, 그 변수들이 하나의 record로 인식되어야 하는데, 그것을 위해서 list내의 각 변수들을 join하는데 사용하는 변수이다. |
| $^L | $FORMAT_FORMFEED format_formfeed HANDLE EXPR |
print할 때, output의 format에서 formfeed로 사용될 string을 지정하는 변수로서, 기본 값은 "\f"이다. |
| $: | $FORMAT_LINE_BREAK_CHARACTERS format_line_break_characters HANDLE EXPR |
연속적인 field를 잘라야 하는 경우 그 기준이 되는 character의 집합을 정의하는 변수이다. default로 "\n-", 다시 말해서 newline과 hyphen이 사용된다. |
| $^A | $ACCUMULATOR | format line을 위한 write accumulator의 현재 값을 지정하는 변수이다. |
| $# | $OFMT | Perl5에서는 사용되지 않는, 이전 버전과의 호환성을 위해 제공되는 변수로, 숫자를 출력하기 위한 output format을 지정하는 변수이다. 초기 값은 %.14g 이다. |
| $? | $CHILD_ERROR | 마지막 실행 문에서 return되는 status값이다. 상위 8비트는 child process의 exit value이고, 하위 8비트는 어떤 signal을 받았는지와 core dump가 일어났는지의 여부에 대한 정보를 포함한다. |
| $! | $OS_ERROR $ERRNO | error에 관한 정보를 포함하는 변수로서, 사용되는 문맥에 따라 error 번호 또는 error string을 보여주게 된다. |
| $@ | $EVAL_ERROR | eval 명령으로부터 발생하는 error message를 담는 변수이다. null로 값이 지정될 경우 성공적으로 실행되었음을 의미한다. |
| $$ | $PROCESS_ID $PID | 현재 script를 실행하고 있는 Perl프로그램의 process id(번호)를 지니고 있는 변수이다. |
| $< | $REAL_USER_ID $UID | 현재 process의 real user id(uid)를 지닌 변수로서, process를 실행시킨 사용자의 id를 의미한다. |
| $> | $EFFECTIVE_USER_ID $EUID | 현재 process의 effective user id(euid)를 지닌 변수로서, process의 원래 소유자의 id를 의미한다. 일반적인 process의 경우, uid와 같은 값을 가지지만, setuid bit가 켜져 있는 실행파일의 경우, uid는 실행자의 id로, euid는 파일 소유자의 것으로 지정된다. |
| $( | $REAL_GROUP_ID $GID | 현재 process의 real group id(gid)를 지정하는 변수이다. |
| $) | $EFFECTIVE_GROUP_ID $EGID | 현재 process의 effective group id(egid)를 지정하는 변수이다. |
| $0 | $PROGRAM_NAME | 현재 실행중인 Perl script의 이름을 지정하는 변수이다. |
| $[ | 배열의 첫 번째 원소의 index, 또는 substring의 첫 번째 글자의 index를 지정하는 변수이다. 기본적으로는 0번 원소부터 배열이 시작하지만, 1번 원소부터 배열이 시작하도록 1로 값을 바꿀 수 있다. | |
| $] | $PERL_VERSION | Perl의 version과 patch level을 알려주는 변수로서, 5.004는 5번째 version에 4번째 patch level임을 의미한다. |
| $^D | $DEBUGGING | debugging flag(-D switch)가 켜져 있는지에 관한 정보를 담고 있는 변수이다. |
| $^F | $SYSTEM_FD_MAX | 현재 open되어 사용되고 있는 file descriptor의 최대 번호를 지정하는 변수이다. 보통 프로그램이 시작하게 되면 자동으로 0, 1, 2번이 STDIN, STDOUT, STDERR로 설정된다. |
| $^H | Perl compiler의 내부 컴파일 힌트에 관한 정보를 담는 변수이다. | |
| $^I | $INPLACE_EDIT | inplace-edit extension의 값을 저장하는 변수이다. 이 값은 -i switch에 의해 지정된다. |
| $^O | $OSNAME | 현재 사용되고 있는 Operating System의 이름을 저장하는 변수이다. |
| $^P | $PERLDB | Perl debugger가 자신을 debug하지 않도록 꺼주는 내부 flag 변수이다. |
| $^T | $BASETIME | script가 실행되기 시작한 시각을 지정하는 변수이다. Unix system에서는 70년 1월 1일 0시 0분 0초(epoch)로부터의, 초단위 시간이다. |
| $^W | $WARNING | -w switch에 의해 지정되는 warning(경고) 여부의 값을 저장하는 변수이다. |
| $^X | $EXECUTABLE_NAME | Perl 바이너리가 실행 시에 가지게 되는 이름을 지정하는 변수이다. |
| $ARGV | argument로 넘겨져 들어온 파일의 이름이다. |
다음의 예제는 동일한 의미를 가지는 코드이다.
$foo{$a, $b, $c}
$foo{join($;, $a, $b, $c)}
d) Global special array
| @ARGV | 넘겨져 들어온 command-line argument의 list를 저장하는 변수이다. |
| @INC | do, require, use등의 operator를 사용할 때 필요한 Perl script를 찾는 디렉토리를 지정하는 변수이다. -I switch를 사용하여 지정된다. lib module을 사용하여도 지정 가능하다. |
| @F | -a switch를 사용한 경우에, input line을 분리해 넣어줄 변수의 array를 지정하는 list 변수이다. |
| %INC | module로 사용될 Perl script의 이름과 그 script의 절대경로를 저장해놓은 hash 변수이다. |
| %ENV | shell에서 넘겨져 온 hash type의 환경변수이다. 환경변수의 이름과 그 값을 hash해 놓았다. |
| %SIG | signal과 그에 해당하는 signal handler를 지정하는 hash 변수이다. |
다음은 환경 변수를 지정하는 예제이다.
$ENV{'PATH'} = "/bin:/usr/bin:/usr/local/bin";
signal handler를 사용하는 예제를 참고하도록 하라. Ctrl-C를 눌러 interrupt를 걸게 되면 프로그램이 중단되게 되는데 INT signal을 가로채서 특정한 함수(signal handler)를 실행시키도록 할 수 있다.
sub sighandler {
local($sig) = @_;
print "Closing log file...\n";
close(LOG);
exit(0);
}
$SIG{'INT'} = 'handler';
e) Global special Filehandles
| ARGV | @ARGV에서 저장된 argument로 넘겨진 file들을 다루는 filehandle이다. |
| STDERR | standard error에 대한 filehandle이다. |
| STDIN | standard input에 대한 filehandle이다. |
| STDOUT | standard output에 대한 filehandle이다. |
| DATA | Perl script에서 __END__라는 token뒤쪽에 나오는 모든 자료에 대한 filehandle이다. |
| _(underline) | 마지막으로 다루었던 파일에 대한 정보를 cache로 저장하고 있는 filehandle이다. |
6) 레퍼런스(reference)
'레퍼런스'란 우리말로 옮기자면 '참조'라고 할 수 있다. 어떤 변수가 존재하고 그 이름을 저장함으로써 원래의 변수를 '참조'하는 다른 변수가 존재한다면 그 변수를 symbolic reference라고 한다. 반면에 hard reference라는 것도 있는데, 이것은 이름을 통해서가 아니라 실제의 값을 통해서 참조하게 된다. 여기에서는 hard reference에 더 중점을 두어 자세히 설명하려고 한다.
reference와 관련된 용어들에 대해서 잠깐 설명을 하고 넘어가자. reference를 만드는 것을 referece한다고 하면, 반대의 과정, 즉 참조 대상이 되는 변수나 상수의 값을 꺼내오는 것을 dereference한다고 한다. reference의 대상이 되는 것을 thingy(referent)라고 부른다. Perl의 저자인 Larry Wall이 thingy라는 표현을 고집하므로 여기서도 thingy라는 표현을 사용하도록 하겠다.
a) hard reference
hard reference가 가리키는 대상을 Perl에서는 흔히 thingy라고 지칭하는데, 이 thingy에 따라, hard reference를 만드는 방법은 조금씩 달라진다. 대상은 어떤 값이라도 가능한데, 여기서는 이름 있는 변수(named variable)와 서브루틴(named subroutine), 이름 없는 배열(anonymous array), 이름 없는 hash(anonymous hash), 이름 없는 서브루틴(anonymous subroutine), 파일핸들(filehandle)에 대해서 살펴보기로 하자.
우선 대개의 변수와 서브루틴은 이름을 가진다. 그러므로 이러한 일반적인 변수나 서브루틴에 대한 reference가 많이 필요하게 되며, hard reference는 \(backslash)연산자를 사용함으로써 만들 수 있다.
$scalarref = \$foo; # $foo는 일반변수, \는 reference하는 연산자
$constref = \3.24; # hard reference는 값에 대한 reference이다.
$arrayref = \@array1;
$hashref = \%hash2;
$globref = \*STDOUT; # *는 typeglob이며, 모든 타입을 가리킨다.
$subref = \&subroutine3;
간단히 일반화해보면, 어떤 형태의 변수나 상수에 대해서 그 앞에 \연산자를 붙여주면 hard reference가 되는 것이다. reference를 통해서 그 값을 사용하기 위해서는 $, &, @, % 연산자 중의 하나를 reference변수 앞에 붙여주면 된다. reference는 그 대상(thingy)가 어떤 타입인지를 신경 쓰지 않기 때문에, 사용자가 타입 캐스팅을 하듯이 타입연산자인 $, %, &, @ 등의 연산자를 지정하는 것이 필수적이다.
print $$scalarref; # print $foo;와 동일하다.
$$constref # 3.24와 동일하다.
$$hashref{'key1'} # $hash2{'key1'}과 동일하다.
&$subref; # subroutine3를 호출하게 된다.
shift(@$arrayref); # @array1에 대해 shift연산을 하는 것과 같다.
reference변수를 다시 reference할 수 있는데, 이럴 때에는 필요한 만큼 \연산을 붙여 줄 수 있고, 값을 꺼낼 때에는 타입연산자의 수가 \연산자의 수보다 하나 더 많은가를 확인해야 한다.
$multiref = \\\\123; # 123에 대해 \연산을 4번 시행
print $$$$$multiref; # $multiref에 대해서 $연산을 4번 시행
이번에는 이름 없는 배열과 해시와 서브루틴을 참조하는 hard reference를 다루는 법에 대해서 알아보도록 하자. 여기서 이름이 없다는 표현은, 이미 만들어져서 이름을 가지고 있는 변수나 상수의 값을 참조하는 게 아니라 reference를 만들면서 그것이 참조하는 thingy를 만들기 때문에 이름을 지어주지 못했다는 의미이다.
$arrayref = [1, 2, [3, 4, 5]]; # anonymous array reference
$hashref = {
'Meg' => 'Ryan', # anonymous hash reference
'Billy' => 'Christal'
};
$subref = sub {
print "When Harry met Sally\n"; # anonymous subroutine reference
};
위의 예제를 살펴보면, reference는 보이지 않고, 보통 variable에 값을 대입해 준 것처럼 보인다. 그러나 실제 assignment는 다음과 같다. 잘 비교해보도록 하자. 연산자로 사용되는 기호들이 약간씩 다르다는 것을 알게 될 것이다.
@array = (1, 2, (3, 4, 5));
%hash = (
'Meg' => 'Ryan', # anonymous hash reference
'Billy' => 'Christal'
);
&subroutine1;
sub subroutine1 {
print "Sleepless in Seattle\n"; # anonymous subroutine reference
};
두 예제를 비교해 본 바와 같이, anonymous array reference는 [ ]을, anonymous hash reference는 { }를, anonymous subroutine reference는 sub { }를 연산자로 사용한다는 것을 알 수 있다.
b) hard reference in nested data structure
$연산자로 dereference하는 것 이외에도, ->연산자(arrow operator)를 사용해서 array나 hash의 값을 dereference하는 방법도 있는데, 이러한 방법들은 '배열의 배열'을 구현할 때 긴요하게 쓰인다. 다음은 같은 효과를 내는 연산자 사용에 대한 예이다.
$$arrayref[0] = "first";
${$arrayref}[0] = "first";
$arrayref->[0] = "first";
$$hashref{'key2'} = "McLean";
${$hashref}{'key2'} = "McLean";
$hashref->{'key2'} = "McLean";
->연산자는 dereference의 기능을 $연산자보다 더 직관적으로 제시하기 때문에 C프로그래밍에 익숙한 사용자에게 유용할 것이다. 다음은 ->연산자를 이용한 1차원 배열의 원소를 dereference하고, '배열의 배열'내의 원소를 dereference하는 방법을 보인 예이다.
$arrayref->[3] = "list-item1";
$arrayref->[3]->[4] = "multi-dimensional-item2";
$arrayref->[3][4] = "multi-dimensional-item2";
$$arrayref[3][4] = "multi-dimensional-item2";
C프로그래머에게는 '배열의 배열'을 나타내는 위의 표현 중에서 마지막 것이 친숙해 보일 수 있으나, Perl에서는 []연산자가 우선 순위(precedence)가 낮아서 reference가 어떻게 사용되고 있는지를 알아보기가 어렵다는 이유로 권하지 않는 방법이다. 그 위의 두 가지 방법을 이용하여 다중 배열을 나타내기로 한다.
$ref_list_of_list = [
["separator", "delimiter", "terminator"],
["long", "short", "int", "signed", "unsigned"],
["physics", "chemistry", "computer"],
];
print $ref_list_of_list[0][2]; # terminator가 출력된다.
print $ref_list_of_list->[2][1]; # electronics가 출력된다.
print $ref_list_of_list->[1]->[3]; # signed가 출력된다.
만약 for loop를 사용해서 모든 원소를 출력하기를 원한다면, 각 sub list가 가지고 있는 원소의 개수를 알아야 하는데, length()함수를 써서 원소의 개수를 구해 내거나, $#연산자를 사용하여 리스트변수의 마지막 인덱스를 얻을 수 있다.
b) symbolic reference
symbolic reference는 reference가 가리키고 있는(여기서는 thingy가 아님을 유의할 것) 변수의 이름을 문자열로 해서 저장하게 된다. 다시 말해서 변수의 이름을 가진다는 것은 symbolic reference를 만드는 것이다. hard reference가 thingy를 직접 참고하는 것에 반해서 symbolic reference는 변수의 이름을 통해서 그 값에 접근하게 된다. 그러므로 항상 named variable에 대해서만 symbolic reference를 만들 수 있는 것이다.
symbolic reference를 만드는 것은 단순히 변수의 이름을 지정하기만 하면 되며, 그 사용법도 hard reference와 다르지 않다. 타입연산자를 앞에 붙여주면 그 값을 취할 수 있게 된다.
$var1 = "test";
$sr = "var1";
$$sr = "verify"; # $var1 eq "verify"
@var2 = ("hello", "program", "world");
$sr = "var2";
push(@$sr, "perl"); # @var2 eq ('hello', 'program', 'world', 'perl')
7) 배열의 배열, 해시의 배열, 배열의 해시
배열의 배열은 사실상 Perl에서 제공하려고 의도하는 것은 아니다. Perl은 단순히 1차원의 배열만을 제공하는데, C와는 달리 scalar값이 놓일 위치에 vector형 변수가 놓일 수 있으므로 자연스럽게 배열의 배열, 해시의 배열, 배열의 해시 등과 같은 복합적인 data structure를 만들 수 있다.
a) 배열의 배열
다음과 같은 코드를 실행시켜 보자. 아마 아무 출력도 없을 것이다. 그 이유는 Perl이 1차원 배열만을 제공하기 때문에 $list_of_list[0][2]와 같은 형식은 무시되기 때문이다.(-w 스위치를 사용하면 warning을 볼 수 있다.)
@list_of_list = (
("separator", "delimiter", "terminator"),
("long", "short", "int", "signed", "unsigned"),
("physics", "chemistry", "computer"),
);
print $list_of_list[0][2];
print $list_of_list[2][1];
print $list_of_list[1][3];
2차원 배열을 구현하기 위해서는 reference를 이용해야 한다.
@list_of_list = (
["separator", "delimiter", "terminator"],
["long", "short", "int", "signed", "unsigned"],
["physics", "chemistry", "computer"],
);
print $list_of_list[0][2]; # terminator가 출력된다.
print $list_of_list[2][1]; # electronics가 출력된다.
print $list_of_list[1][3]; # signed가 출력된다.
b) 배열의 해시
리스트를 해시 값으로 사용하여 해시를 만드는 것도 비슷한 방법에 의해 가능하다.
%hash_of_list = (
token => ["separator", "delimiter", "terminator"],
type => ["long", "short", "int", "signed", "unsigned"],
science => ["physics", "chemistry", "computer"],
);
print $hash_of_list{'token'}->[1]; # delimiter가 출력된다.
print $hash_of_list{'type'}[0]; # long이 출력된다.
print $hash_of_list{science}; # ARRAY(0xb2074)같은 정보가 출력된다.
print $hash_of_list{science}->[2]; # computer이 출력된다.
print @$hash_of_list{science}; # 아무 것도 출력되지 않는다.
print @{$hash_of_list{science}}; # physicschemistrycomputer 출력
c) 해시의 해시
%hash_of_hash = (
token => {
s => "separator",
d => "delimiter",
t => "terminator"
},
type => {
l => "long",
s => "short",
i => "int"
},
science => {
e => "chemistry",
c => "computer",
},
);
print $hash_of_hash{token}->{s}; # separator 출력
print $hash_of_hash{type}{i}; # int 출력
print $hash_of_hash{science}; # HASH(0xb205c)같은 정보가 출력된다.
다만 주의할 것은 해시나 리스트는 해시의 키(key)로 사용할 수 없다는 것이다. 이유는 key는 단순한 문자열로 취급이 되기 때문이다. 리스트나 해시를 넣는다고 해도 문자열 이상의 의미를 가지지는 못하게 된다.
2. 식(Expression)
1) 기본 연산자
a) 수치 연산자
Perl은 수치에 대해서 사칙연산을 기본적으로 제공한다. +, -, *, /가 그에 해당하는 연산자이다. 그리고 FORTRAN과 같이 **에 의한 거듭제곱 연산도 가능하다. 나머지를 구하는 연산도 있는데, %를 연산자(operator)로 사용하며, 피연산자(operand) 모두를 정수로 취급한다. 반면에 나누기 연산자인 /는 피연산자 모두를 실수로 취급한다. 논리연산자인 <, <=, ==, >=, >, !도 사용 가능하다.
다음은 수치 연산자의 사용 예이다.
2 + 3 # 5
5.1 - 2.4 # 2.7
3 * 12 # 36
14 / 2 # 7
10.2 / 0.3 # 34
10 / 3 # 3.33333...
if (3 > 4) {
print "3 is greater than 4.\n";
} else {
print "3 is not greater than 4.\n"; # 비교문이 거짓이므로 여기가 실행됨
}
b) 문자열 연산자
문자열 연산자에는 C에서는 볼 수 없는 연산자들이 많이 등장한다. 우선은 문자열들을 붙이는 연산자인 .(dot)이 있고, 문자열을 정수번 반복해서 붙여주는 x연산자도 있다. 다음의 예제를 참고하도록 하자.
$b = "Hello, ";
$c = "world";
$a = $b . $c; # $a = "Hello, world"
$a = "boy";
$b = $a x 3; # $b = "boyboyboy"
$c = $a x 4.2; # $b = "boyboyboyboy", 4.2는 4로 cast된다.
c) 대입연산자(assignment operator)
대입연산자에는 C와 마찬가지로 =이 기본적인 연산자이다. 이밖에도 C에서 사용하는 대입연산자들은 거의 Perl에서 채택되어져 있다. +=, -=, *=, /=, &=, |=. ^=, %=가 그 예이다. 그 밖에도 .=, x=, ||=, **=, <<=, >>=의 연산자들이 있다. 이와 같은 대입연산자들은 %연산, .연산, x연산, ||연산을 수행한 후에 그 결과를 대입하는 것이므로 보충 설명이 없어도 이해에 어려움이 없을 것이다.
$a *= 3; # $a = $a * 3;
$b .= "\n"; # $b = $b . "\n"
$c ||= 2; # $c = $c || 2, $c가 2가 아니면 2의 값을 대입한다.
d) 연산자 우선 순위와 결합법칙
여러 연산자들의 결합순위와 우선 순위를 다음의 표로 정리해놓았다. 위쪽에 있는 연산자일수록 아래쪽 연산자들보다 우선 순위가 높다. 같은 줄에 있는 연산자들은 같은 우선 순위 가지게 되고 결합순위에 따라 연산의 순서가 정해진다.
| 결합순위 | 연산자 |
| 없음 | ++ -- |
| 우 | ! ~ -(단항연산) |
| 우 | ** |
| 좌 | =~ !~ |
| 좌 | * / % x |
| 좌 | + -(이항연산) . |
| 좌 | << >> |
| 없음 | file test operator |
| 없음 | named unary operator |
| 없음 | < <= > >= lt le gt ge |
| 없음 | == != <=> eq ne cmp |
| 좌 | & |
| 좌 | | ^ |
| 좌 | && |
| 좌 | || |
| 없음 | .. |
| 우 | ?:(삼항연산) |
| 우 | 대입 연산자 (+= -= 등) |
| 좌 | , |
| 없음 | list 연산자 |
e) 수치와 문자열 상호변환
Perl은 수치와 문자열, 정수와 실수 사이의 변환을 자동으로 해준다. 수치 앞 뒤쪽에 오는 쓸데없는 문자들을 자동으로 제거해주므로 다음과 같은 연산이 가능하다.
$a = " 3.5abcd" * 4;
print $a; # 3.5 * 4 = 14가 출력된다.
$b = "3" + "4"; # $b = 7
Perl이 자동으로 변환해 주는 것은 문자열 또는 수치가 이중적인 의미를 가질 때, 앞쪽이나 뒤쪽에 위치하는 연산자가 필요로 하는 피연산자가 수치인가 문자열인가를 결정할 수 있기 때문이다.
print "boy" . (3 * 2); # boy6가 출력된다.
print "boy" x (3 * 2); # boyboyboyboyboyboy가 출력된다.
괄호 안의 3 * 2이 먼저 수치로서 계산이 된다. 수치로 인식되는 이유는 *이 수치를 피연산자로 가지기 때문이다. 다음에는 문자열을 결합시켜주는 . 연산자를 만나게 되므로 (3 * 2)의 결과인 6을 문자열로 변환시켜서 인식하게 된다. 이러한 방식으로 자동변환이 일어나게 되므로 프로그래머는 사소한 것에 신경 쓰지 않아도 된다.
2) 추가 연산자
또 하나 프로그래머가 매달릴 필요가 없는 것은 연산자를 연산자로 볼 것인가 함수로 볼 것인가의 문제인데, Perl에서 제공되는 대개의 연산자는 연산자이면서 함수로 볼 수 있기 때문에 C처럼 ()를 반드시 써 줄 필요가 없다.
a) scalar operator
| rand $a | 0과 $a 사이의 임의의 값(random number)을 반환한다. 0이상 $a미만의 범위의 소수를 구하게 된다. |
| srand $a | random number를 만들어 낼 때 사용하는 seed값을 지정한다. srand(time^$$)처럼 현재시간을 알려주는 time연산자와 현재 프로세스의 번호를 지정하는 $$변수를 넣어서 사용하기도 한다. |
| substr $a, $b, $c | $a라는 문자열에서 $b의 offset위치에 $c개만큼의 원소를 지정하게 된다. substr을 이용해서 $a에 새로운 값을 넣어주거나 $a에서 원소를 꺼내올 수 있다. $c부분은 생략 가능하다. |
| index $a, $b, $c | 문자열 $a에서 $b가 나타나는 위치(offset)을 알려준다. $c부분은 찾기 시작하는 위치를 지정하는 것인데, 생략되면 0의 값이 대신 사용된다. |
| chop $a | chop은 $a의 마지막 글자를 제거하는 연산자이며 Perl 5에서는 다음의 chomp을 권장한다. $a는 리스트라도 처리할 수 있다. |
| chomp $a | chomp는 chop의 안전한 버전이며, $a의 마지막 글자가 $/변수($INPUT_RECORD_SEPARATOR, $RS)의 값을 가지면 제거하는 역할을 한다. 대개는 입력에 붙어서 들어오는 newline character를 제거할 때 사용한다. |
b) vector operator
| shift @a | 리스트 @a의 가장 앞쪽에 있는 원소를 꺼내준다. |
| unshift @a, $b | $b를 @a의 가장 앞쪽에 쑤셔 넣어 준다. |
| pop @a | @a의 가장 뒤쪽에 있는 원소를 꺼내준다. |
| push(@a, $b) | @a의 가장 뒤쪽에 $b를 추가해준다. |
| splice @a, $b, $c, @d; | @a의 offset이 $b되는 곳에서 $c개의 원소를 지정할 때 사용한다. @d가 사용되는 경우에는 @d를 $c개의 원소와 바꾸어준다. @d가 생략되면 $c개의 원소를 반환한다. |
| keys %a | 해시 변수 %a의 key를 모아서 리스트 형태로 반환한다. |
| $a .. $b | ..은 범위연산자(range operator)라고 하는데, $a에서 $b까지의 값을 리스트 형태로 반환한다. $a와 $b에 들어갈 수 있는 값은 정수나 문자이다. 문자열을 사용하면 그 사이에 존재할 수 있는 모든 문자열 조합을 만들어 주기도 하는데, 시스템의 자원을 낭비하기 쉬우므로 조심해야 한다. |
| , | comma(,) 연산자는 리스트에서 separator로 사용되는 comma와는 다른 의미를 가진다. comma 연산자는 ,뒤쪽의 값을 반환한다. ,로 여러 개의 값이 나열되면 마지막 값이 리턴 된다. |
| sort @a | 리스트변수 @a를 정렬해준다. sort의 기준을 제시하는 비교함수나 블럭을 지정할 수도 있는데, 리스트 앞에 지정해준다. 이 때 비교함수나 블럭에서는 <=>, cmp 연산자와 논리연산자등을 사용하여 +1, -1, 0등의 값을 반환하도록 한다. |
| reverse @a | 리스트의 원소의 순서를 반대 방향으로 바꾸어준다. |
| grep PATTERN, @a grep FILETEST, @a |
리스트변수 @a를 읽어들여 패턴매치나 파일 테스트를 해서 성공할 경우, 그 리스트의 원소인 line이나 string을 반환한다. |
| join $b, @a | @a의 원소들을 $b를 delimiter로 하여 묶어 하나의 문자열로 반환한다. |
| split PATTERN, $a, $b | 문자열 $a를 PATTERN에 나오는 character를 delimiter로 해서 나누어 리스트형태로 반환한다. $b를 사용하게 되면 그 값에 해당하는 개수까지 원소들을 생성해준다. |
c) file test operator
다음은 파일에 대한 조건식을 만드는 operator을 정리한 표이다. 다음의 테스트는 참/거짓의 값을 가지거나 특정한 결과 값을 return해 준다.
| -r | 파일을 읽을 수(readable) 있는가? |
| -w | 파일을 쓸 수(writable) 있는가? |
| -x | 파일을 실행시킬 수(executable) 있는가? |
| -o | 파일이 $euid의 사용자 소유인가? |
| -R | 파일이 $uid의 사용자에 의해 읽혀질 수 있는가? |
| -W | 파일이 $uid의 사용자에 의해 쓰여질 수 있는가? |
| -X | 파일이 $uid의 사용자에 의해 실행가능한가? |
| -O | 파일이 $uid의 사용자 소유인가? |
| -e | 파일이 존재하는가? |
| -z | 파일의 크기가 0인가? |
| -s | 파일의 크기(size) |
| -f | 파일이 정규파일(디렉토리가 아닌)인가? |
| -d | 파일이 디렉토리인가? |
| -l | 파일이 symbolic link인가? |
| -p | 파일이 FIFO와 같은 named pipe인가? |
| -S | 파일이 socket인가? |
| -b | 파일이 block special file인가? |
| -c | 파일이 character special file인가? |
| -t | filehandle이 tty(terminal)에 열려 있는가? |
| -u | setuid bit이 켜져 있는 파일인가? |
| -g | setgid bit이 켜져 있는 파일인가? |
| -k | sticky bit이 켜져 있는 파일인가? |
| -T | 파일이 텍스트(text) 파일인가? |
| -B | 이진(binary) 파일인가? |
| -M | file의 최종 수정 시간(modification time, mtime) |
| -A | file의 최종 접근 시간(last access time, atime) |
| -C | file의 최종 변경 시간(inode change time, ctime) |
다음은 file test를 이용한 조건식의 예이다.
while (<>) {
chomp; # default input string의 마지막 \n을 제거한다.
next unless -f $_; # 정규파일이 아닌 경우에는 다음으로 넘어간다.
}
stat($file);
print "Readable\n" if -r _; # _는 마지막으로 사용된 filehandle이다.
print "Writable\n" if -w _; # readable, writable, executable한지 체크한다.
print "Executable\n" if -x _;
&newfile if -M $file < 5; # mtime이 5일 이내라면 서브루틴을 호출한다.
3) 기본 입출력 연산자
입출력이란 프로그램이 자료를 외부세계에서 넘겨받고 그 자료를 처리한 결과를 외부세계에 넘겨주는 과정을 의미한다. Perl에서 가능한 방법은 파일을 이용한 것이고, 프로그래머는 filehandle이라는 것을 가지고 파일을 다룰 수 있게 된다. 파일을 열어서 filehandle을 지정하는 것은 open함수를 사용하면 되고, 더 이상 사용하지 않게 된 파일을 닫고 filehandle의 사용을 포기하는 것은 close함수를 이용하면 된다.
그러나 입출력 과정에 filehandle을 매번 사용한다는 것은 프로그램 작성에 상당한 불편을 안겨줄 것이다. 그리하여 Perl에서는 Unix시스템과 마찬가지로 표준입력(STDIN), 표준출력(STDOUT), 표준에러(STDERR)를 제공한다. 표준입력이란 키보드를 통해 자료를 입력받거나, 다른 프로그램에서 파이프나 redirection을 통해 자료를 넘겨받는 것이다. 반면에 표준출력은 print 연산이나 printf를 통해서 화면으로 결과를 출력하는 것이고, 표준에러는 화면에 에러메시지를 보여주는 것이다.
a) 입력
일반적으로 키보드로부터의 입력은
$input = <STDIN>;
@input = <STDIN>;
과 같은 형태로 받아들일 수 있다. $input이나 @input에는 사용자가 키보드를 통해 눌렀던 모든 키 입력이 문자열 또는 리스트의 형태로 저장된다.
Perl에서 즐겨 사용되는 입력방식에는 다음과 같은 것들이 있다. 짧은 코드에서 긴 코드까지 모두 같은 효과를 가지며, 문맥적으로 같은 의미를 가진다.
print while <STDIN>
print $_ while <STDIN>;
print $_ while definded($_ = <STDIN>);
for (;<STDIN>;) { print; }
for (;<STDIN>;) { print $_; }
while (<STDIN>) { print; }
while (<STDIN>) { print $_; }
while (defined($_ = <STDIN>)) { print $_ };
$_는 default input string을 저장하는 변수로서 대개의 연산자에서 생략 가능하다. 거꾸로 말해서, 연산자만 나오는 경우는 대개 $_를 염두에 둔 것이라고 볼 수 있다.
STDIN같은 표준입출력에 관련된 filehandle은 굳이 open의 과정이 필요 없으나, 일반적인 파일에 대한 filehandle은 open의 과정이 명시되어야 한다.
open(FILE, "test.c");
$_ = <FILE>;
print;
이 예제는 test.c라는 파일을 FILE이라는 filehandle을 통해서 다루게 되고 default input string에 한 줄 입력을 받아서 그것을 다시 출력해주는 작업을 하게 된다. 그러나 대개는 한 줄만 입력을 받는 게 아니라 파일 전체에 대해서 여러 줄의 입력을 받아야 하므로 loop안에서 사용하거나 리스트에 저장했다가 shift연산자를 사용하여 꺼내어 사용할 수 있다. 그러나 리스트에 파일의 큰 내용이 저장되는 것은 시스템에 부하를 주게 되므로 loop를 사용하는 방법을 익히도록 하자.
while ($input = <FILE>) {
print "/* $input */\n";
}
이 예제는 FILE을 통해 $input에 입력을 받고 그 line을 comment기호로 감싸는 작업을 수행하는 것이다.
Perl 프로그램이 filter로 사용되는 게 아니라면 대개는 프로그램의 argument로 파일 이름을 넘겨받아 사용하게 되는데, 이것은 아주 간단하다. 다음은 argument로 넘겨진 모든 파일을 열어서 한 줄씩 입력을 받아서 출력하는 예이다.
while (<>) {
print;
}
이 코드는 다음과 동일한 의미를 가진다.
@ARGV = ('-') unless @ARGV;
while ($ARGV = shift) {
open(ARGV, $ARGV) or warn "Can't open $ARGV: $!\n";
while () {
print;
}
}
argument로 넘겨받는 파일이름에 대해서는 신경쓸 필요 없이 <>만 사용하면 각 파일에 대해서 open하고 읽어들이는 과정이 모두 자동적으로 실행되는 것이다.
b) 출력
print연산을 사용하는 경우에는 default로 출력의 방향이 STDOUT으로 정해진다. 그러므로 다음의 세 문장은 같은 의미를 가진다.
print "Hello world\n";
print STDOUT "Hello world\n";
print STDOUT Hello, " ", world, "\n";
STDOUT뒤에 ,를 찍지 않도록 주의하자. STDOUT은 출력 대상이 아니라 출력의 방향이기 때문이다.
특정 파일에 대해서 출력을 하기 위해서는 미리 쓰기 mode로 open을 해야 하고 그 이후에 print 연산에 출력 방향으로 그 파일의 filehandle을 지정하면 된다.
open(OUTPUT, "> output.log");
print OUTPUT "Result : All men are alive.\n");
shell에서 사용하던 방식의 token을 이용한 출력방법도 있다. 이것을 'HERE DOCUMENT' 문법이라고 하며 token을 일종의 quote로 생각하는 것이다. 여러 줄에 걸쳐진 출력에 대해서 문서를 쓰듯이 출력할 수 있다는 게 장점이다.
다만 이 HERE DOC방법에서 주의할 것은, 1) << 뒤에는 스페이스가 없어야 한다는 점, 2) 첫번째 delimiter 뒤에는 ;가 따라와야 한다는 점, 3) 두번째 delimiter 앞뒤에는 공백이 없어야 한다는 점이다.print OUTPUT <
print 연산자는 EOF라는 토큰을 quote로 간주하고 두개 사이의 텍스트를 지정된 출력방향으로 내보내게 된다. 토큰에 따라서 보다 정교한 출력 방법이 있는데, 여기서는 몇 가지만 더 살펴보기로 하겠다.
print << "" x 10
Hello, world!
이 예제는 quote가 null string이므로(그러므로 ""조차 생략 가능하다.) 다음 줄만을 출력 대상으로 삼게 되고 print 연산을 10번 수행하게 된다.
print << `ANYTOKEN`
id
echo hello
ANYTOKEN
token을 감싸는 것이 back-quote(backtick)임에 유의하라. back-quote는 명령을 실행시켜주는 역할을 한다. 그러므로 두 토큰 사이에 존재하는 id와 echo hello라는 명령이 실행된 결과가 출력되게 된다.
c) 에러 출력
에러는 파일로 보낼 수도 있지만, STDERR로 모아서 보내는 것이 일반적이다. 그러므로 print의 출력방향을 STDERR로 명시하면 된다.
print STDERR "Can't find such a file!\n";
4) 비교 연산자
Perl에서는 문자열에서 사용되는 논리연산자와 수치에서 사용되는 논리연산자가 따로 제공된다. 다음의 표를 참조하라.
| 비교 표현식 | 수치연산자 | 문자열연산자 |
| 같은가? | == | eq |
| 같지 않은가? | != | neq |
| 보다 작은가? | < | lt |
| 보다 큰가? | > | gt |
| 같거나 작은가? | <= | le |
| 같거나 큰가? | >= | ge |
| 같지 않은가? | <=> | cmp |
<=> 연산자와 != 연산자의 차이점은 != 연산자의 결과는 1(참) 또는 0(거짓)인데 반해서, <=> 연산자의 결과는 좌측 피연산자에서 우측 피연산자를 뺀 결과로 -1의 값을 가질 수 있다.
수치에 관한 비교연산자는 굳이 설명하지 않더라도 C프로그래밍을 조금이라도 해 본 사람이라면 누구나 알 수 있으리라 생각해서 설명을 생략하였다. 그러나 문자열에 관한 비교연산자는 다소 생소할 것이다. string을 비교하는 것은, 두 문자열이 사전에 쓰여져 있다면 어떤 문자열이 상대적으로 앞쪽에 위치하는가에 따라 결정된다. 사전에 쓰이지 않는 글자라면 ASCII코드 값에 따라 결정되게 된다. 다음은 참인 조건식이다.
"" lt "1"
"1" lt "A"
"A" lt "a"
숫자는 영문자보다 앞쪽에 위치하고 대문자가 소문자보다 앞쪽에 위치한다. null character가 다른 어떤 글자들보다 앞서기 때문에 다음과 같은 조건식도 참임을 알 수 있다.
"Korea" lt "Korean"
그리고 다음의 예제는 문자열에 관계되는 논리연산자를 사용한 예이다.
$a = "Jones"; # Clinton이라는 단어가 Jones라는 단어보다 사전에서
$b = "Clinton"; # 앞쪽에 위치하므로 ("Jones" lt "Clinton")은 거짓이다.
if ($a lt $b) {
print "$a is less than $b.\n";
} else {
print "$a is greater than or equal to $b.\n";
}
5) 논리연산자(logical operator)
bitwise operator로는 C와 마찬가지로 &(bit AND), |(bit OR), ^(bit XOR)등의 연산자 등이 제공된다. 논리연산자 또한 C와 마찬가지로 &&와 ||가 사용되는데, short-circuit 연산자라는 특성을 활용한 기법이 Perl에서 자주 사용된다.
open(FILE, $filename) || die "Can't open $filename!\n";
open(FILE, $filename) && (@data =) && close(FILE) ||
die "Can't open $filename!\n";
이 문장은 file을 open하고 읽어들이고 close하는 모든 과정이 성공적으로 수행되지 못하고 3개의 피연산자인 open, read, close 문장 중의 어떤 하나라도 실패하게 되면 die 문장이 수행되는 것이다.
&&와 ||는 기호가 아니라 and 또는 or로 대신 사용할 수 있다.
open(FILE, $filename) or die "Can't open $filename!\n";
6) 이름 있는 단항 연산자(named unary operator)
다음의 named unary operator들은 함수처럼 각각의 이름으로 사용되는 단항 연산자이다. named unary operator는 어떤 binary operator(이항 연산자)보다는 우선 순위가 높다. 그래서 expression(표현식)을 쓸 때에는 피연산자에 대한 연산자들의 우선 순위를 충분히 고려하는 것이 바람직하다. 모호할 경우에는 반드시 ()를 사용하여 우선 순위를 명시하는 것이 안전하다.
| alarm | caller | chdir |
| chroot | cos | defined |
| delete | do | eval |
| exists | exit | exp |
| gethostbyname | getnetbyname | getpgrp |
| getprotobyname | glob | gmtime |
| goto | hex | int |
| lc | lcfirst | length |
| local | localtime | log |
| lstat | my | oct |
| ord | quotemeta | rand |
| readlink | ref | require |
| reset | return | rmdir |
| scalar | sin | sleep |
| sqrt | srand | stat |
| uc | ucfirst | umask |
| undef |
3. Control Structure(제어 구조)
제어구조에서 가장 중요한 것은 조건식(conditional expression)이다. 조건식이 참일 때와 거짓일 때, 프로그램의 제어(control)이 분기해야 하기 때문이다. Perl에서 조건식이 거짓이 되는 경우는 계산의 결과가 다음과 같을 때이다.
0 # 수치 0
"" # null string
undef # null string
이런 경우를 제외한 모든 경우는 참인 조건식으로 간주된다.
1) if
if/else 구문은 C의 문법과 비슷하다. 다만 조건식의 결과에 따르는 문장은 반드시 블럭 안에 위치해야 한다.
if (조건식) {
# 참일 때 실행하는 문장들을 쓴다.
} else {
# 거짓일 때 실행하는 문장들을 쓴다.
}
두개 이상의 조건식을 나열하기 위해서는 다음과 비슷한 형식으로 조건문을 구성해야 한다.
if (조건식1) {
# 조건식1이 참일 때 실행되는 문장들
} elsif (조건식2) {
# 조건식2가 참일 때 실행되는 문장들
} elsif (조건식3) {
# 조건식3이 참일 때 실행되는 문장들
} else {
# 모든 조건식이 참이지 않을 때 실행되는 문장들
}
다음은 if/else를 이용한 조건문의 예제이다.
print "How old are you? ";
$a = <STDIN>; # 사용자에게 입력을 받는다.
chop($a); # 입력의 마지막 글자(newline)을 떼어낸다.
if ($a < 10) {
print "You're a child.\n";
} elsif ($a < 20) {
print "You're a teenager.\n";
} else {
print "You're so old.\n";
}
실행할 문장이 하나일 때에는 매번 { }로 블럭을 지정하여 쓰기가 번거롭다. 이럴 때에는 if 조건식을 문장 뒤쪽에 위치시킬 수 있다.
print "$a is equal to $b.\n" if $a eq $b;
2) unless
unless는 조건식의 결과를 if와는 반대로 해석한다. 다음의 형식을 참고하라
unless (조건식) {
# 조건식이 거짓일 때 실행되는 문장들
} else {
# 조건식이 참일 때 실행되는 문장들
}
다음은 if에서 나왔던 예제와 같은 결과를 보여주는 예제이다.
print "How old are you? ";
$a = <STDIN>;
chop($a);
unless ($a < 20) {
print "You're so old.\n";
} elsif ($a >= 10) {
print "You're a teenager.\n";
} else {
print "You're a child.\n";
}
3) while/until
while문과 until문은 다음과 같은 형식을 가진다.
while (조건식) {
# 조건식이 참인 동안은 계속 실행될 문장들
}
until (조건식) {
# 조건식이 거짓이 될 때까지 계속 실행될 문장들
}
while과 until의 관계는 if와 unless의 관계와 유사하다. 다음은 같은 결과를 보여주는 while/until구문의 예제이이다.
$a = 0;
while ($a < 10) {
$a++;
print "$a\n"; # 1 2 3 4 5 6 7 8 9 10이 차례대로 출력된다.
}
$a = 0;
until ($a >= 10) {
$a++;
print "$a\n"; # 1 2 3 4 5 6 7 8 9 10이 차례대로 출력된다.
}
continue 블럭을 사용하여 loop를 돌 때마다 실행해주는 부분을 분리하여 사용할 수 있다. 다음은 while/continue 구문의 형식이다.
while (조건식) {
# 조건식이 참일 때 실행되는 문장들
} continue {
# 조건식에 관계되는 변수들의 증감식(auto-in/decrement)
}
다음의 예제는 위쪽의 while/until의 예제와 같은 결과를 보여준다. 그러나 위쪽의 형식보다는 보다 안전한 구문 표기법으로 볼 수 있다. continue 블럭 안에서만 증감식이 구성되는 경우 변수의 추적이 용이하다.
$i = 1;
while ($i <= 10) {
print "Count-up: i = $i\n";
} continue {
$i++;
}
4) for
for구문의 기본적 형식은 C구문과 동일하다. 그러나 Perl만의 확장된 형식도 소개될 것이다.
for (초기화; 조건식; 증감식) {
# 조건식이 참일 동안 실행될 문장들
}
가장 먼저 초기화 문장이 실행된다. 그리고는 조건식을 검사한 후에, 참이면 블럭내의 문장을 실행하고 블럭이 끝나면 증감식을 실행한다. 그리고 다시 조건식을 검사하는 일부터 다시 반복한다.
다음은 1부터 10까지의 합을 계산하는 예제이다.
$sum = 0;
for ($i = 1; $i <= 10; $i++) {
$sum += $i; # $sum = $sum + $i, $sum에 $i의 값을 더한다.
}
print "Sum is " . $sum . "\n";
이제 C를 뛰어넘는 Perl의 for 구문에 대해서 살펴보도록 하겠다. 범위연산자(range operator)인 ..를 사용한 형식은 다음과 같다.
for ($a .. $b) {
# $a값부터 $b값까지 $b-$a+1번 수행되는 문장들
}
범위연산자 ..대신에 list연산자인 ,를 사용하여 원소를 나열하는 것도 가능하다. 이와 같은 list 형의 변수나 값을 사용하는 for구문은 단순히 정수번 수행되도록 하는 데만 사용되는 것은 아니다. 다음의 예제는 for문이 C의 for구문과는 다르게, 더 유연한 형식을 가짐을 보여준다.
for (10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0) {
print "Count-down: " . $_ . "\n"; # $_에는 10 .. 0이 각각 들어간다.
}
for (0 .. 10) {
print "Count-up: " . $_ . "\n"; # $_에는 10 .. 0이 각각 들어간다.
}
그러나 list가 아니라 범위 연산자를 사용한 경우에는, 수열이 줄어드는 조건식은 거짓으로 결정된다.
for (10 .. 1) {
print "Count-down: " . $_ . "\n"; # 이 loop는 실행되지 않는다.
}
이런 경우에는 reverse 연산자를 이용하여 원하는 결과를 얻을 수 있다.
for (reverse 1 .. 10) {
print "Count-down: " . $_ . "\n";
}
5) foreach
foreach구문은 csh에서 사용되었던 구문인데 C프로그래머에게는 약간 생소할 수 있지만 vector형 자료를 많이 다루는 작업에서는 꼭 필요한 제어 구조이다. Perl에서는, foreach는 for의 동의어이다.
foreach scalar변수 (list형의_변수_또는_값) {
# scalar변수에 대한 조작을 하는 문장들
}
list형의 변수 또는 값에서 하나씩 scalar변수에 대입하여 list내의 각 원소들에 대해서 각각 비슷한 유형의 처리를 해 줄 수 있다. 다음은 foreach를 사용하여 현재 디렉토리에 존재하는 파일들의 permission을 바꾸어주는 예제이다.
foreach $f (`ls`) {
chmod 0755, $f; # chmod는 file의 permission mode를 바꾸어주는 연산자
}
다음은 hash 형 변수에서 keys 라는 연산자를 통해 array을 얻어내는 방식으로 환경변수의 이름과 값을 출력하는 예제이다. foreach구문은 이러한 방식으로 사용되기 때문에 index가 순차적이지 않은 vector형 변수를 다루는데 있어서 C의 for구문보다 효율적이고 직관적이다.
foreach $key (keys %ENV) {
print "Key:$key, Value:$ENV{$key}\n";
}
6) do/while, do/until
do/while 또는 do/until구문은 위에서 설명했던 while이나 until구문을 참고하면 그다지 어려운 개념은 아닐 듯 싶다. 많은 C프로그래머들이 알고 있다시피 do로 시작하는 구문의 while구문(until구문)과의 차이점은 조건식이 loop보다 먼저 수행되는가 아니면 loop가 최소한 한 번 수행된 후에 수행되는가의 차이이다. do구문에서는 조건식이 loop 뒤쪽에 제시되므로 최소한 1번은 조건과는 상관없이 수행됨을 알 수 있다.
do구문의 형식은 다음과 같다.
do {
# 조건식이 참인 동안에 실행될 문장들
} while (조건식);
do {
# 조건식이 참이 될 때까지(거짓인 동안에) 실행될 문장들
} until (조건식);
다음은 같은 결과를 보여주는 do/while, do/until구문의 예제이다.
$i = 0;
do {
print "Count-up: $i\n";
$i++;
} while ($i <= 10);
$i = 0;
do {
print "Count-up: $i\n";
$i++;
} until ($i > 10);
7) goto
C프로그램과 마찬가지로 문장이나 블럭에 label을 지정할 수 있는데, label이 지정된 곳이 loop 내부가 아니라면 어디로든 제어(control)를 옮길 수 있다. 그러나 이러한 goto의 사용은 적합한 곳으로의 제어 이동이라 해도 바람직하지는 않다. Perl에서는 다른 언어들보다 더 풍부한 제어 구조(control structure)를 지원한다는 것을 유념하길 바란다. 다음은 goto의 형식이다.
goto LABEL;
예제를 참고하도록 하자. OUT이라는 label은 건너뛰고 IN이라는 label이 위치한 곳으로 제어가 옮겨진다.
goto IN;
OUT:
print "This message is printed to standard out.\n";
IN:
print "Enter your input : ";
$input = <STDIN>;
goto의 가장 큰 문제점은 LABEL이 goto의 앞쪽, 뒤쪽 어디에 존재하는지 알 방법이 없기 때문에, 프로그램의 전체를 검색하게 된다는 것이다. Perl 프로그램이 커짐에 따라 검색시간이 늘어날 것은 자명하다.
그러나 goto는 지정해주는 변수 값에 따라 동적으로 제어가 넘겨지는 label을 바꿀 수 있다. 다음의 예제는 $i의 값에 따라 goto가 실행될 label이 여러 개 나열될 수 있음을 보여준다.
goto ("LINE0", "LINE1", "LINE2")[$i];
일반적으로 goto의 피연산자로 따라오는 label은 0부터 번호가 매겨지지만, $[의 값을 1로 지정하면 label은 1번부터 번호가 매겨진다. (특수한 변수에 관련해서 살펴보았듯이, $[은 array의 index 시작 번호를 지정하는 global special variable이다. )
8) next, last, redo
loop 내에서 제어를 옮기는 방법이 존재한다. next, last, redo가 그것이며, C프로그램과 비교하자면, next는 continue, last는 break와 비슷한 기능을 가지고 있다.
a) next
next는 loop내의 제어를 다음 차례로 넘기게 된다. C의 continue문과 같은 기능을 한다. 그러나 Perl에서의 continue 블럭과 C의 continue문장은 다른 의미를 가지게 된다. 다음 예제를 통해 next의 사용법을 익히도록 하자.
LINE: while (<STDIN>) {
next LINE if /^#/; # 주석은 건너뛴다.
next LINE if /^$/; # null line도 건너뛴다.
} continue {
$count++; # next에 의해 제어가 옮겨져도 count는 증가한다.
}
LABEL이 어디에 위치하든 간에 next문을 만나게 되면 continue블럭에서 증감식을 수행한 후에 그 label로 제어를 옮기게 됨을 알 수 있다. C의 continue와 같이 단순하게 작동시키는 것도 어려운 일이 아니다.
for ($i = 0; $i < 10; $i++) {
if ($i == 5) {
next;
}
print "$i\n";
}
b) last
last는 loop를 빠져나오는 기능을 수행한다. loop를 빠져나오는 것이기 때문에 continue블럭내의 문장들도 당연히 수행되지 않는다. label이 loop의 가장 앞쪽을 가리킨다고 해서 loop를 다시 반복하는 것이 아님에 유의하라.
LINE: while (<>) {
last LINE if /^$/; # null string을 만나면 종료한다.
print; # default input string인 $_를 출력한다.
}
위의 예제에서는 LINE이라는 label을 명시하지 않아도 loop를 종료할 수 있다. 그러나 loop 밖의 label을 지정하는 경우에는 compile-time error가 발생하게 된다.
OUT:
print "Hello\n";
LINE: while (<>) {
last OUT if /^$/; # OUT를 찾을 수 없어서 에러가 발생한다.
print;
}
C의 break와 마찬가지로 last는 다중 loop에서 last 구문이 속해 있는 loop만을 빠져나올 뿐이다.
for ($i = 0; $i < 10; $i++) {
for ($j = 0; $j < 10; $j++) {
print "($i, $j)\n";
last if $j >= 5;
}
# loop내의 last에 의해 제어가 옮겨지는 곳은 바로 이곳이다.
}
c) redo
redo문장은 loop를 새로 시작하는 기능을 가진다. C에서는 볼 수 없었던 기능이다. redo도 next나 last와 같은 형식을 가지고 비슷한 역할을 한다. 다음의 예제를 보고 이해하도록 하자.
while (<>) {
chomp;
if (s/\\$//) {
$_ .= <>;
redo;
}
print;
}
label을 사용하는 다음 예제는 앞의 예제와 같은 의미를 가진다.
LINE: while ($line =) {
chomp($line);
if ($line =~ s/\\$//) {
$line .=;
redo LINE;
}
print $line;
}
이 두 예제는 backslash(\)로 끝나는 line을 만나면 다음 line을 이번 line에 붙여주는 작업을 수행한다.
4. 서브루틴(Subroutine)
1) 정의와 사용
서브루틴이란 C의 함수(function)와 같은 것으로 볼 수 있다. 서브루틴은 실행 가능한 문장들을 포함하기는 하나, 정의 자체는 실행가능한 문장은 아니고 script 어느 곳에나 위치할 수 있다. 서브루틴의 정의와 호출은 다음과 같은 형식을 가진다.
sub 서브루틴이름 서브루틴블럭 # 서브루틴의 정의
&서브루틴이름; # 서브루틴의 호출
do 서브루틴이름;
서브루틴을 호출하기 위해서 기본적으로 & 연산자를 사용한다. 그러나 서브루틴은 do, require, use, eval등의 연산자를 통해 사용될 수 있다. & 연산은 괄호를 사용하거나 이미 정의된(또는 이미 import된) 경우 생략 가능하다.
다음은 서브루틴의 사용 예이다.
sub sum {
$sum = 0;
for ($i = 0; $i < 10; $i++) {
$sum += $i;
}
print $sum;
}
∑
여기서 대부분의 눈치 빠른 프로그래머라면 C와는 달리 argument가 넘겨지는 것이 formal하게 정의되어 있지 않음을 깨달았을 것이다. Perl에서는 default input list로 argument를 주고받을 수 있다. 서브루틴 내부에서 argument를 받아서 사용할 parameter들은 다음에서 살펴 볼 local이나 my 연산자를 이용하여 초기화시킬 수 있다. 다음의 예제는 argument를 parameter로 넘겨받는 방법을 설명하고 있다.
sub sum {
local($a, $b) = @_; # default input list인 @_에서 넘겨받아
$sum = $a + $b; # $a와 $b에 차례대로 저장한다.
}
print ∑(1, 5); # 마지막으로 대입된 변수가 return된다.
sub listdouble {
local(*list) = @_; # @_를 다시 list에 넣으려면 *var로 받아서
foreach $e (@list) { # @var의 형태로 사용하면 된다. *는 어떤 형태의
$e *= 2; # 변수로도 사용될 수 있는 변수기호이다.
}
}
@array = (1, 2, 3, 4, 5);
&listdouble(@array); # @array eq (2, 4, 6, 8, 10)
2) my와 local
my와 local은 변수의 사용범위(scope)를 지정하는 modifier이다. local은 변수를 dynamic variable로 만들고, my는 변수를 lexical variable로 만들어준다. dynamic variable의 경우 그 변수가 선언된 블럭 내에서 호출된 서브루틴에서 보이게 된다. 그러나 lexical variable은 그 블럭을 벗어나게 되면 전혀 사용할 수 없게 된다.(lexical variable은 C함수 내부의 일반적인 변수의 성질과 같다.)
sub power {
my ($num, $count) = @_;
my $result = 1;
if ($count == 1) {
$result = $num;
} else {
$result = power($num, --$count) * $num;
}
}
$val = power(2, 7);
print "value=$val\$";
이 예제는 my를 사용한 거듭제곱을 계산하는 서브루틴이다. 2의 7승을 계산하여 128을 돌려주기 위해 recursion을 사용하였다.
5. 패턴 매칭(Pattern Matching)
'패턴 매칭'(pattern matching)이란, 주어진 단락(paragraph) 속에서, 제시된 표현형인 pattern이 일치하는 경우, 일치하는 부분(line이나 string, substring등)을 찾아내는 작업을 일컫는다. Perl에서의 pattern은 '정규 표현식'(regular expression)으로 나타낼 수 있다. 다음 소단락들을 통해 regular expression을 익혀, 진정한 Perl 프로그래밍 실력을 쌓도록 하자.
1) 정규 표현식(regular expression)
다음은 regular expression에서 사용되는 기호들의 의미를 정리한 표이다. Perl에서의 pattern matching은 regular expression을 사용할 수 있으므로 확실하게 익혀두는 것이 바람직하다.
| . | newline을 제외한 임의의 한 글자 |
| [a-z0-9] | a-z까지의 영문자와 숫자 중의 한 글자 |
| [^a-z0-9] | a-z까지의 영문자와 숫자가 아닌 한 글자 |
| \a | Alarm, beep |
| \d | 10진수 정수 한 글자, [0-9] |
| \D | 10진수 정수가 아닌 한 글자, [^0-9] |
| \w | 영문자 또는 숫자, _(underline) 중의 한 글자, [a-zA-Z0-9_] |
| \W | \w가 아닌 한 글자, [^a-zA-Z0-9_] |
| \s | 공백문자(whitespace) 한 글자 (space, tab, newline ...) |
| \S | \s가 아닌 한 글자 |
| \n | newline |
| \r | carriage return |
| \t | tab |
| \f | formfeed |
| \b | []내부에서 사용될 경우 backspace |
| \0, \000 | null character |
| \nnn | nnn이라는 8진수의 값을 가지는 ASCII 한 글자 |
| \xnn | nn이라는 16진수의 값을 가지는 ASCII 한 글자 |
| \cX | Ctrl+X에 해당하는 한 글자 |
| \metachar | \|, \*, \\, \(, \), \[, \{, \^, \$, \+, \?, \.와 같이 표현되며 |, *, \, (, ), [, {, ^, $, +, ?, .의 의미를 가지는 한 글자 |
| (abc) | 뒤에 가서 참조될(backreference) abc라는 문자열 |
| \1 | 첫 번째 참조 문자열, open parenthesis, '('에 의해 순서가 결정됨 |
| \2 | 두 번째 참조 문자열 |
| \n | n번째 참조 문자열, 10이상일 경우 backreference될 문자열이 없으면, 8진수 값의 ASCII 한 글자의 의미를 가질 수 있다. |
| x? | x가 나오지 않거나 1번 나오는 경우 |
| x* | x가 0번 이상 반복되는 문자열 |
| x+ | x가 1번 이상 반복되는 문자열 |
| x{m,n} | x가 m번 이상, n번 미만으로 나오는 문자열 |
| x{m,} | x가 m번 이상 나오는 문자열 |
| x{m} | x가 m번 나오는 문자열 |
| abc | a와 b와 c가 연속으로 붙어서 나오는 문자열 |
| abc|def|ghi | 문자열 abc, def, ghi 중의 하나에 해당되는 경우 |
다음은 크기가 없는, 지정된 위치가 일치하도록 제시할 수 있는 위치 표시 조건(assertion)들을 나열한 표이다.
| \b | []바깥에서 \w와 \W가 서로 바뀌고 있는 word boundary를 의미함 |
| \B | \b가 아닌 경우 |
| \A | string의 처음 위치 |
| \Z | string의 마지막 위치 |
| \G | 마지막으로 m//g에 의해 match가 된 위치 |
| ^ | string의 가장 처음 위치 표시로 /m modifier가 있으면 line의 처음을 의미한다. |
| $ | string의 가장 마지막 위치 표시로 /m modifier가 있으면 line의 끝을 의미한다. |
| (?=...) | ...위치에 놓일 문자열이 매치 된다는 조건 |
| (?!...) | ...위치에 놓일 문자열이 매치 되지 않는다는 조건 |
다음 예문을 가지고 regular expression으로 pattern matching을 하는 간단한 예를 선보이기로 한다. 예문은 각 줄 끝마다 newline이 붙어있는 것으로 가정한다.
In France a man who has ruined himself for women is generally regarded
with sympathy and admiration; there is a feeling that it was worth while,
and the man who has done it feels even a certain pride in the fact; in
England he will be thought and will think himself a damned fool. That is
why Antony and Cleopatra has always been the least popular of Shakespeare's
greater plays.
/France/; # 1번째 줄
/(women|there|That) is/; # 1, 2, 4번째 줄
/\we{2}\w/; # feel과 been, 3, 5번째 줄
/is$/; # 4번째 줄
/^England/; # 4번째 줄
if (/Engl(\w+)/) {
print "Engl$1"; # English, England
}
print if /the/; # there, the, the, 2, 3, 5번째 줄
print if /\bthe\b/; # the, the, 3, 5번째 줄
print if /man|women/; # man, man, 1, 3번째 줄
if ( /(feel(s|ing))/ ) {
print $1; # feeling, feels, 2, 3번째 줄
}
if (/([A-Z]([a-z][a-z]+))/) {
print $2; # rance, ngland, ntony
}
주목할 것은 /man|women/에서 women이라는 단어가 단락 내에 존재함에도 불구하고 match가 일어나지는 않는다는 것이다. 자세한 이유는 modifier에 관한 설명을 참조하도록 하자. 다음은 단순한 기호들의 나열 같아서 약간 더 어려울 것 같은 예제를 골라보았다.
(0|0x)\d*\s\1\d* # 0x1234 0x4321같은 16진수 두 개에서 match된다.
/.*foo/ # foo로 끝나는 단어에서 match된다.
/^(\d+\.?\d*|\.\d+)$/; # 올바른 소수표현에서 match가 일어난다.
다음은 the를 관사로 가지는 명사들을 모두 출력하는 예제 프로그램이다.
while (<>) {
if (/\bthe\b\s+(\w+)/g) {
print "$1\n";
}
}
2) match, substitute, translate
match는 지정되어 있는 regular expression으로 표현 가능한 substring이 존재하는가의 여부를 결정할 때 사용하는 연산이고, m이 그 operator이다. 이와 비슷한 종류의 연산자로서, regular expression으로 표현된 substring을 치환(substitute)해주는 s///연산자와 표현식의 각 글자를 해석(translate)하고 변환해주는 tr///연산자가 있다. 다음은 각 연산자들의 형식이다.
연산자//modifier 또는 연산자///modifier
문장 내에서 흔히 실수하기 쉬운, teh라고 잘못 친 부분을 the로 바꾸어 주는 연산을 다음과 같이 구현할 수 있다.
s/\b(teh)\b/the/g;
g가 바로 modifier인데, 각 연산마다 사용 가능한 modifier의 종류가 다르다.
m/PATTERN/gimosx
/PATTERN/gimosx
match연산자는 흔히 생략해서 사용하였다. 앞에서 익혔던 패턴매치에서는 m연산자를 일부러 사용하지 않았던 것이다.
| modifier | 의미 |
| g | global, 문장 내에서 여러 번 match가 일어날 때마다 |
| i | case-insensitive, 대소문자 구분 없이 |
| m | multiple-line, 여러 line을 한꺼번에 사용함 |
| o | compile once, compile시에 pattern을 딱 한번 해석함 |
| s | single-line, string을 한 line으로 가정함 |
| v | Extended Regular expression을 사용함 |
다음의 두 예제를 비교해 보도록 하자.
if (/(man|women)/g) {
print $1;
}
if (/(man|women)/) {
print $1;
}
첫 번째 예제의 결과는 man, women, man이 되지만, 두 번째 예제의 결과는 man, man뿐이다. 결과가 달라지는 이유는 g modifier때문인데, 한 문장에 여러 번 match가 일어날 경우, 매번 처리를 할 것인지(g modifier사용), 아니면 다음 문장으로 넘어갈 것인지를 modifier를 보고 결정하기 때문이다.
substitute연산자는 생략가능하지도, 동의어 연산자도 존재하지도 않는다. 그러나 pattern match류의 연산자들 중에서 가장 빈번하게 사용되는 연산자이다.
s/PATTERN/REPLACEMENT/egimosx
| e | expression, REPLACEMENT부분에도 expression을 사용함 |
| g | 문장 내에서 match가 일어날 때마다 매번 처리 |
| i | 대소문자 구분 없이 |
| m | multi-line mode |
| o | 단 한번만 compile함 |
| s | single-line mode |
| x | Extended regular expression을 사용함 |
다음은 substitute 연산자를 사용한 예이다.
s/^([^ ]+) +([^ ]+)/$2 $1/; # 두 단어의 순서를 바꾸어준다.
s/red/green/g; # 문장 내의 모든 red를 green으로 대치한다.
s/\bt(e)(h)\b/t$1$2/g; # teh를 the로 고쳐준다. $1과 $2는 backreference
s/(\d)(\d\)\.(\d+)/$1\.$2$3/; # 42.9을 4.29로 바꾸는 식으로 소수점을 옮긴다.
translate연산은 위의 두 연산과는 약간 다르다. 첫 번째로는 string에 대한 조작이 아니라 표현식 내의 글자 하나 하나에 대한 해석과 변환에 관련된 조작이고, 두 번째로는 표현식에는 regular expression을 사용하지 않는다는 점이다.
tr/SEARCHLIST/REPLACEMENT/cds;
y/SEARCHLIST/REPLACEMENT/cds;
y는 tr의 동의어로 사용된다. SEARCHLIST에 나오는 글자들은 REPLACEMENT에 나오는 글자들과 n대 n 또는 n대 1로 대응이 되어 변환이 이루어진다. 다음의 예제들을 참고하여 이해하도록 하자.
tr/ABC/XYZ/;
A는 X로, B는 Y로, C는 Z로 바뀐다. 그러므로 ABVWSDC라는 문자열은 XYVWSDZ로 바뀌게 되는 것이다.
y/0-9//;
tr [A-Z] [a-z];
문자열 내의 숫자는 모두 제거된다. 문자열 ABC0123DEF는 ABCDEF로 바뀌게 된다. 모든 대문자가 소문자로 바뀐다. "I am a BoY"는 "i am a boy"가 될 것이다.
translate연산이 위의 두 연산과 많이 다른 만큼, modifier 또한 크게 다른 의미를 가진다.
| c | complement, SEARCHLIST에 없는 글자가 처리된다. |
| d | delete, 발견되었지만 처리되지 않은 글자를 지운다. |
| s | squash, 동일하게 반복된 글자를 빼낸다. |
다음은 modifier를 사용한 translate연산의 예이다.
tr/a-zA-Z/ /c; # 알파벳이 아닌 글자가 space로 바뀐다.
tr/a-zA-Z//s; # "I've been a fool."이 "I've ben a fol."로 바뀐다.
Perl 4까지는 multi-line/single-line mode를 사용하기 위해 global special variable 중의 $*를 이용하였다. pattern match 연산을 하기 전에 $*을 1로, $" = ""로 지정하면 multi-line mode로 바꿀 수 있었다. Perl 5의 global special variable에 $*가 언급되지 않는 것으로 미루어보아, 이 방법 대신에 위에서 밝힌 바와 같이 modifier를 사용하는 방법이 안전할 것이다.
3) 문자열 pattern 조작
문자열 변수에 대해서 pattern match 관련 연산을 하는 방법은 =~(pattern binding operator)연산자를 사용하는 것이다. 이 연산자는 지정된 변수를 pattern에 대해 match시켜보거나 substitute하거나 translate하도록 해준다. 마치 대입연산자 ~=와 비슷하게 보이지만 대입연산자로 사용될 수 없는 연산자이다.
($a = $b) =~ s/red/green/;
$cnt = tr/*/*/;
$cnt = $sky =~ tr/*/*/;
첫 번째 문장에서 괄호는 생략가능한데, 우선은 $b에 대해서 substitute연산이 일어나고 그 결과 값이 $a에 들어가게 된다. 다시 말해서 문자열 중에서 red가 모두 green으로 바뀌어진 문자열 전체가 $a에 대입되는 것이다. 두 번째 문장에서 tr연산자는 default input string에서 '*' character를 찾아서('*'는 interpolation과 관련 없다.) 그 개수를 세어준다.
vector형 자료구조인 배열이나 해시에 대해서는 pattern match를 할 수가 없고, 원소를 하나씩 꺼내어 그 scalar형 원소에 대해서 작업을 반복할 수 있다. 다음 예제에서 나오는 scalar연산은 vector형 변수의 원소의 수를 알려준다.
@list = (1, 2, 3, 4, 5, 6, 7);
for ($i = 0; $i < scalar(@list); $i++) {
$list[$i] =~ s/3/9/g;
}
print @list;
file에 대해서 pattern match 관련작업을 하는 것은 vector형 변수에 대해서 작업하는 것과 마찬가지의 방법이 필요하다. 한 문장씩 읽어 들여서 그 문장을 변수에 저장하고 그 변수에 pattern match 연산을 하는 것이다.
open(FILE1, "testfile.1") || die "Can't open such a file!\n";
while () {
s/\r//g;
print;
}
DOS상에서 만들어진 파일은 리턴 키를 입력할 때마다 \r과 \n이 파일에 쓰여지는데 반해, Unix에서 리턴 키는 \n만을 써줄 뿐이다. 그래서 DOS파일을 Unix에 옮겨오는 경우, ^M이라는 이상한 글자(실제로는 \r이 터미널에 보이는 형태일 뿐이다.)가 매 줄 끝마다 보이게 된다. 이러한 글자를 제거해준 결과를 보여주는 예제를 제시한 것이다. Perl script로 쓰게 되면 더 간단하게 사용할 수 있는데, 다음의 코드를 d2u.pl이라는 이름으로 작성한 후에, 실행 가능하게 permission mode를 바꾸어주고(chmod a+x d2u.pl) 도스파일에 대해서 실행(d2u.pl dostext.txt)하여 보자.
#!/usr/local/bin/perl -pi
s/\r//g;
작성자 : 조영일, 서울대학교 전산과학과